For me, the fun in writing a disassembler drops off sharply after the first. It becomes just plain tedious. For our thumb2 disassembler, we looked for a more interesting way to construct one, and found benefits beyond reducing boredom: serviceability and accuracy.
Spoiler, what we’re doing is generating a disassembler from the ARM specification (spec) itself. This involves some intermediate steps and parsing, which we discuss below.
Step 1: Easily Parsable Spec
The idea is to take the very verbose specification and convert it to easily processed plain text. We avoided parsing the PDF itself due to time constraints and the relative immutability of the PDF in case corrections will need to be made.
We consider just the instruction encoding section of the spec, specifically the table and instruction entries. A sample portion of a table entry follows:
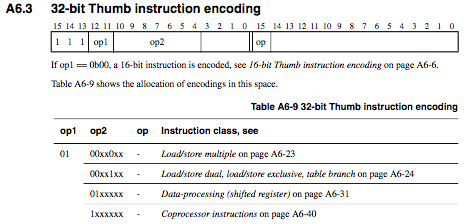
The text form of this is:
thumb32:
extract32 111,op1.2,op2.7,xxxx,op.1
on op1,op2,op
01,00xx0xx,x load_store_multiple
01,00xx1xx,x load_store_dual_exclusive_table_branch
01,01xxxxx,x data_processing_shifted_register
01,1xxxxxx,x coprocessor_instructions
Note that the text is nearly identical to the spec, but tweaked slightly in form to be more easily consumed by the code generator. The thumb32: names the table. The extract32 command declares what constant bits and variable bits the disassembler might find. And finally the patterns like 01,00xx0xx,x tell where the disassembler should go next should the pattern match.
The travel between tables eventually stops at an instruction entry that looks like this:

And the text form is:
sxtab16:
Encoding T1 ARMv6T2, ARMv7
fmt SXTAB16<c> <Rd>,<Rn>,<Rm>{,<rotation>}
extract32 11111,010,0,010,Rn.4,1111,Rd.4,1,(0),rotate.2,Rm.4
pcode if Rn == '1111' then SEE SXTB16; \
d = UInt(Rd); \
n = UInt(Rn); \
m = UInt(Rm); \
rotation = UInt(rotate:'000'); \
if BadReg(d) || n == 13 || BadReg(m) then UNPREDICTABLE;
Here the sxtab16: names the instruction. The code generator discerns between table entries and instruction entries by seeing if an extract or Encoding statement follows. Note that the pseudocode (pcode) specifies important details that we generate code for too.
Aside: A Graph Perspective
The initial table serves as the root node. The tables to which this root table refers are its branch nodes. Those may branch also, and and so on. The instruction entries are the terminal nodes.
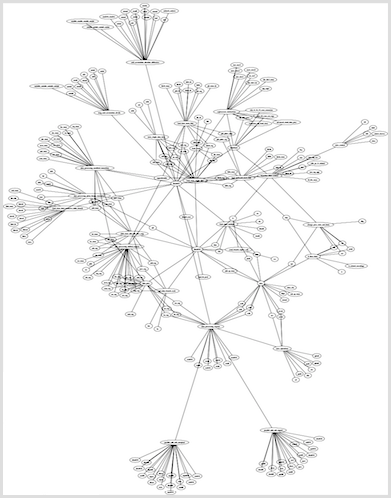
There are almost 300 nodes total, representing the tables and the instructions. Here is a closer zoom where some of the named nodes are readable:
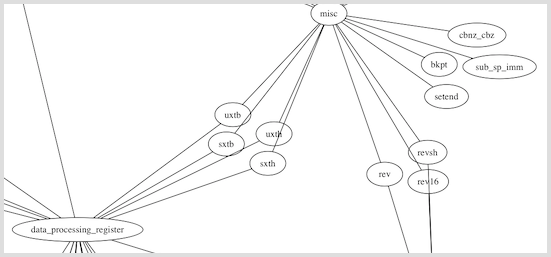
A fun perspective to adopt is that the disassembler is a driver on this road network and the instruction words are the directions. The driver first considers the bits that will direct coarse grain turns, toward a cardinal direction or neighborhood. Later, additional bits are considered, directing fine grain turns to the right street and house. An undefined instruction is simply a bad address.
Step 2: Parsing Pcode, Generating
The pseudocode can contain many things, like certain conditions under which an instruction is undefined or when to consult another table. Here is the pseudocode for sxtab16:
pcode if Rn == '1111' then SEE SXTB16;
d = UInt(Rd);
n = UInt(Rn);
m = UInt(Rm);
rotation = UInt(rotate:'000');
if BadReg(d) || n == 13 || BadReg(m) then UNPREDICTABLE;
Where UInt() is defined in the spec and rotate was a sub region of bits within the instruction word.
No matter how many times I make a recursive descent parser, I blow a lot of time looking stuff up and doing LALR conversions and stuff so this time I outsourced to Grako parser generator. A starting portion of our grammer is:
start = statement [';'] $;
statement = 'if' expr0 'then' statement |
"UNPREDICTABLE" |
"UNDEFINED" |
"NOT_PERMITTED" |
"NOP" | "nop" |
"SEE" whatever |
tuple '=' expr0 |
expr0 '=' expr0;
tuple = '(' ('-'|expr0) { ',' ('-'|expr0) }+ ')';
...
The generated code is nearly a line by line translation, and can use variable names like Rn that were named earlier in the bit regions of the instruction word:
/* pcode: if Rn == '1111' then SEE SXTB16 */
if((res->elements["Rn"]) == (0xF)) { /* wipe state, transfer to sxtb16 */ }
/* pcode: d = UInt(Rd) */
res->elements["d"] = (unsigned int)(res->elements["Rd"]);
/* pcode: n = UInt(Rn) */
res->elements["n"] = (unsigned int)(res->elements["Rn"]);
/* pcode: m = UInt(Rm) */
res->elements["m"] = (unsigned int)(res->elements["Rm"]);
/* pcode: rotation = UInt(rotate:'000') */
res->elements["rotation"] = (unsigned int)((res->elements["rotate"]<<3)|(0x0));
/* pcode: if BadReg(d) || n == 13 || BadReg(m) then UNPREDICTABLE */
if(((BadReg(res->elements["d"])) || ((res->elements["n"]) == (13))) || \
(BadReg(res->elements["m"]))) { res->flags |= FLAG_UNPREDICTABLE; }
This is a deliberately simple example, where the code for wiping state and transferring is omitted and there are redundant storages within the disassembler result res. BadReg() is a c++ function defined in the disassembler like the spec says, and res->flags speaks for itself.
Step 3: Travelling the Graph, Generating Table Code
Referring back to the the 32-bit Thumb instruction encoding table from step 1, the generated code is very straightforward, masking off the named fields and then testing them for values that will lead the disassembler to the next table:
thumb32(struct decomp_request *req, struct decomp_result *res)
{
int rc = -1;
uint32_t instr = ((*(uint16_t *)req->instrStream)<<16) | \
*(uint16_t *)(req->instrStream + 2);
uint32_t op1 = (instr & 0x18000000)>>27;
uint32_t op2 = (instr & 0x7F00000)>>20;
uint32_t op = (instr & 0x8000)>>15;
if(((op1 & 0x3)==0x1) && ((op2 & 0x64)==0x0) && 1)
return load_store_multiple(req, res);
if(((op1 & 0x3)==0x1) && ((op2 & 0x64)==0x4) && 1)
return load_store_dual_exclusive_table_branch(req, res);
if(((op1 & 0x3)==0x3) && ((op2 & 0x70)==0x20) && 1)
return data_processing_register(req, res);
if(((op1 & 0x3)==0x1) && ((op2 & 0x40)==0x40) && 1)
return coprocessor_instructions(req, res);
...
res->status |= STATUS_UNDEFINED;
return 0;
}
Step 4: Ending the Trip, Generating Instruction Code
Returning to our sxtab16 example, the extract statement is:
extract32 11111,010,0,010,1111,1111,Rd.4,1,(0),rotate.2,Rm.4
There are many constant bits, followed by a 4-bit field named “Rd”, followed by a 1, followed by an expected 0 (instruction is unpredictable otherwise), followed by a 2-bit field named “rotate”, followed by a 4 bit field named “Rm”. The code is not too surprising:
if(((instr & 0xFFF0F080)==0xFA20F080)) {
res->instrSize = 32;
if(!((instr & 0x40)==0x0)) {
res->flags |= FLAG_UNPREDICTABLE;
}
if(!(req->arch & ARCH_ARMv6T2) && !(req->arch & ARCH_ARMv7)) {
res->status |= STATUS_ARCH_UNSUPPORTED;
}
res->elements["c"] = COND_AL;
res->elements["Rn"] = (instr & 0xF0000)>>16;
char Rn_width = 4;
res->elements["Rd"] = (instr & 0xF00)>>8;
char Rd_width = 4;
res->elements["rotate"] = (instr & 0x30)>>4;
char rotate_width = 2;
res->elements["Rm"] = instr & 0xF;
char Rm_width = 4;
res->formats.push_back("SXTAB16<c> <Rd>,<Rn>,<Rm>{,<rotation>}");
res->mnem = "SXTAB16";
The outer if masks and checks the constant bits given in the pattern. The next if checks for that expected (0) bit and marks the result unpredictable if not found. If the disassembler request “req” does not name one of the supported architectures, we still give our best effort but mark the disassembly result “res” as unsupported. The Rn, Rd, Rm, and rotate fields are extracted with bit masking and even the spec supplied format for the disassembly is saved. You may notice that each of the variables in the format will be looked up in res->elements when a string is finally produced.
Conclusion
This short tour was written on a POC version that still contained many inefficencies, but shows the main ideas. The version released in Binary Ninja runs hundreds of times faster as it was heavily optimized though it makes for less easy reading!
On the issue of serviceability, to correct this disassembler, changes are made in the text distilled from the specification, then the generator is run again. On the issue of accuracy, the disassembler should be as accurate as the specification. We’re happy to defer to ARM’s documents and blame them if something doesn’t turn out right. :)
A hypothetical debate about the merits of a human written disassembler versus this generated one is fun to ponder. The human surely would have found clever ways to decide between decoding paths, or come up with optimizations like table lookups when the instruction allowed. This generated one, however, has long lines of brute bit masking and testing and repetitive generated code. Certainly the human could have produced a smaller disassembler. But if size is not nearly the concern it was in years past, and if the compiler optimizes well, is it worth boring a human for the weeks or months required to implement a large specification?