Malware authors often use many anti-analysis techniques to prevent reverse engineering tools from working against their binaries. One of the main goals of Binary Ninja is to turn manual analysis problems into small scripts to automatically solve such problems. Below, we’ll show how to automatically remove a class of anti-analysis automatically with Binary Ninja’s API by leveraging our architecture agnostic Medium Level IL (MLIL), data flow, and patching.
What are opaque predicates?
Opaque predicates are a series of instructions which always evaluate to the same boolean result, like this:

The zero flag is set by the xor eax, eax instruction. If the zero flag is NOT set, the next instruction jumps. Such opaque predicates can be constructed from arbitrarily long sequences of instruction which makes identification much more difficult.
They’re particularly effective at directing a static disassembly tool to analyze invalid sections of code, or to waste large amounts of time analyzing functions that will never actually run. Even in simple cases, they can waste an analyst’s time by forcing him or her to reason about code that will not be triggered.
Let’s take a look at an opaque predicate instruction sequence produced by SCC that is a bit more complicated:
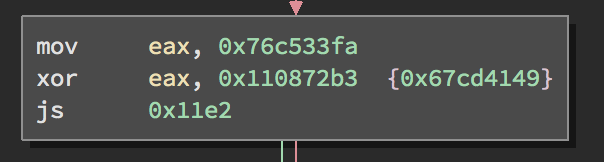
It’s harder to intuitively recognize the result, and we’re just getting started. The instruction sequences get a lot more complicated. Fortunately, as we’ll show, they can be handled in a generic, cross-architecture manner.
Medium Level IL to the Rescue
To understand the effect on the flags for the above instruction sequence, you could pop open python (always available in Binary Ninja via the ` hotkey) and do some hex math to see if the sign flag will change. But that would take work. It’s easier to switch over to the MLIL view in the options menu in the lower right corner.
MLIL transforms the assembly into an architecture-agnostic intermediate language; a pseudo decompilation of sorts. It’s not a true decompiler meant to look like C, but it does replace all architecture-specific sequences with generic instructions that are much easier to understand. MLIL also abstracts stack variables and registers to C-like variables (though it will use register names as variable names for convenience). Also, many equations are shortened to a simpler form. Let’s compare the assembly from earlier with its format in MLIL:
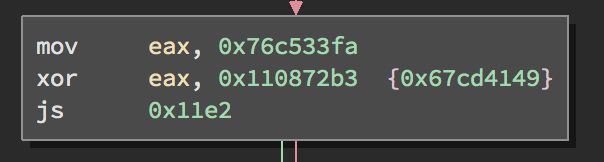

Lets explore the differences. First we’ll break down the new instruction.
if (<condition>) then
<true-case MLIL address> @ <true-case Assembly address>
else
<false-case MLIL address> @ <false-case Assembly address>s<refers to a signed comparison186 @ 0x11e2is the true branch187 @ 0x1168is the false branch186and187are the MLIL addresses0x11e2and0x1168are the assembly addresses
The flag setting (happening implicitly in the xor instruction) has been converted into a signed comparison. Additionally, the mathematical operations have been simplified to a constant result that they calculate. All this results in a very obvious comparison which will always be false.
Built-in Patching
Now that we know the branch will always be false we can do something about it. Binary Ninja has some pretty convenient built-in features for patching branches. Right click the instruction and select Patch->Never Branch.

This rewrites the binary to change the underlying instruction to a series of nop instructions. Analysis is automatically re-run and delivers a much cleaner graph.
Let’s Automate
But what if our binary is chock-full of such instructions? It would be a pain to have to manually right click and patch each instruction. We can do better by writing a simple script to automate the whole process (well, simple when we’ve got an IL and static dataflow.) Here’s the generic algorithm:
- Iterate all the MLIL instructions
- Find the
MLIL_IFinstructions - Check if the condition is a constant and apply the patches
- Go to step 1 until no patches are found
For the impatient here is link to the code implementing the above algorithm. OpaquePredicatePatcher Please note, the script requires a recent public dev channel build version 1.1.945 or later. This version is available to all customers with active support licenses. Now let’s explore each of the steps in our script.
Iterating MLIL Instructions
First a lesson in how Binary Ninja organizes functions, basic blocks and instructions.
- All Function objects are contained within a BinaryView object.
- All BasicBlock objects are contained within a Function.
- All instruction objects are contained within BasicBlock objects.
For the purposes of this blog post we’ll assume you already know how to acquire a BinaryView instance. Canonically we refer to a BinaryView instance as bv. For our purposes (since we don’t care about functions or basic blocks, just the instructions) we can use a convenience function which is part of the BinaryView object: mlil_instructions. This is a generator that yields all instructions contained within all functions.
for i in bv.mlil_instructions:
print hex(i.address), iFinding the MLIL_IF instructions
To query the type of instruction, we look at the instruction operation property. The operation is a value from the MediumLevelILOperation enumeration. We can either check for these or just filter the mlil_instructions:
for i in bv.mlil_instructions:
if i.operation == MediumLevelILOperation.MLIL_IF:
# found a MLIL_IFCheck the condition
Here comes the magic. In addition to performing constant math for you, Binary Ninja also determines the result of constant comparisons. MLIL is tree-based so the MLIL_IF instruction has three child expressions that can be queried: condition, true, and false. To discover if the condition result is constant, we obviously care about the condition expression. This can be done with i.condition.possible_values which returns a PossibleValueSet object. If the state of the PossibleValueSet is RegisterValueType.ConstantValue we know the .value property will contain a constant value. Since we are iterating over the MLIL instructions, we don’t want to do anything that will affect the analysis while in this loop. Instead of patching branches here, we simply record the branches to be patched, and then patch them once we exit the loop.
It is important to note that MLIL is a many-to-many mapping of assembly language instructions to IL instructions. Thus, multiple IL instructions could correspond to a single assembly instruction (or vice-versa). For example, conditional x86 instructions (any of the instructions that set registers with flag values, cmov, and others) are often expanded into multiple IL instructions. Thus, it’s important that we check if it’s safe to patch using is_never_branch_patch_available or is_always_branch_patch_available prior to calling never_branch or always_branch.
Repeat until no patches are found
When we remove opaque predicates we also remove additional false constraints which clean up analysis. Frequently, it takes a few rounds of patching before we produce a binary without any opaque predicates. So we simply keep looping over the algorithm until we find no opaque predicates.
Limitations
This technique is not the be-all-end-all of opaque predicate elimination. A large number of obfuscations could be constructed to throw our analysis off. Here are a few examples:
Variables in writable segments
Binary Ninja relies on the concept of section semantics to determine if it can calculate dataflow. If a binary uses opaque predicates which originate from sections like the .bss, we can’t guarantee these values haven’t been changed and thus we can’t propagate.
Binary Ninja does this because writable code can be changed during execution of the binary. From an analysis perspective, it is not safe to assume the data in those sections has not changed. Obfuscator LLVM’s Bogus Control Flow feature implements opaque predicates using this method. There are several workarounds to automate cleaning up that particular implementation. One would be to re-write all of the loads from the .bss with mov $reg, 0.
Loops
Loop analysis is difficult because of the halting problem. If a binary uses loops to calculate the result used in a conditional comparison, we won’t have any luck patching the branch.
Instruction involving unlifted instructions
Binary Ninja conducts all analysis upon the Binary Ninja Intermediate Language (BNIL). If an instruction hasn’t been translated yet, and a comparison result is dependent on that instruction, the analysis will fail.
Unmodeled Data Sources
Because Binary Ninja can only track dataflow from known sources, any source of data which comes from outside the binary (e.g. file/network reads, results from calling imported functions or system calls) will not propagate a dataflow.
Results
The results speak for themselves. Below is function with a huge number of opaque predicates, which renders the graph nearly unreadable.
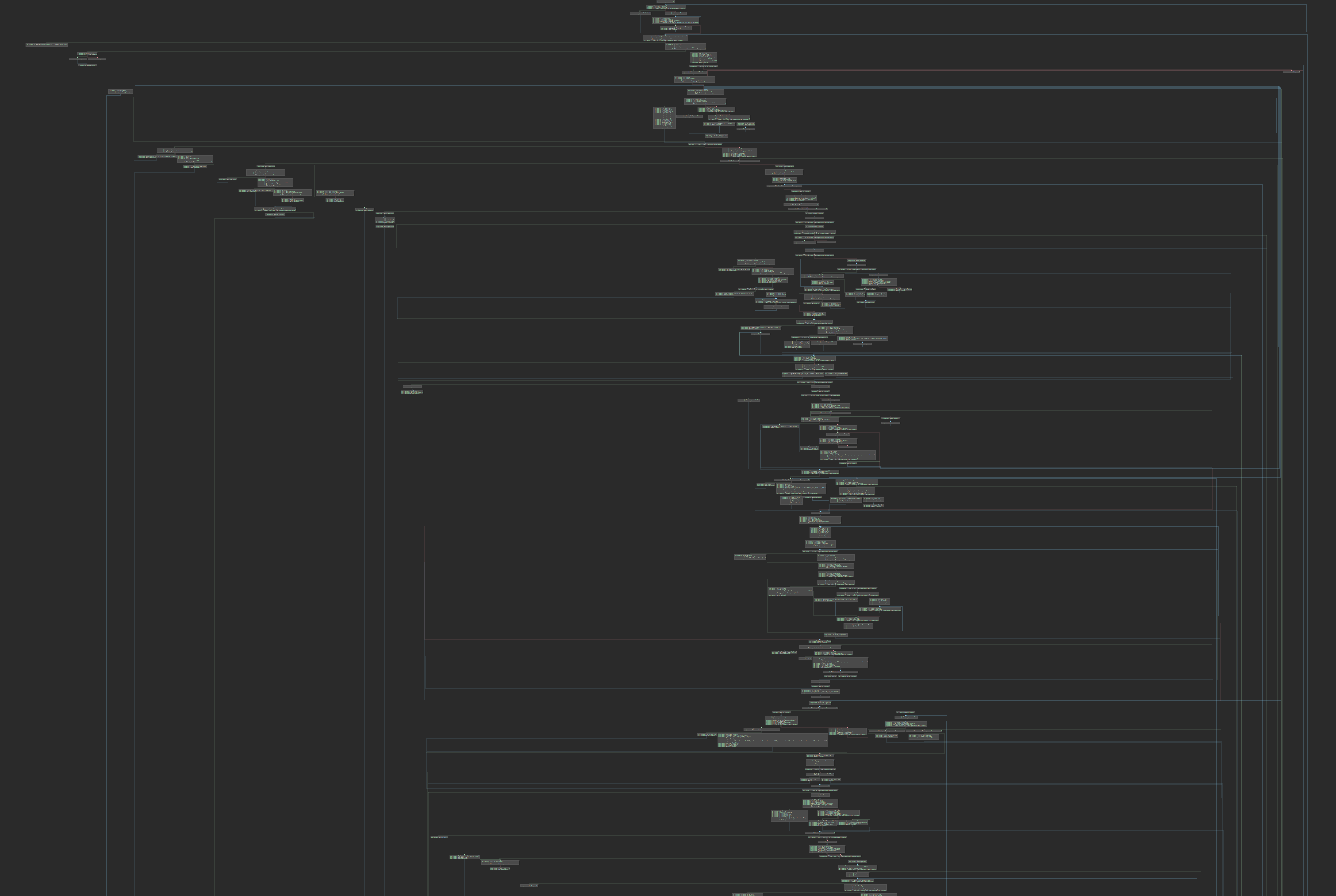
After running the OpaquePredicatePatcher, the graph is much nicer to read, especially in MLIL view which has additionally removed much of the code used to calculate the opaque predicates.
Try it out
Everything you need to play along at home is uploaded to the OpaquePredicatePatcher github repository, including:
- Plugin Source
- Sample Binary Source
- Sample Compiled Binary
Prior Work
Many other projects have attempted to automatically clean up obfuscated binaries. We think that Binary Ninja is unique for leveraging our BNIL which is included on all supported architectures automatically and doesn’t require additional analysis components. With very little effort it works out of the box.
That said, some great work has been done by:
- Quarkslab: Deobfuscation: recovering an OLLVM-protected program
- Control Flow Deobfuscation via Abstract Interpretation
- Jakstab: The Jakstab static analysis platform for binaries
Questions or Comments?
If you have questions or comments about this work we’d love to hear it. Please either leave your comment below, join our Slack, or contact us on twitter @vector35.