Function start detection in stripped binaries is an undecidable problem. This should be no surprise. Many problems in the program analysis domain fall into this category. Add to that the numerous types of CPU architectures, compilers, programming languages, application binary interfaces (ABIs), etc. and you’re left with an interesting, multifaceted, hard problem. Accurate detection of both function starts and the low-level basic blocks is often the first step in program analysis. Performing this task accurately is critical. These foundational analysis artifacts are often the starting point for many automated analysis tools.
Being undecidable, there is no single algorithm to identify all function starts across the wide variety of program binaries. Among some of the approaches enlisted to try and solve this problem are machine learning algorithms (e.g. Byteweight and Neural Networks) which use signature based pattern recognition. At first glance the results of these learners look promising but they are often biased to their training set.
Other approaches to function detection (e.g. Nucleus and Function Interface Analysis) are more sensible. Their research is focused on control-flow, data-flow, and function interface analysis rather than signature detection. Yet, these solutions fall short of addressing the entire problem domain across architectures in a generalized way.
For example, the Nucleus approach can be improved upon since it relies on heuristics to handle indirect control flow. What’s wrong with heuristics? They must be updated constantly for the latest compiler constructs, and can frequently produce invalid results, especially in highly optimized binaries. Even today, many tools rely on heuristics. That’s a dilemma. Even though they solve a specific problem really well, they rarely generalize to solve an entire class of problems.
Enter the Ninja
Binary Ninja is an extensible reverse engineering tool that provides a generalized, architecture-agnostic approach to program analysis. Therefore, one of our goals is to develop a function detection algorithm that comprises the best techniques available while being architecture-agnostic. We therefore intentionally overlook signature matching and heuristics as primary methods to provide this capability (though do not discount them entirely).
Carving Binary Spaces with Confidence
Given the multifaceted nature of function detection in stripped binaries, it is common to apply multiple strategies over multiple analysis passes. The order of those strategies is driven by the desire to achieve positive function identification with the highest degree of confidence first, as this should reduce the scope, complexity, and possibility for mistakes in later analysis stages. This is important. Mistakes early in the binary analysis process can degrade the results of higher-level analysis later. The search space for each analysis phase is the current set of unknown regions in the binary that are not tagged as code or data. After each phase, the search space shrinks by tagging regions as code and/or data. Currently, Binary Ninja performs analysis in four distinct phases:
- Recursive Descent
- Call Target Analysis
- Control Flow Graph (CFG) Analysis
- Tail Call Analysis
After analysis is complete, the desired result is a binary that is annotated in a similar way to a binary with full symbol information, or even better.
Recursive Descent
In earlier versions of Binary Ninja, automatic function detection is limited to our recursive descent algorithm. This algorithm analyzes the control flow from the defined entry point(s) and attempts to follow all code paths. Since the algorithm is based on control flow from a well-defined entry point it is inherently proficient at differentiating between code and data. A unique ability of Binary Ninja’s recursive descent algorithm is the ability to perform multi-threaded* analysis during this phase.
Results from recursive descent are highly accurate, but there are several limitations: handling indirect control flow constructs, disconnected functions, and tail call function identification. We present our solutions to these challenges later.
* Note that multi-threaded analysis is only available in Binary Ninja Commercial
Jump Table Inference with Generic Value-Set Analysis
Many tools approach indirect dataflow resolution with heuristics. Even some of the newest binary analysis tools still rely on heuristics to detect instruction sequences and patterns in order to locate jump tables. The problem is that every time a new compiler/optimization/architecture is released, the compilers’ indirect control flow idioms could change, undercutting the effectiveness of the once-sufficient heuristic. This creates a big problem for most types of function-detection algorithms. Broken jump tables negatively impact function detection because each of the indirect jump targets can appear to be a potential function as they are valid native blocks of instructions. Depending on the architecture, well-connected basic blocks may even appear within the jump table itself. Attempting to filter out all of these types of candidate functions is not only a tedious, but difficult task.
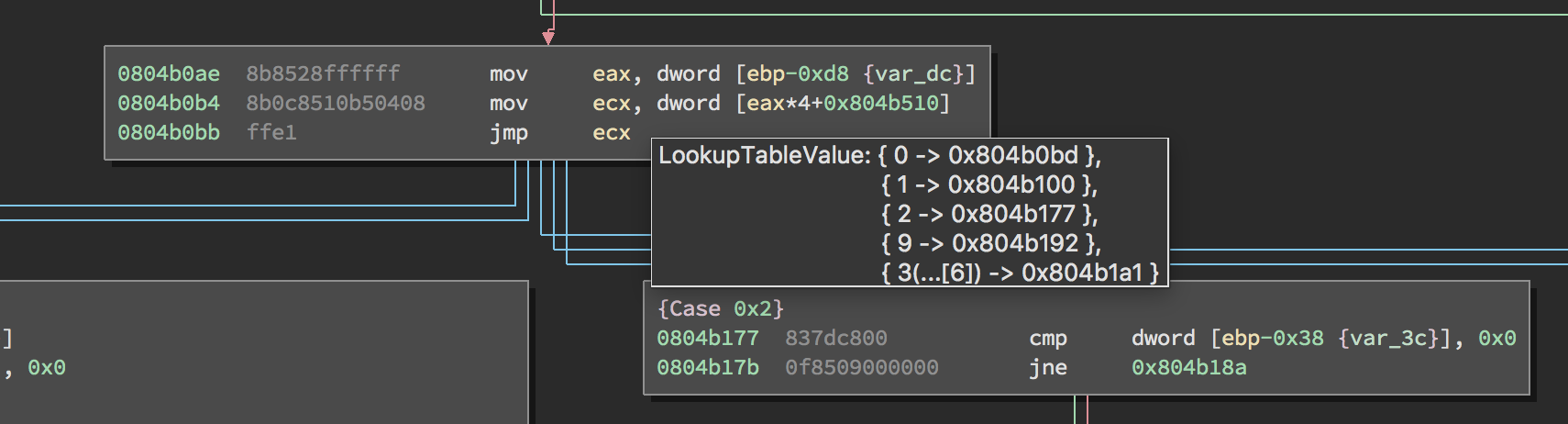 Table Value on Hover - Figure 1
Table Value on Hover - Figure 1
Since adding heuristics to solve a problem can be an eternal cycle of misery, Binary Ninja provides a practical implementation of generic value-set analysis. Value-set analysis is in the domain of abstract interpretation. Essentially, it is a method to interpret the semantics of low-level CPU instructions and track the possible value of variables and/or registers at each instruction point. The value represents an approximation that is path sensitive. Given this capability it becomes trivial to query the possible values at an indirect jump-site. One example is shown in Figure 1. If the possible values represent a reasonable set of jump targets, then the recursive descent algorithm can continue. This reduces the resolution of an indirect control flow instruction idiom to a simple query via our possible value set API.
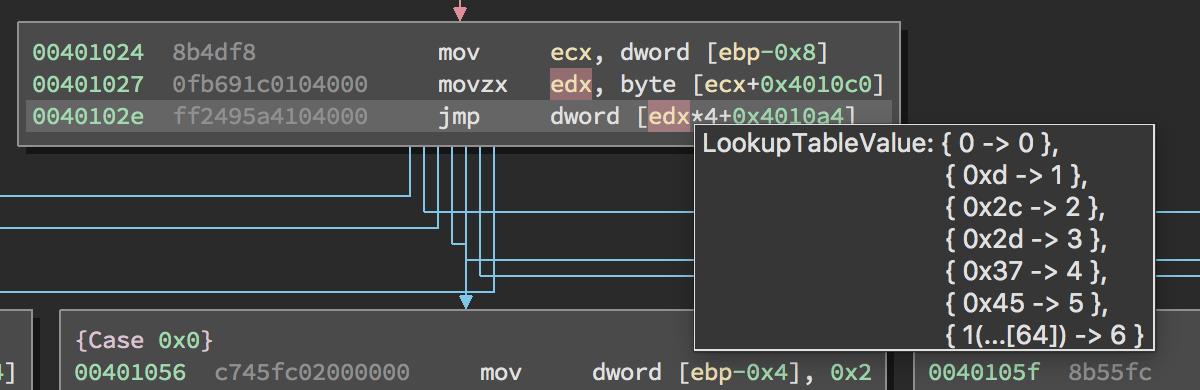 Solving jump tables with multiple levels of indirection - Figure 2
Solving jump tables with multiple levels of indirection - Figure 2
Because our value set analysis occurs within our Binary Ninja Intermediate Language (BNIL) set of abstractions, it is inherently architecture agnostic. This means that when we add a new architecture to Binary Ninja all of the existing value set analysis is automatically applied by Binary Ninja’s analysis core. The result is a lifted, clean binary ready for consumption. The next several sections describe the additional analysis phases which make up our implementation of linear sweep.
Call Target Analysis
This analysis phase sequentially disassembles the unknown regions in the search space while aggregating all potential call targets. For our purposes, a call target is the destination of a call instruction as returned from the architecture. Once complete, the call targets are ordered by the number of cross-references in descending order and handed off to the recursive descent algorithm for further analysis.
Control Flow Graph Analysis
This analysis pass is based on the Control Flow Graph (CFG) recovery technique discussed in the research paper titled Compiler-Agnostic Function Detection in Binaries (i.e. Nucleus). A key insight from this paper is that compilers typically use different control-flow constructs for interprocedural control-flow versus intraprocedural control-flow. The general algorithm for the CFG recovery is to perform a linear disassembly of the unknown regions in the search space creating basic blocks. Then connect the basic blocks into groupings and group the basic blocks based on intraprocedural control-flow constructs. The basic block groupings become candidate functions which undergo some additional analysis to find the possible entry point. For more details about CFG recovery please reference the Nucleus paper. Once we have possible entry points, we hand them off to the recursive descent algorithm to perform the heavy lifting.
Tail Call Analysis
Compilers employ tail call optimizations to reduce the overhead of adjusting the stack before and after the call to a function. This technique is typically applied when the last thing a function does before it returns is call another function. This optimization often appears as a jump to the target function. The caller stack frame is available to the target function, which may or may not require a stack frame.
Recursive traversal by itself does not detect tail call functions since a jump is simply a direct control flow that is followed by the algorithm. Note that the techniques used in the linear sweep passes described thus far attempt to find functions in areas of the binary that are not already indicated as part of a basic block or data variable.
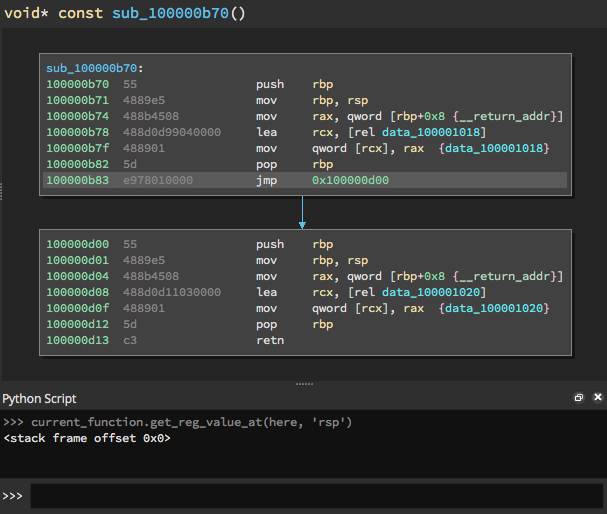 Tail call before analysis - Figure 3
Tail call before analysis - Figure 3
For Binary Ninja, we add a tail call analysis pass as the final stage of our function detection. This pass requires iterating over existing functions. Generally, if we detect a basic block that jumps before or after the current function boundary, then it is likely a tail call function. This works well for some cases, however there are other times where the tail call function is part of the current function under analysis, as shown in Figure 3. For these situations we use our static dataflow capability to query the stack frame offset at the jump site as well as in the candidate tail call function. This allows Binary Ninja to determine if the stack offset is zero and whether a particular jump site may in fact be a tail call. Figure 4 illustrates the result of Binary Ninja’s tail-call analysis, the correct identification of a tail-called function.
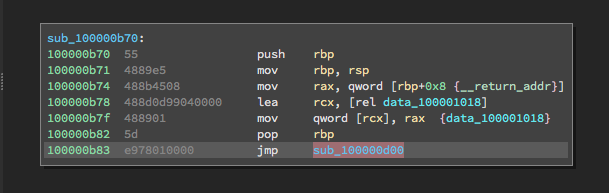 Tail call after analysis - Figure 4
Tail call after analysis - Figure 4
Evaluation
We currently evaluate and refine our function detection capability on three different data sets. These include the ByteWeight data set, a subset of binaries from the Cyber Grand Challenge (CGC) corpus of binaries, as well as our own BusyBox binaries that are cross-compiled for various architectures. For most of our results we compare Binary Ninja with Nucleus only. The reason for this is that Nucleus is readily available, and easy to set up and generate results for comparison.
The results presented below were generated with Binary Ninja 1.1.988-dev, IDA Pro Version 7.0.170914, and Nucleus (c98b48c). ByteWeight results are reposted from the original work.
Ground Truth Data
Unless otherwise noted, in each data set for all of the non-stripped ELF binaries, we generate ground truth data for function starts by parsing output from the readelf binary utility. We also exclude PLT entries or thunks as was done in prior research.
Reference the Sensitivity and Specificity article regarding statistical measures calculated in the tables below. Note the following definitions:
- True Positives (TP): identified function starts that match ground truth data
- False Positives (FP): identified function starts that do not match ground truth data
- False Negatives (FN): function starts in ground truth data that are not detected
ByteWeight Data Set
This data set consists of 2200 binaries that target both x86-32 and x86-64 architectures. 2064 of the binaries are compiled with gcc or icc across various optimization levels. The remaining 136 binaries are PEs compiled with msvc. Note that the ground truth data for the pe-x86/pe-x86-64 binaries are obtained from the original Byteweight data set. It should be noted that Nucleus never presented results for the icc compiler. We hypothesize the algorithm performance is degraded on icc due to the use of heuristics for resolving indirect control flow.
Original ByteWeight Data Set (gcc/icc/msvc)
| Binary Ninja | Byteweight | Nucleus | |
|---|---|---|---|
| Precision | 0.9734 | 0.9730 | 0.8130 |
| Recall | 0.9632 | 0.9744 | 0.9347 |
| F1 | 0.9683 | 0.9737 | 0.8696 |
We also include a modified ByteWeight data set that swaps out the icc compiled binaries with ones compiled with clang/llvm. (Thanks to Dennis for providing the clang binaries.)
Modified ByteWeight Data Set (gcc/clang/msvc)
| Binary Ninja | Nucleus | |
|---|---|---|
| Precision | 0.9702 | 0.9704 |
| Recall | 0.9753 | 0.9461 |
| F1 | 0.9727 | 0.9581 |
DARPA Challenge Binaries
This data set consists of a subset of the DARPA challenge binaries created for the Cyber Grand Challenge (CGC) and adapted by Trail Of Bits. We have plans to expand this data set to multiple compilers but for now it includes 283 binaries compiled with clang/llvm for the x86-32 architecture.
DARPA Challenge Binaries (clang/llvm)
| Binary Ninja | Nucleus | |
|---|---|---|
| Precision | 0.9996 | 0.9985 |
| Recall | 0.9994 | 0.9815 |
| F1 | 0.9995 | 0.9899 |
Busybox MultiArch Binaries
This data set consists of 16 BusyBox binaries where each is cross-compiled for a different architecture. All binaries are compiled with gcc using the default BusyBox settings. One set has optimizations enabled and another has them disabled.
Busybox MultiArch Binaries (gcc)
| Binary Ninja | IDA Pro v7.0 | Nucleus | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1 | Precision | Recall | F1 | Precision | Recall | F1 | |
| busybox_aarch64_opt | 0.9958 | 0.9551 | 0.9750 | 0.8461 | 0.8355 | 0.8408 | 0.9857 | 0.9101 | 0.9464 |
| busybox_aarch64 | 0.9980 | 0.9989 | 0.9984 | 0.9001 | 0.9600 | 0.9291 | 0.8397 | 0.9861 | 0.9071 |
| busybox_arm-thumb_opt | 0.8791 | 0.9411 | 0.9091 | 0.8569 | 0.8818 | 0.8692 | 0.0121 | 0.0453 | 0.0190 |
| busybox_arm-thumb | 0.9258 | 0.9727 | 0.9487 | 0.8985 | 0.9223 | 0.9103 | 0.0081 | 0.0314 | 0.0128 |
| busybox_arm_opt | 0.9976 | 0.9890 | 0.9933 | 0.8499 | 0.8580 | 0.8539 | 0.1973 | 0.2142 | 0.2054 |
| busybox_arm | 0.9964 | 0.9961 | 0.9963 | 0.8993 | 0.9351 | 0.9169 | 0.2722 | 0.2729 | 0.2725 |
| busybox_i386_opt | 1.0000 | 0.9944 | 0.9972 | 0.8638 | 0.9598 | 0.9093 | 1.0000 | 0.9639 | 0.9816 |
| busybox_i386 | 0.9975 | 0.9986 | 0.9980 | 0.9035 | 0.9822 | 0.9412 | 0.9961 | 0.9886 | 0.9923 |
| busybox_mips32_opt | 0.9812 | 0.9380 | 0.9591 | 0.7448 | 0.9104 | 0.8194 | 0.9451 | 0.9156 | 0.9301 |
| busybox_mips32 | 0.9886 | 0.9906 | 0.9896 | 0.8232 | 0.9583 | 0.8857 | 0.9861 | 0.8478 | 0.9118 |
| busybox_mipsel32_opt | 0.9788 | 0.9382 | 0.9580 | 0.7440 | 0.9122 | 0.8196 | - | - | - |
| busybox_mipsel32 | 0.9886 | 0.9905 | 0.9896 | 0.8207 | 0.9621 | 0.8858 | - | - | - |
| busybox_powerpc_opt | 0.8449 | 0.9416 | 0.8906 | 0.7610 | 0.9486 | 0.8445 | 0.8144 | 0.7777 | 0.7957 |
| busybox_powerpc | 0.9019 | 0.9928 | 0.9452 | 0.8245 | 0.9833 | 0.8970 | 0.7635 | 0.9872 | 0.8611 |
| busybox_x86-64_opt | 1.0000 | 0.9924 | 0.9962 | 0.8613 | 0.9551 | 0.9058 | 1.0000 | 0.9555 | 0.9773 |
| busybox_x86-64 | 0.9986 | 0.9994 | 0.9990 | 0.8982 | 0.9629 | 0.9294 | 0.9943 | 0.9898 | 0.9920 |
| Overall | 0.9662 | 0.9795 | 0.9728 | 0.8454 | 0.9373 | 0.8890 | 0.4932 | 0.6183 | 0.5487 |
Mission Accomplished
We have a few architectures where performance lags. However, these are typically due to incomplete lifting and/or other architectural differences (e.g. delay slots, multiple architectures in a binary). We are very pleased with the results, but we are not finished. Stay tuned.
Raw Results
We think it’s important to be transparent and support reproducibility of our work so we’ve published the binaries used in testing.
Acknowledgements
Thanks to the following whose shoulders we stand on and whose contributions helped this work:
- DARPA for releasing the CGC binary corpus
- Trail of Bits for their adaptation of that corpus
- Dennis Andriesse for sharing his test corpus and prior work on Nucleus
- ByteWeight team for their research as well as the coreutils corpus
- Rui Qiao and R. Sekar for their Function Interface Analysis research
Questions or Comments?
If you have questions or comments about this work, we’d love to hear it. Please comment below, join our Slack, or contact us on twitter @vector35.