Binary Ninja’s signature system automatically matches and renames copies of known functions based on their function signature. The signature system is designed to aid in analyzing statically-linked binaries without symbols available.
While a few signature libraries are bundled with Binary Ninja, you can now create your own signature libraries! These tools are available as the Signature Kit Plugin. If you’re on the dev branch, you can install it in the plugin manager now.
Warning: SigKit is no longer under active development. For more information, please see our previous post.
This post marks the official release of the signature system, and also serves as documentation for how it works and how to most effectively use it.
User Manual
Before diving into how the signature matcher works, here are instructions on how to use it. Or, you’re welcome to skip ahead to learn more about the design.
Running the signature matcher
The signature matcher runs automatically by default once analysis completes. You can turn this off in Settings > Analysis > Autorun Function Signature Matcher (or, analysis.signatureMatcher.autorun in Settings).
You can also trigger the signature matcher to run in the menu at Tools > Run Analysis Module > Signature Matcher.
Once the signature matcher runs, it will print a brief report to the console detailing how many functions it matched.
Generating signature libraries
To generate a signature library for the currently-open binary, use Tools > Signature Library > Generate Signature Library. This will generate signatures for all functions in the binary that have a name attached to them. Note that functions with automatically-chosen names such as sub_401000 will be skipped. Once it’s generated, you’ll be prompted where to save the resulting signature library.
For headless users, you can generate signature libraries by using the sigkit API (examples and documentation). I also recommend that you read the in-depth discussion of signature generation.
If you are accessing the sigkit API through the Binary Ninja GUI and you’ve installed the sigkit plugin through the plugin manager, you will need to import sigkit under a different name:
import Vector35_sigkit as sigkit
Installing signature libraries
Binary Ninja looks for signature libraries in 2 places:
- $INSTALL_DIR/signatures/$PLATFORM
- $USER_DIR/signatures/$PLATFORM
WARNING: Always place your signature libraries under the second location. The install path is cleaned whenever Binary Ninja auto-updates. You can locate it with Open Plugin Folder in the command palette and navigate “up” a directory.
Inside the signatures folder, each platform has its own folder for its set of signatures. For example, windows-x86_64 and linux-ppc32 are example platforms. When the signature matcher runs, it uses the signature libraries that are relevant to the current binary’s platform. (You can check the platform of any binary you have open in the UI using the console and typing bv.platform)
Manipulating signature libraries
You can edit signature libraries programmatically using the sigkit API. A very basic example here shows how to load and save signature libraries. Note that Binary Ninja only supports signatures in the .sig format; the other formats are for debugging. The easiest way to load and save signature libraries in this format are the sigkit.load_signature_library() and sigkit.save_signature_library() functions.
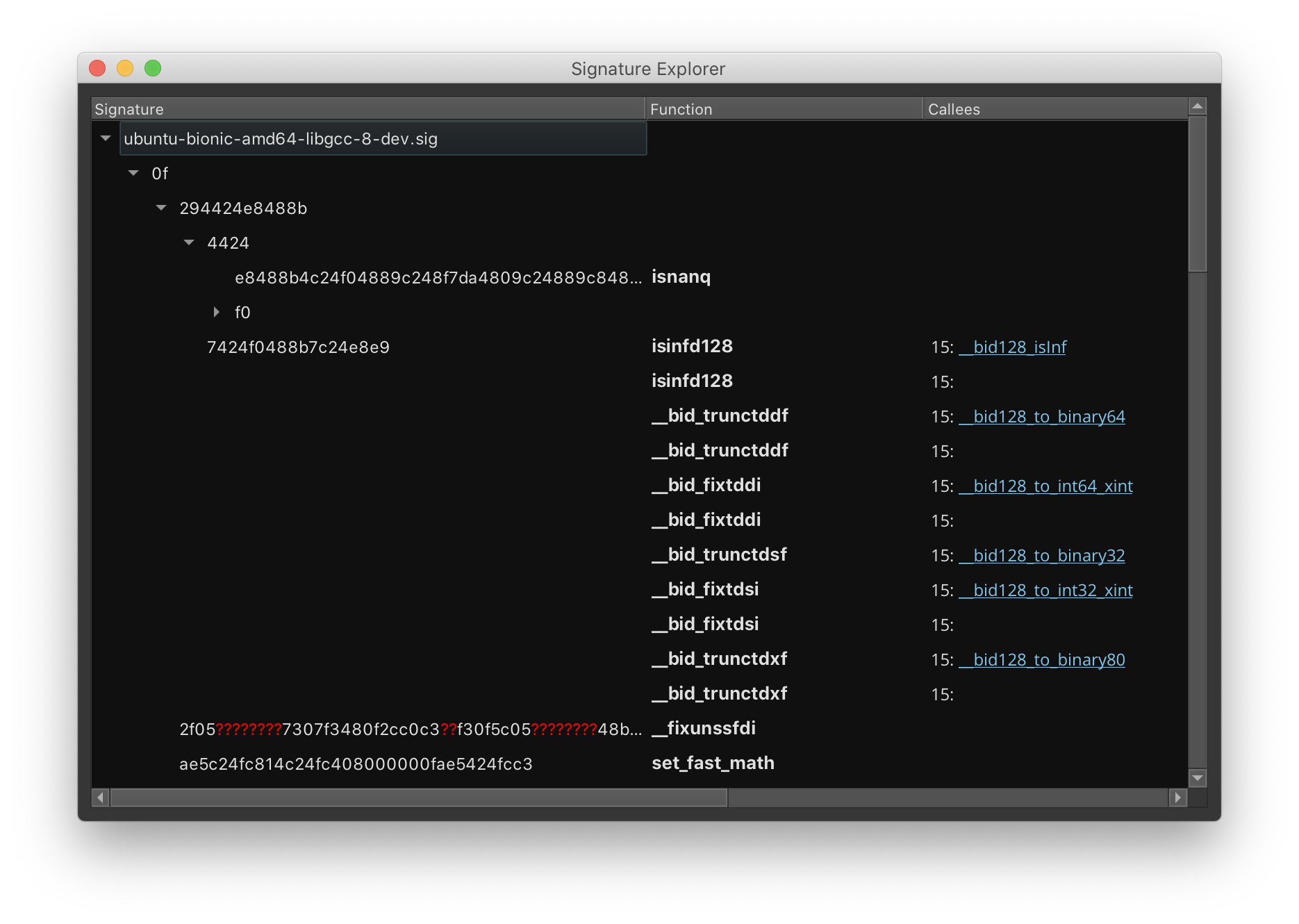
To help debug and optimize your signature libraries in a Signature Explorer GUI by using Tools > Signature Library > Explore Signature Library. This GUI can be opened through the sigkit API using sigkit.signature_explorer() and sigkit.explore_signature_library().
For a text-based approach, you can also export your signature libraries to JSON using the Signature Explorer. Then, you can edit them in a text editor and convert them back to a .sig using the Signature Explorer afterwards. Of course, these conversions are also accessible through the API as the sigkit.sig_serialize_json module, which provides a pickle-like interface. Likewise, sigkit.sig_serialize_fb provides serialization for the standard .sig format.
Motivation
I’m an avid CTF player and reverse-engineer. One of the most frustrating challenges I have to deal with regularly is when I’m tasked with reversing a stripped binary with statically-linked libraries. Over the course of my summer internship (that transitioned into a much longer internship!), I designed and implemented the signature system to help solve this common problem.
Static linking has the benefit of easy deployment: all dependencies are baked into the final binary. However, static linking also massively increases the size of the binary. For example, look how many libraries the simple ls utility relies on:
$ ldd /bin/ls
linux-vdso.so.1 (0x00007ffff21e6000)
libselinux.so.1 => /lib/x86_64-linux-gnu/libselinux.so.1 (0x00007fa578b50000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007fa578750000)
libpcre.so.3 => /lib/x86_64-linux-gnu/libpcre.so.3 (0x00007fa5784d0000)
libdl.so.2 => /lib/x86_64-linux-gnu/libdl.so.2 (0x00007fa5782c0000)
/lib64/ld-linux-x86-64.so.2 (0x00007fa579000000)
libpthread.so.0 => /lib/x86_64-linux-gnu/libpthread.so.0 (0x00007fa5780a0000)
Even a minimal hello-world C program will want libc.so and ld.so. See for yourself: here’s a size comparison between dynamically-linked and statically-linked versions:
$ ls -sh test_dynamic
12K test_dynamic
$ ls -sh test_static
828K test
$ objdump --sym test_dynamic | wc -l
68
$ objdump --sym test_static | wc -l
1815
The binary went from 68 functions in a few kilobytes to 1815 function in nearly a megabyte! Now, imagine that there are no symbols available either. For reverse-engineers, this spells doom. It’s difficult to tell which parts of the binary are irrelevant library material and which parts actually belong to the program itself. Moreover, common runtime functions like malloc, strcmp, and printf become sub_472bc0, sub_432da0, and sub_462e40. Hence, even if you can locate interesting functions, it’s still extremely difficult to tell what they’re doing. Here is an simple program, one screenshot with symbols and one stripped:
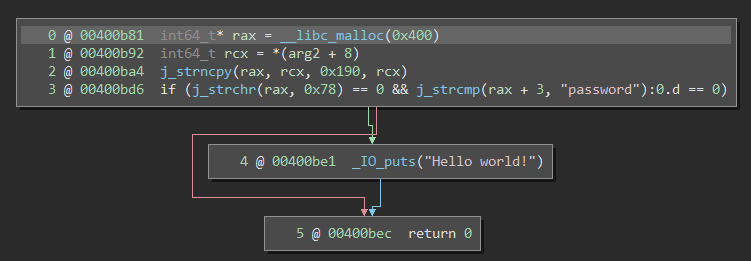
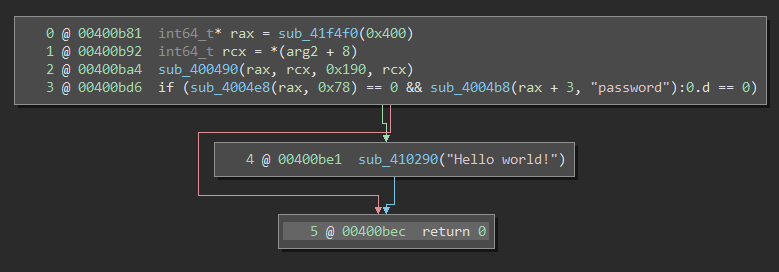
I’m sure you imagine that this is very unpleasant when trying to analyze the binary.
In general, the software ecosystem has primarily relied on dynamic linking in the past for size efficiency. However, as storage has become much cheaper, there has been a gradual but steady shift towards static linking. Statically-linked binaries are simple to deploy and likely to work across many different systems. For this reason, some runtimes now statically link by default, like Go or iOS IPAs. In the future, it’s almost certain that we are going to encounter more statically-linked binaries.
Goals
The goal of our signature matcher is to put an end to the stripped-statically-linked nightmare. We should be able to generate signatures for a handful of prevalent and widespread libraries such as libc, openssl, and libcurl, and use those signatures to detect copies of library functions.
Software maintainers rarely compile the libraries their code depends on, instead relying on pre-compiled libraries distributed by their respective maintainers. Because of this, many statically-linked binaries actually share the exact same library code. For instance, any Linux binary you encounter in a CTF is likely to use a copy of libc from the central Ubuntu apt repository. This is especially true for packages like libc or msvcrt that are rarely compiled from scratch.
Compilers are also deterministic and very predictable. There are also very few mainstream compilers in existence: namely gcc, clang, and msvc. Given two copies of a library compiled by separate maintainers, it is more likely than not that there will still be a significant amount of code overlap between the two copies. Check out this example: even with two very different versions of clang, the outputted assembly code is exactly the same! The same is true for other compilers.
We want to have signatures for a lot of libraries. Ideally, we would have signatures for all of the common stuff we come across day-to-day while reverse-engineering: libc, msvcrt, openssl, ffmpeg, etc. If we’re going to have a large number of signatures, they had better be compact to avoid wasting disk space and memory. If we just stored the libraries’ contents directly, it would easily take up hundreds of gigabytes. Hence, we need to carefully design and structure our signature libraries to maximize space efficiency and exploit the aforementioned code overlap phenomenon.
Signature matching must also be very fast and avoid false positives. False negatives are more acceptable than false positives. We want the signature matcher to be fast enough to reasonably run on every binary that we analyze. Therefore, heavy-weight solutions like IL-based matching, symbolic execution, or abstract interpretation not a good first-choice. We need to rely on a simple-but-robust algorithm for function matching, and offload the heavy computational steps to the offline signature generation stage.
In summary, our signature system should:
- Find exact copies of library code
- Exploit code duplication across various versions of libraries
- Minimize signature size as much as possible
- Run as fast as possible
Matching algorithm
The matching algorithm is inspired by FLIRT, which was designed with similar requirements in mind. In summary, for each function, we generate a pattern that consists of the function’s raw bytes and a mask that wildcards out certain bytes in the pattern. These wildcards mitigate the differences among copies of the same library. Similar to FLIRT, signature libraries keep a trie (prefix tree) of these patterns. Using a prefix tree greatly improves the space efficiency and also enables efficient (linear time) matching.
Here is an example trie (displayed with TrieNode.pretty_print):
f6:[]
0f:[]
84:[]
040100008b461883f8040f87f80000004c8b4610:[<srandom_r>]
0f0100000fb607554889e53c3a0f844801000048:[<path_normalize>]
94c14885d20f94c008c10f85bc0200004885ff0f84:[<sigandset>, <sigorset>]
41:[]
5455:[]
4889d55374294889fb438????????48895df8:[<argz_extract>]
53:[]
0f84f3000000488b1d????????4c8d04374:[<func1>, <func2>]
74:[]
304889fd4889f34531e4660f1f4400004:[<argz_count>]
In my testing, I aimed to create signatures that matched many slightly-different versions of a library. For example, an implementation of strcpy may vary slightly between different versions of Ubuntu 16.04 libc6. Therefore, we allow functions to appear in multiple places in the trie. Each trie node can have zero or more functions.
Aside from their position in the trie, to improve precision and accuracy we also track the following additional information about each function:
- Disambiguation bytes
- Callee functions
Disambiguation bytes are very simple: they’re just an additional pattern (bytes and mask) that the function should match. We try to choose disambiguation bytes that are different for all functions in the same leaf node.
We also store call graph information about each function. Unlike FLIRT, we process all call edges, not just external references. All functions that appear in the trie are interlinked through this call graph: for example, memcpy calls __stack_chk_fail. When we’re performing matching, a candidate function must also have all of its call-sites and callees match their respective signatures in the signature library. For example, if we believe sub_10000 is memcpy, then sub_10000 must also call some function that matches __stack_chk_fail.
Tracking call graph information is a powerful enhancement to the signature trie. By doing so, we measure not only the contents of individual functions, but also the semantic relationships between them. However, it does complicate matching: all of the leaf nodes in our trie are linked in a non-trivial, non-linear fashion. Testing a signature against a candidate function now requires a traversal of the call-graph: all callees (and their callees, and so on recursively up to closure) must match their respective signatures.
Obviously, this relationship is recursive, which begs the question of handling cycles in the call graph. We solve this problem by traversing the call graph optimistically: we track which assumptions we’ve made so far, and when we encounter a back-edge we require that the signature we’re expecting is the one we assumed the previous time we encountered the function. This is similar to the coloring done by Tarjan’s SCC algorithm.
To make the call graph analysis work in practice, the signature matcher also implements thunk resolution. If a function boils down to simply jumping to another function, we elide (via edge contraction) this function in the call graph while matching. When a thunk is resolved, we will also apply a name like j_memcpy to indicate that the function is a thunk.
Lastly, we remove functions that are too close to the root of the trie. Because their prefixes (patterns) are so short, they could cause false positives. However, these removed functions might still be included in a signature library. If other functions call them, then they become bridge nodes: functions that aren’t present in the trie, but are referenced in the call graph.
Aside: Why not IL-based matching?
I’d like to take a brief moment to explain why I chose not to implement IL-based matching. I actually started by prototyping IL-based matching for a few weeks. In the end, however, I scrapped it since I wasn’t happy with the quality of the results. Here’s why the signature system uses simple byte-pattern signatures instead.
IL-based matching is complicated. The first problem you will immediately run into is the graph isomorphism problem. Whereas byte sequences and patterns are linear data structures and are easily compared, graphs are non-linear and very difficult to compare. Even DAG isomorphism is GI-complete. When we’re matching byte sequences, we can simply proceed linearly from the start of the function forwards. However when we’re matching IL, we need to walk the control flow graph. Unfortunately, we can’t reliably traverse the CFG in the exact same order expected by the function signature: conditional branches edges might be inverted, for example.
Also, because Binary Ninja uses an complex-instruction IL as opposed to three-address code IL, each IL instruction is actually an abstract syntax tree. Here’s an example of a BNIL AST, generated by this awesome plugin:
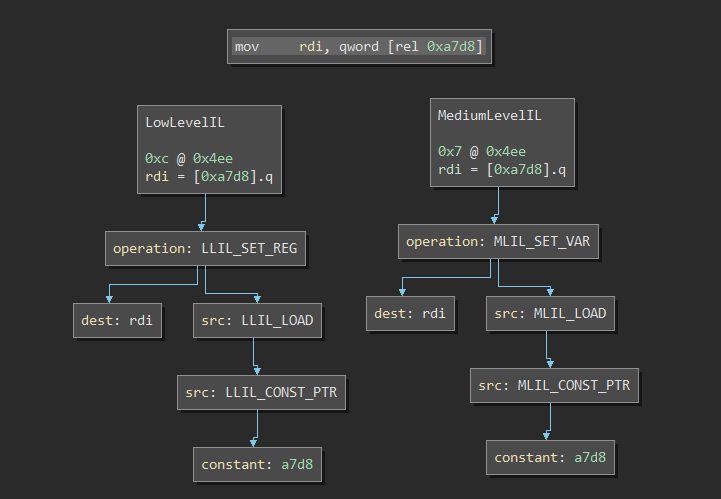
Although tree isomorphism is a solved problem, having to compare ASTs rather than byte sequences is still challenging. For one, AST comparison is extremely brittle; it’s hard to create an accurate metric to quantify graph distance. This ultimately leads to false positives and false negatives.
Lastly, IL-based signatures are more difficult to store and deserialize. Because of our tight space and time efficiency goals, the cost of storing graphs and ASTs is too high.
One solution is graph hashing, e.g. graph kernels. If you’re interested in that, check out this great series of blog posts about Hashashin, a binary hashing plugin. Nevertheless, graph hashing is not always accurate. It’s crucial that we avoid any false positives, and byte-sequence matching is a relatively tried-and-true solution.
Ultimately though, there’s nothing fundamentally preventing IL-based function matching. IL-based matching is a very promising approach for higher-level, meaningful matching on function semantics rather than superficial appearances which lets it act as a much more powerful matcher. Nevertheless, IL-based matching is somewhat overkill for our problem, which is to simply recognize exact duplicates of library code. Since we’re shipping this feature to our whole userbase, it’s important that we respect the everyone’s use-case and therefore avoid unnecessary complexity.
Of course, that isn’t to say that Vector 35 wouldn’t add on an additional IL-based matching capability in the future.
File format
The Binary Ninja signature library file format is relatively simple. The sigkit API contains an implementation for saving and loading this format. It begins with a 4-byte magic, BNSG, followed by a 1-byte version number (currently 01). The remainder of the file is a zlib-compressed Google flatbuffer object.
0000: 42 4e 53 47 ... magic 'BNSG'
0004: 01 ... version 1
0005: 78 9c 84 5d ... Zlib data
...
The flatbuffer object’s schema can be found here.
The file format is designed to make matching as fast as possible. First of all, signatures do not need to be fully-parsed, thanks to flatbuffers. This means that the signature matcher can simply map the file into memory and seek through it lazily as it traverses the signature library. This allows us to load a large number of signature libraries while keeping a small memory footprint. Moreover, parsing a node boils down to reinterpret-casting a pointer, which is free. Hence, checking against a signature library is, in theory, allocation-free. The downside, however, is that it is not very cache-friendly.
Signature Generation
Generating good signature libraries is actually the most challenging part of the signature system. It’s challenging because for any popular library, there are a huge number of different versions floating around out there. To understand how we tackle this challenge, let’s look at the signature libraries that currently ship with Binary Ninja.
My goal was to generate signatures for libc and libgcc for each major release of Ubuntu (16.04, 18.04, etc). For each major release, there are several architectures that are available (amd64, arm64, i386, ppc, etc). And for each architecture, each package has several versions available (libc 2.27-0ubuntu3, 2.27-3ubuntu1, etc). To collect all of these libcs, I wrote a very fast crawler that scraped them from Ubuntu’s apt repository called Launchpad. On a high-speed connection, it took about 1 hour to download 6.3 GB (!) of libc6-dev and libgcc-dev .debs.
ubuntu/
├─artful
├─bionic
│ ├─amd64
│ │ ├─libc6-dev
│ │ │ ├─2.26-0ubuntu2
│ │ │ │ └─libc6-dev_2.26-0ubuntu2_amd64.deb
│ │ │ ├─2.26-0ubuntu2.1
│ │ │ ├─2.26-0ubuntu3
│ │ │ ├─2.26-0ubuntu4
│ │ │ ├─2.27-0ubuntu2
│ │ │ ├─2.27-0ubuntu3
│ │ │ └─2.27-3ubuntu1
│ │ ├─libgcc-5-dev
│ │ ├─libgcc-6-dev
│ │ ├─libgcc-7-dev
│ │ └─libgcc-8-dev
│ ├─arm64
│ ├─armhf
│ ├─i386
│ ├─ppc64el
│ └─s3900x
├─breezy
...
├─xenial
├─yakkety
└─zesty
6.3G total
Note that it’s paramount we work with the “-dev” packages here. We need to use the static .a libraries that static executables are linked against, not the .so binaries that dynamic executables use. This is because there are subtle differences between the behavior and contents of the .so and .a library binaries. For example, some optional components become null when they’re not linked against for statically-linked binaries. These differences ultimately lead to inaccurate signatures.
Moreover, .a libraries contain the raw, unlinked .o object files. Because they’re unlinked, these object files contain relocation tables which are invaluable for computing the pattern masks discussed earlier. When an object file gets linked, the linker basically copy-pastes it byte-for-byte into the final executable. The only bytes that change are the relocation bytes. This information is thus extremely useful for us: those are the bytes which vary from binary-to-binary. When relocation ranges aren’t available, we’re forced to heuristically guess masks based on MLIL patterns. Here’s a function from malloc.c, where all of the instructions containing relocations have been annotated using this script:
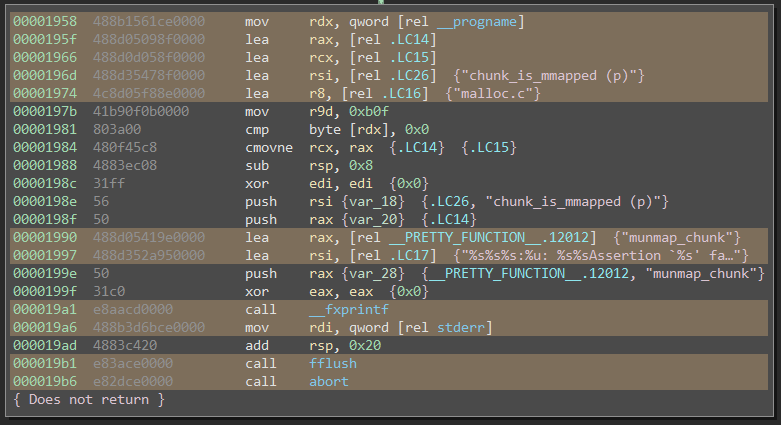
Using .o files also creates clear boundaries between each compilation or translation unit. By cutting the linker out of our input data, however, the onus of linking the call-graph together is on us. Our signature generator is now responsible for resolving external references. This isn’t a bad thing: actually, we want access to this kind of fine-grained call-graph information so we can closely tune it for signature generation.
Still, we’re left with gigabytes of object files. The key is that we need to exploit the aforementioned code overlap and de-duplicate among all of these slightly-different versions of libc. Our insight is that we’ll generate signature tries for each version of libc separately, and merge them together later. We’ll only merge together signature libraries that we think will exhibit a lot of overlap; for example, ubuntu-bionic-amd64-libc-* are all likely to basically be the same code packaged differently.
How do we merge signature libraries? The algorithm is fairly complicated, but I’ll explain the high-level intuition. Let’s say we have two function signatures, A and B. We’re going to think about these signatures, A and B, in terms of the set of all functions that they match. For example, A might match functions that are instances of memcpy, and B might match functions that are instances of strcmp. Obviously, in this case, signatures A and B match different functions, so they’re both useful to have in our signature library.
But let’s say A matches all of the functions that B matches! Then it’s useless to keep B around in our signature library; B is redundant because of A. We’ll express this abstract relationship in notation as B ≤ A. Specifically, B ≤ A if the set of functions matched by signature B is a subset of the functions matched by signature A. When we merge two signature libraries, we want to remove all non-maximal function signatures B where there exists some other function signature A such that B ≤ A. This eliminates the redundancy.
Some theory-minded people might recognize that this kind of algebraic structure is a partially-ordered set or lattice. Apart from this, there are a few other clever tricks that exploit the structure of the function signature lattice to get the size down. So I recommend you to read the code if you’re interested :)
Conclusion
Whew! That was quite a lengthy blog post. Hopefully, this article addresses most of the questions you might have about the signature system. If not, feel free to ask us on the Binary Ninja community Slack or make an issue.
If you haven’t already, you can install the Signature Kit Plugin through the plugin manager (press Ctrl+Shift+M) now if you’re on the dev branch. Try out the signature matcher! I hope it helps reverse-engineers tackle static libraries in the future.
I’m also thankful to the rest of Vector 35 for my awesome internship the past summer. Being able to contribute back to the reverse-engineering community in a meaningful way means a lot to me. Looking forward to the future!