It’s been over a month since we announced the Binary Ninja Debugger Plugin (BNDP) in beta, and as it begins to near the time it can shed its “BETA” tag, we wanted to show off the current state of the features and capabilities. Note that the debugger is being implemented as an open source plugin and feedback and code are always welcome.
First, the highlights: BNDP does most of the usual things you’d expect from a debugger:
- instrument processes
- pause/resume
- step into/step over/step until return
- detach
- inspect memory
- see/change register state
- disassemble new regions of memory as it executes through them
And it can do a few things you might not expect from all debuggers:
- automatically update functions and branch points in a binary based on execution through it
- apply arbitrary types and structure decoding to live memory
- annotate calls with run-time specific arguments
Though there’s a few features still in development that aren’t done yet:
- attaching to a running process1
- support for forking processes2
- see more requested enhancements
Finally, the debugger runs on the most common architectures and platforms but more importantly, it’s implemented on an extensible architecture that makes it easy to add support for new platforms and debugging APIs.
Demos
Let’s do the fun stuff first and show off some demos. You can skip to the end for specifications and architecture discussions.
Switch/Case Discovery
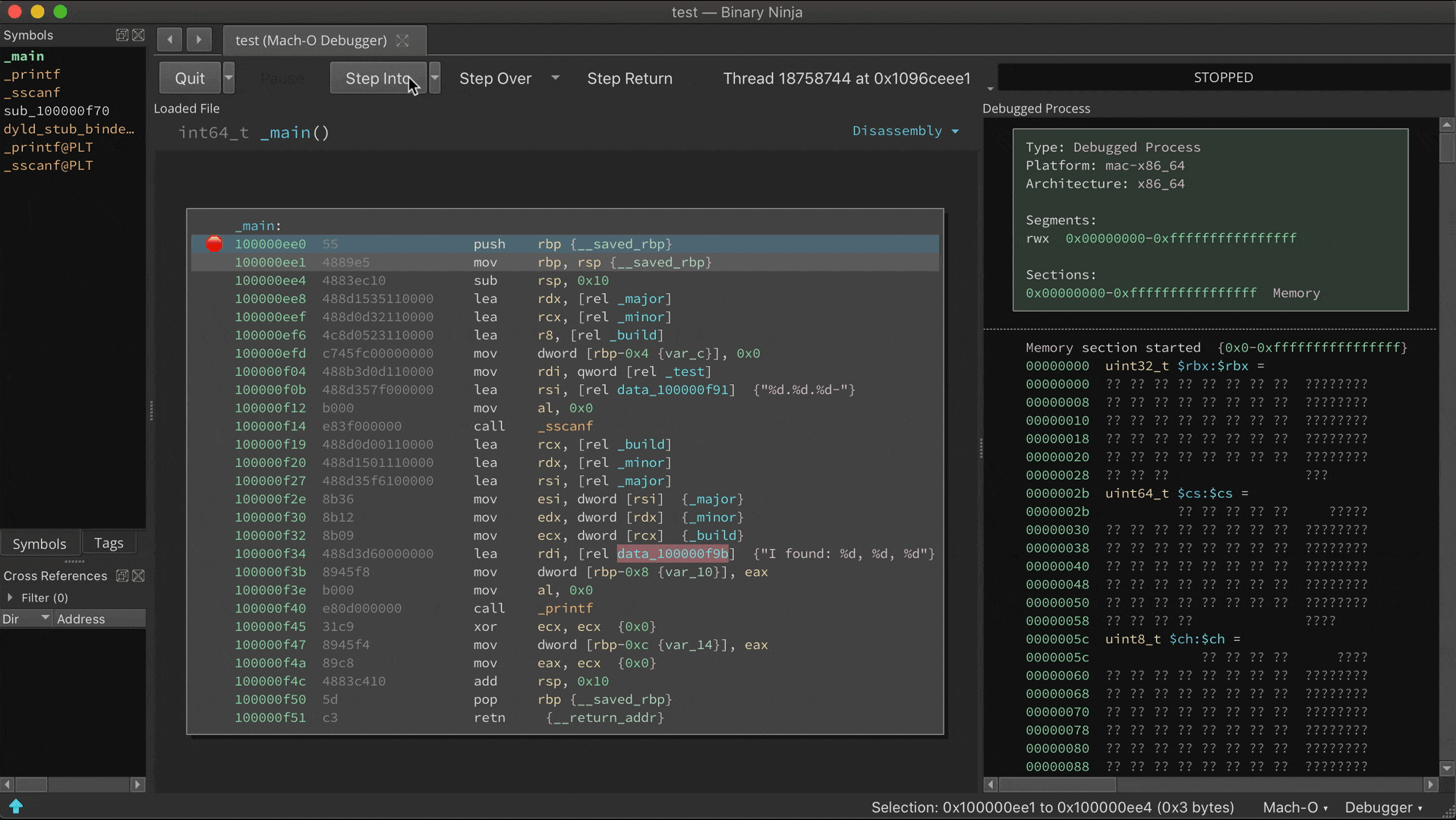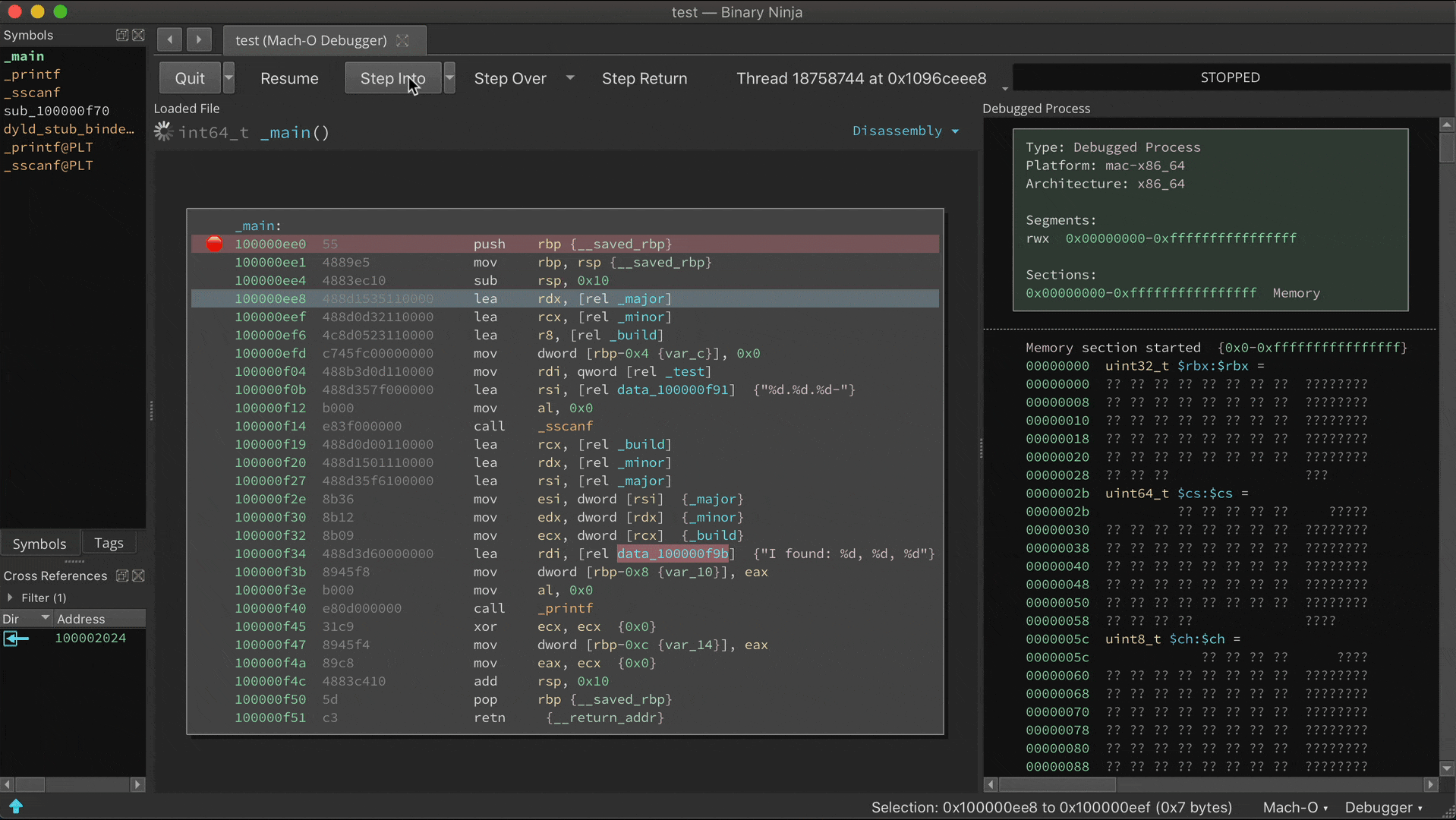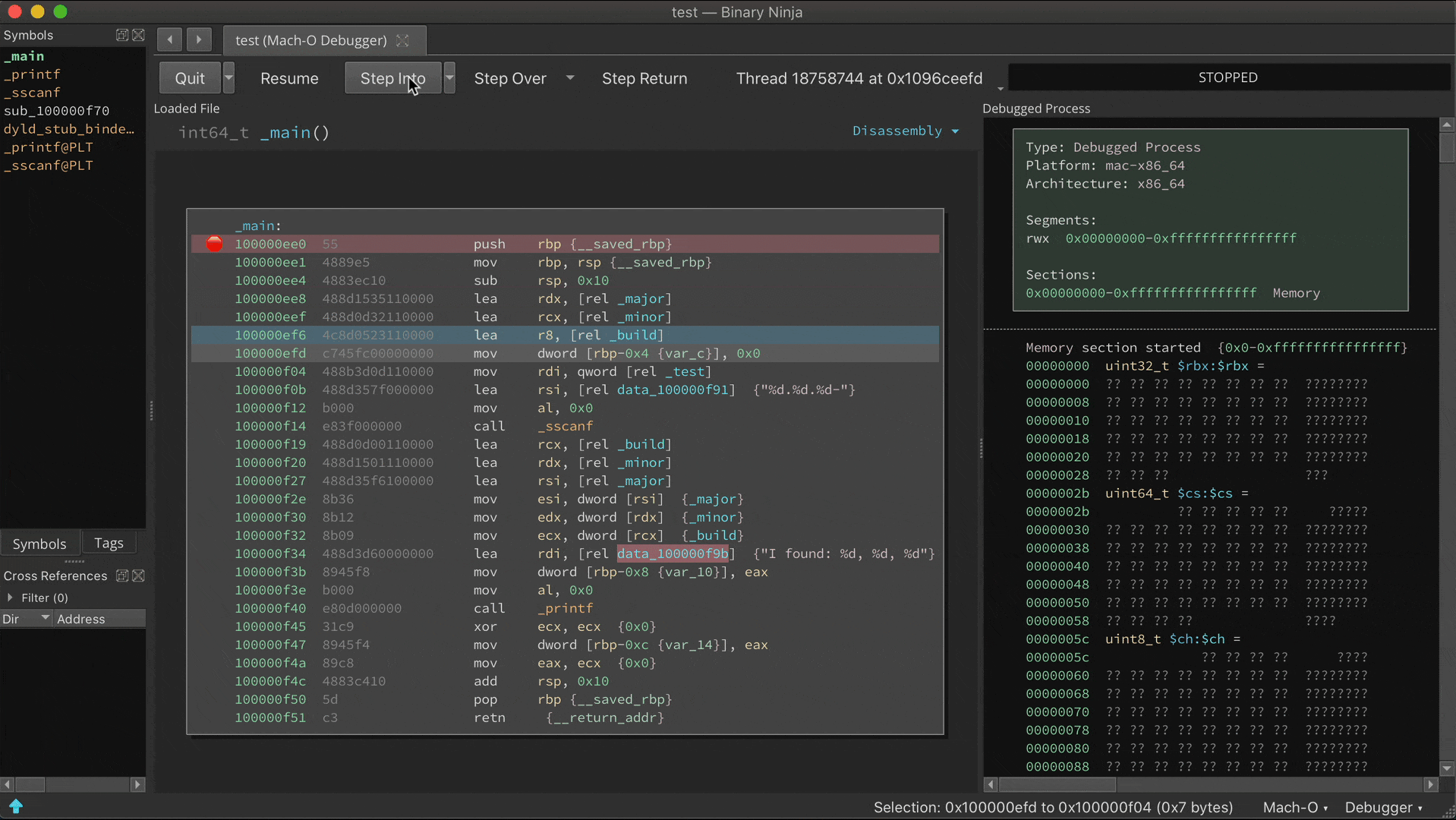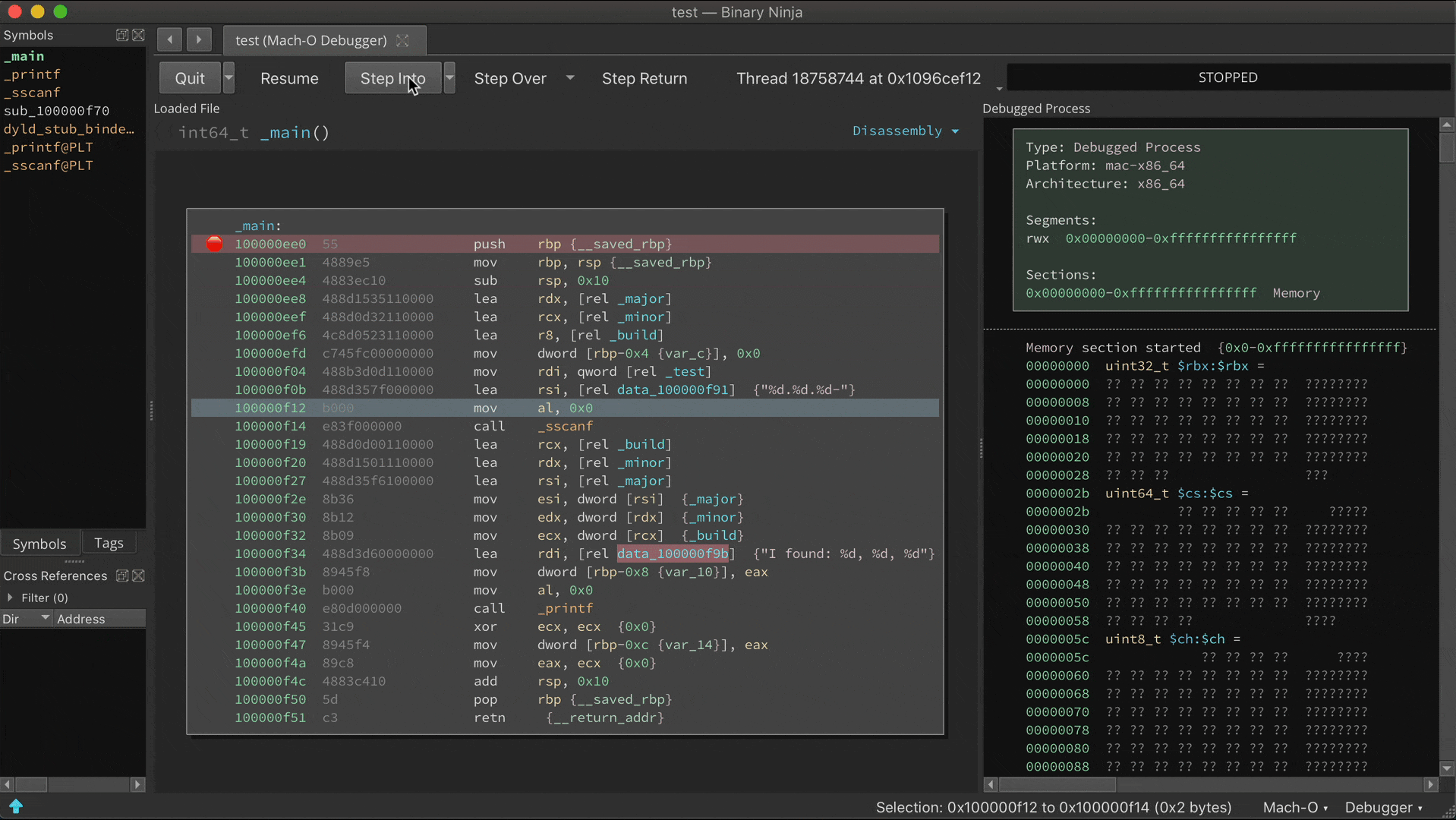
The static analysis is adept and finding switch statements and their corresponding jump tables, but with considerable effort it can be fooled into missing a case. If a new case is observed at runtime, analysis is updated:
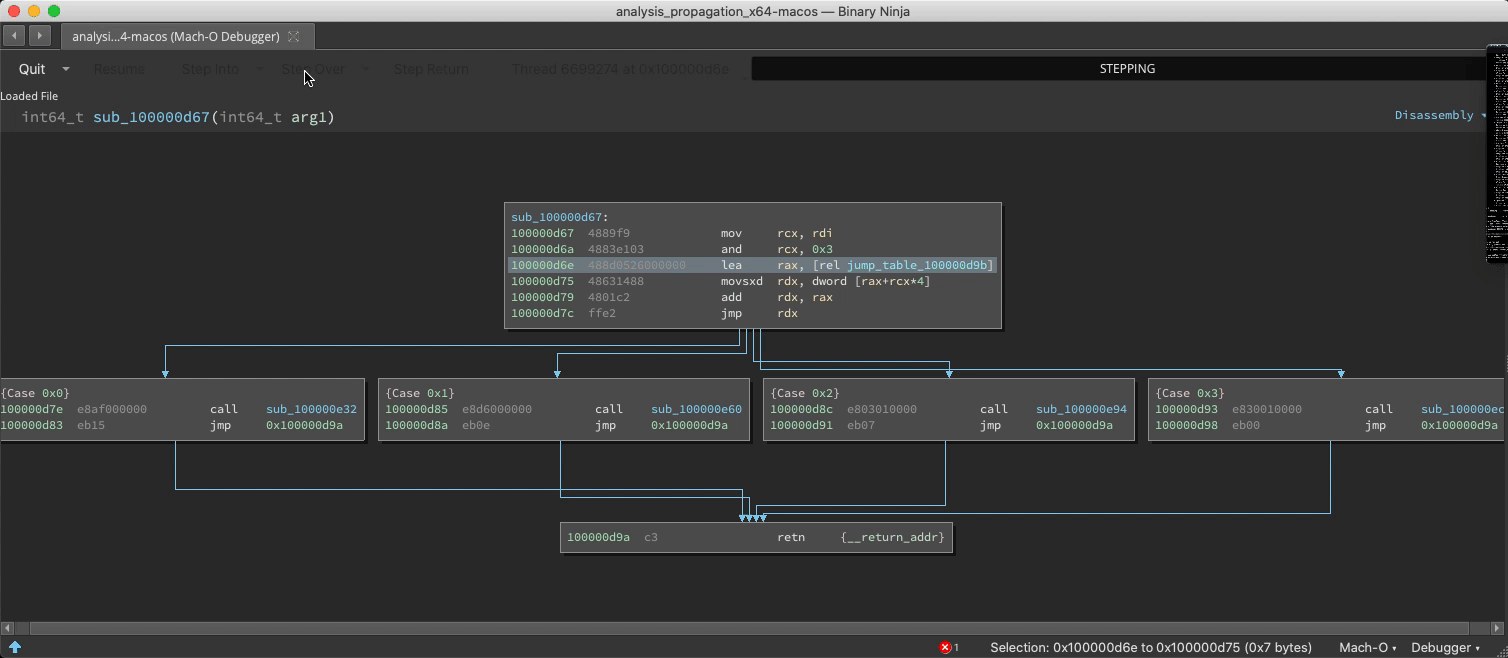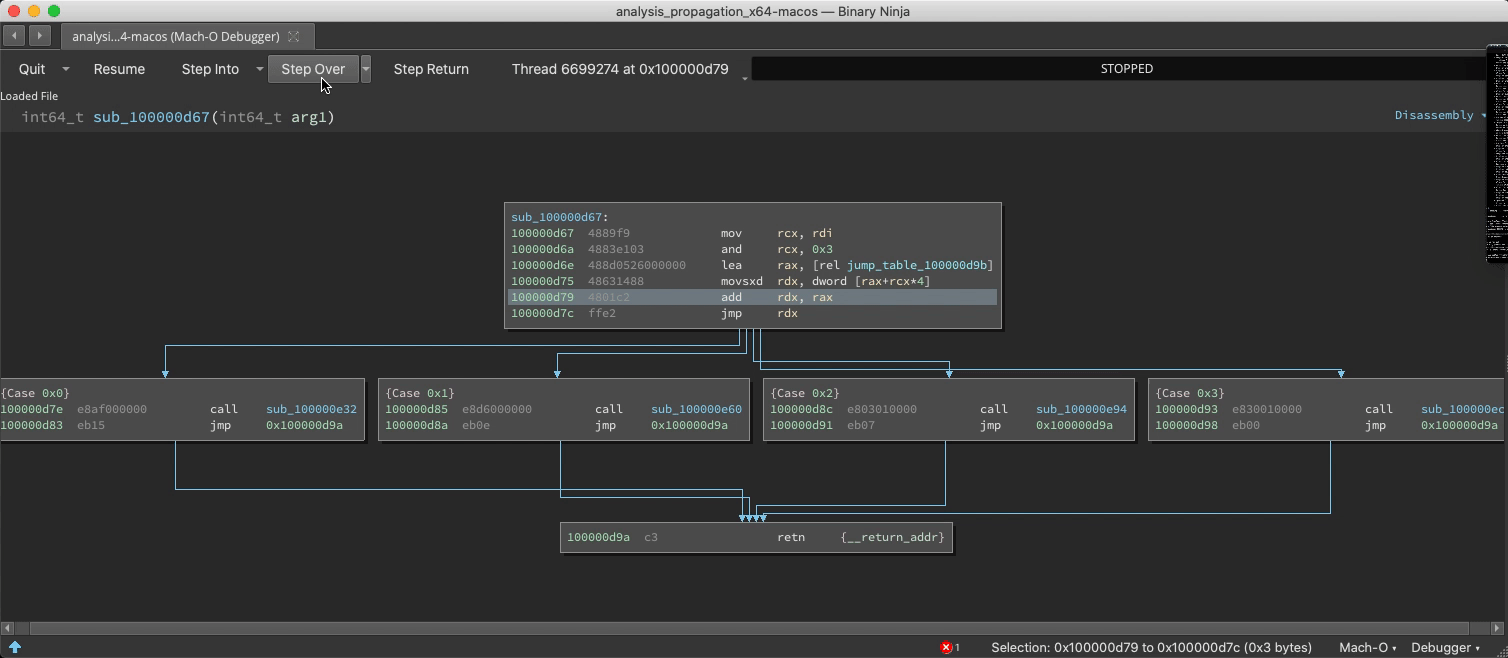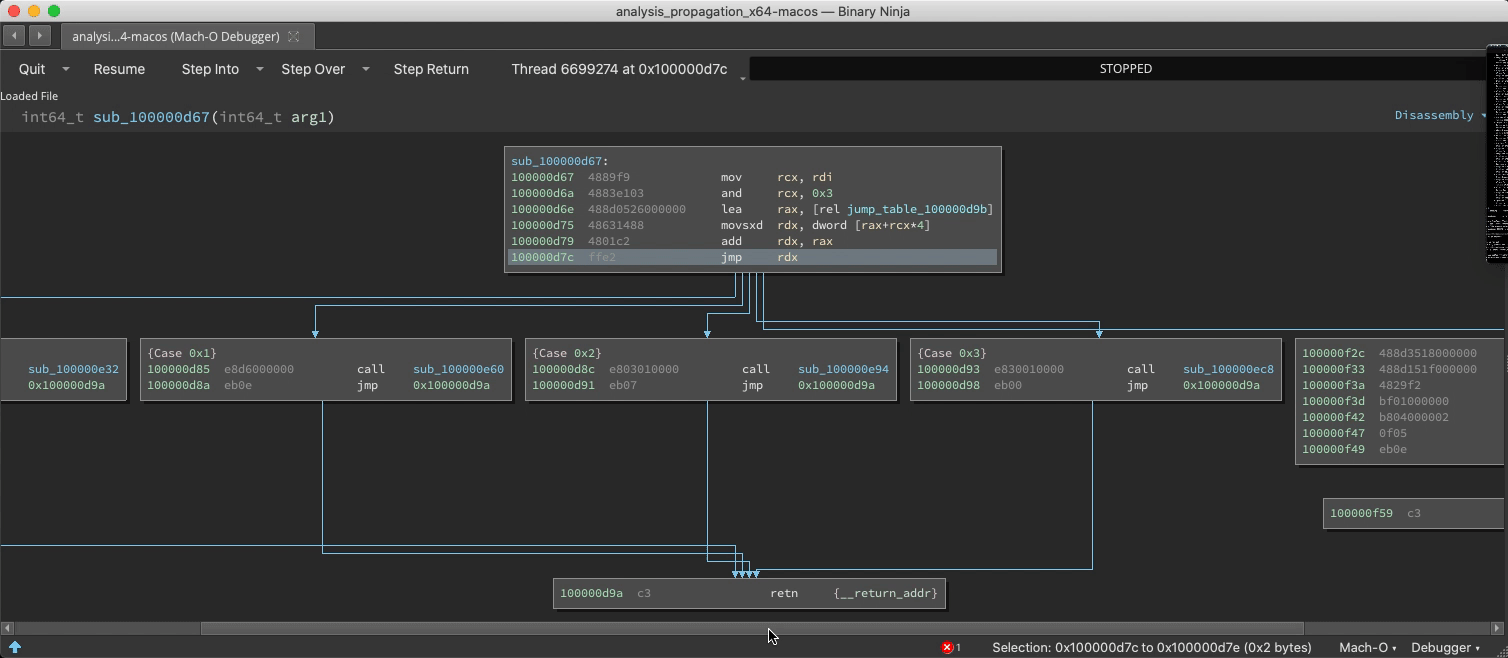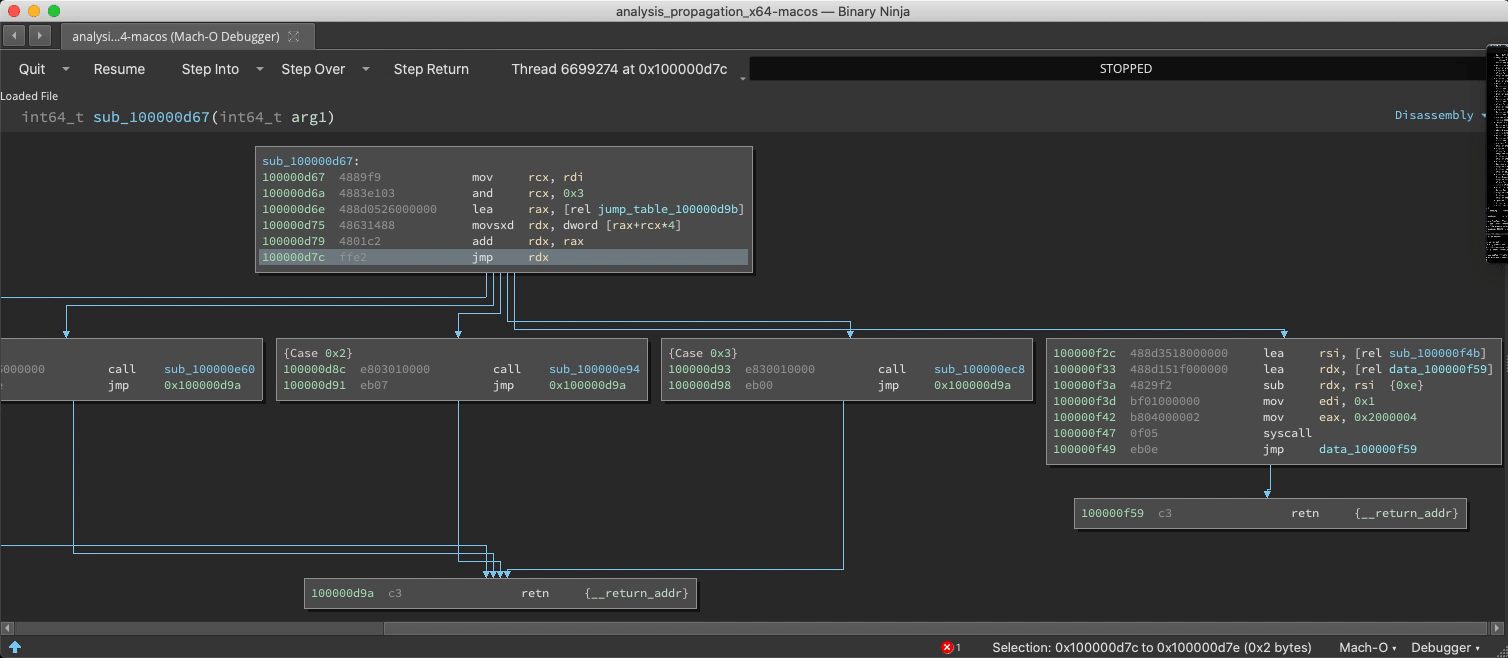
Undiscovered Country
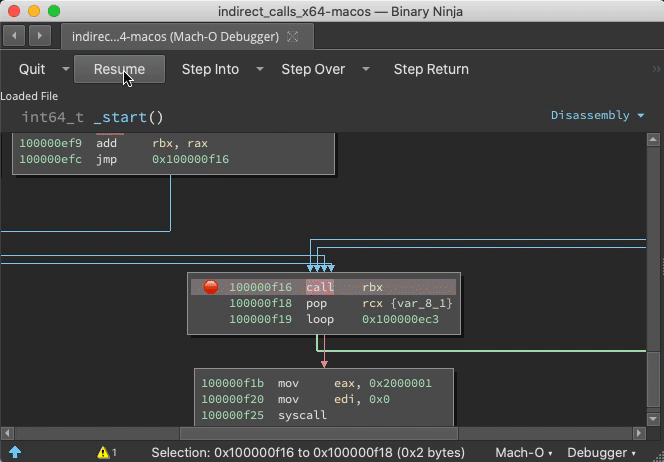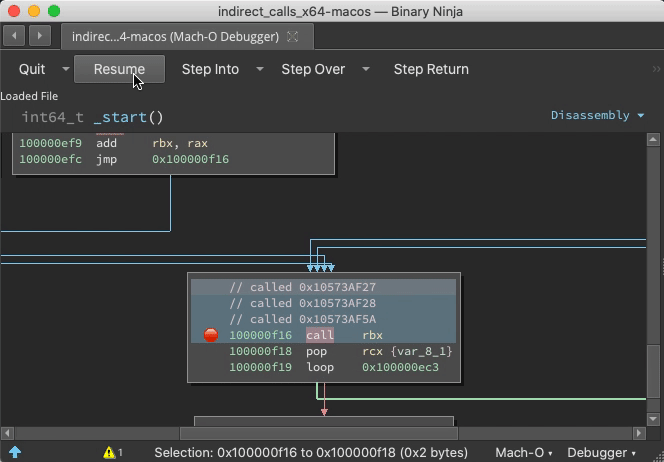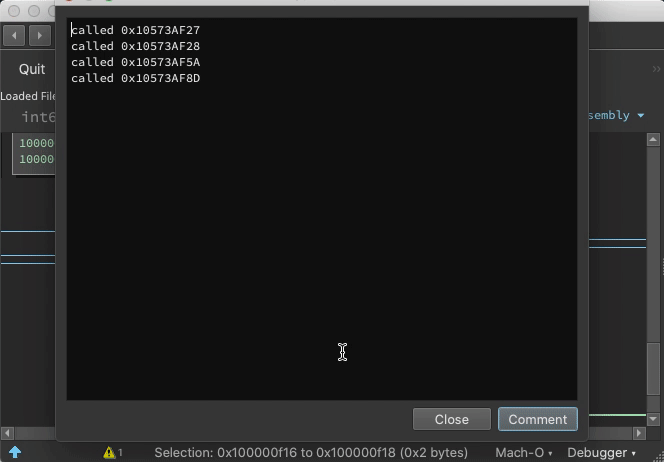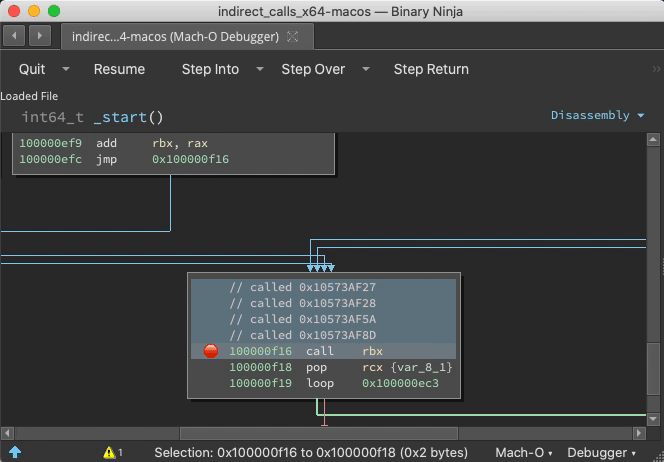
If a function is purposely hidden or even just the result of a virtual function call or other indirect control flow, static analysis might miss it. But during runtime, analysis can be told the address of call destinations great improving function identification.
Prior to the call ebx, address 0x100000f25 is just data. But once this instruction is reached, Binja wisens up:
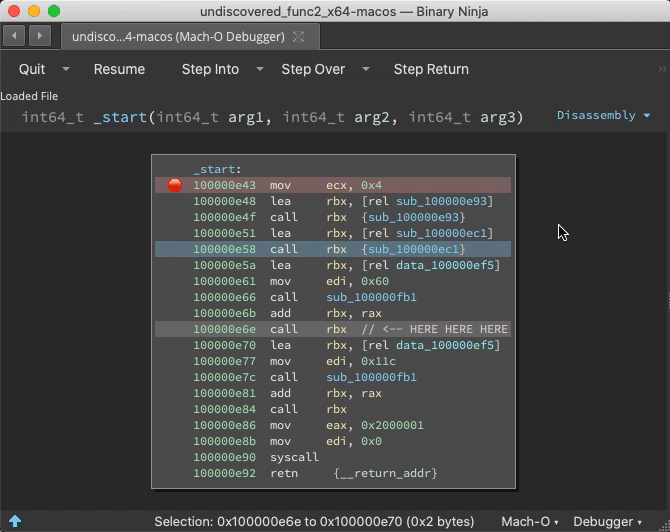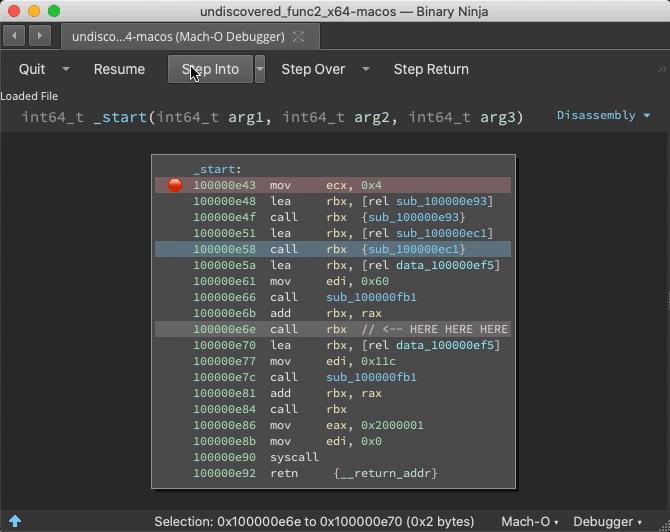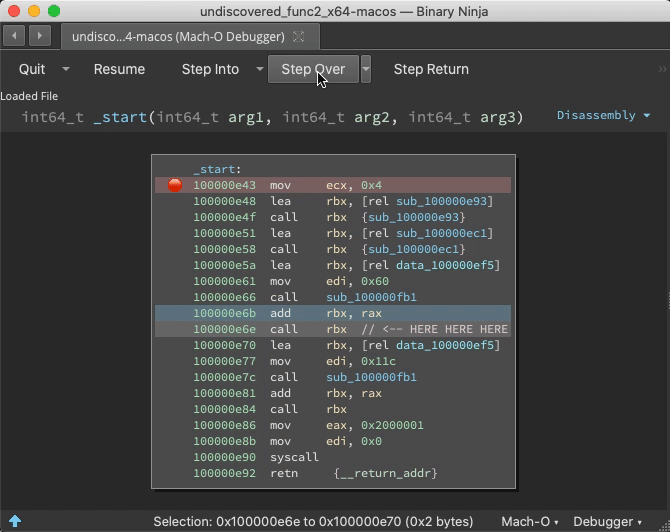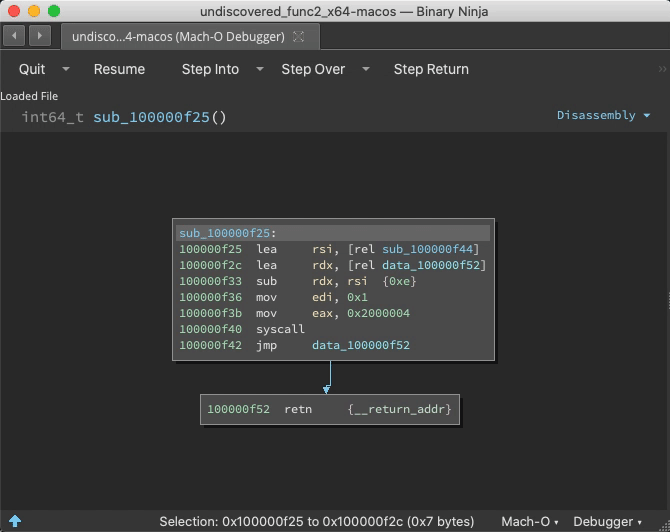
Indirect Jump Annotation
With the debugger.extra_annotations setting, function starts get annotated with context information and targets of indirect calls are logged as comments:
Connect to MAME
With the right plugin, Binja can analyze Z80 binary code in Colecovision ROMS. And since MAME exposes a gdb stub, we can connect to it:
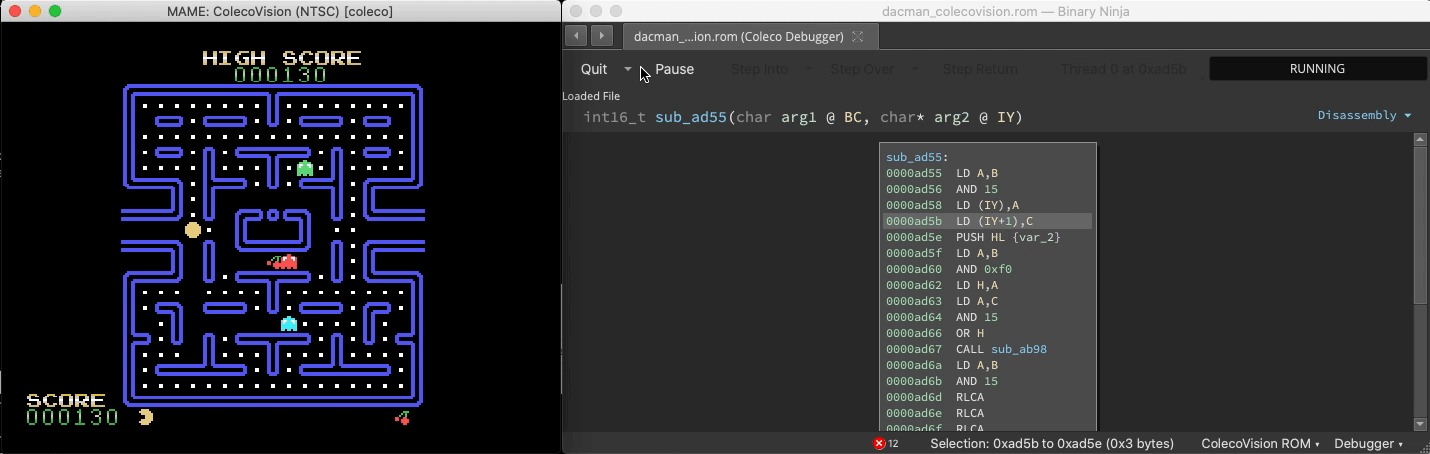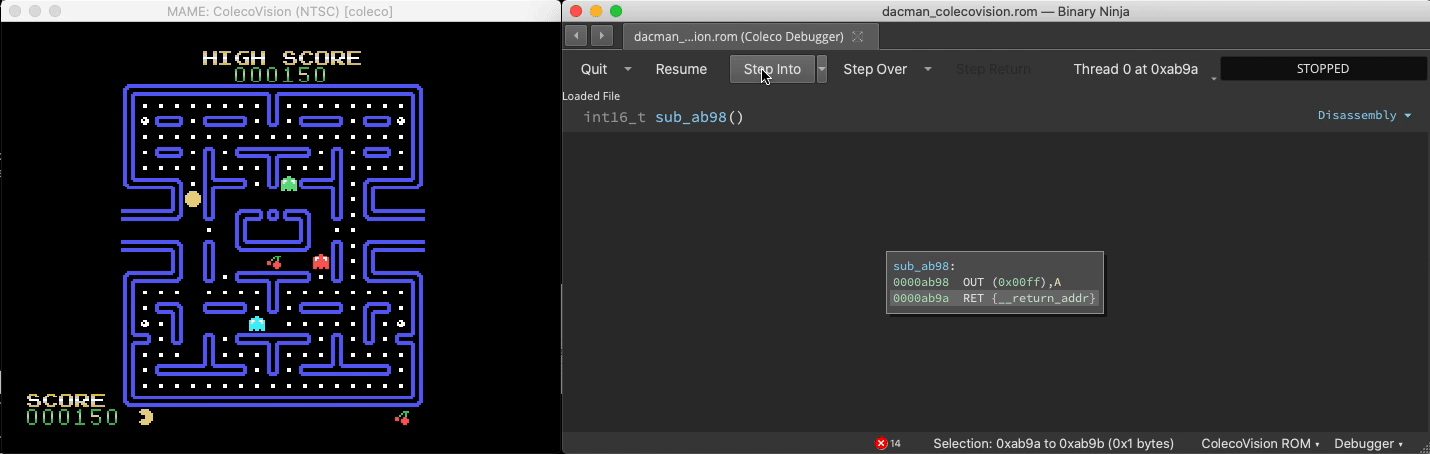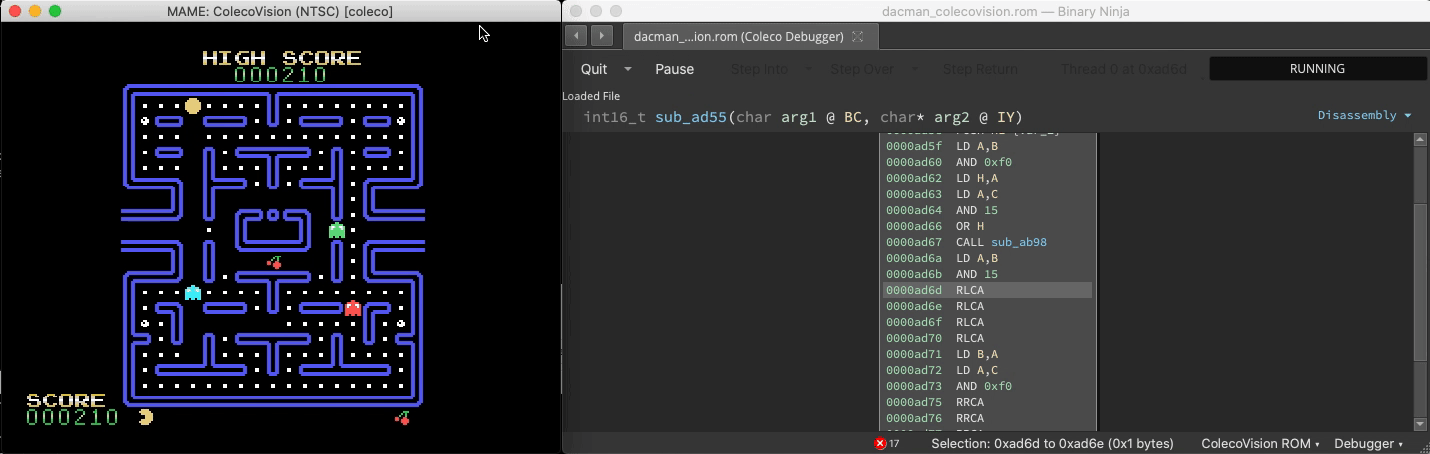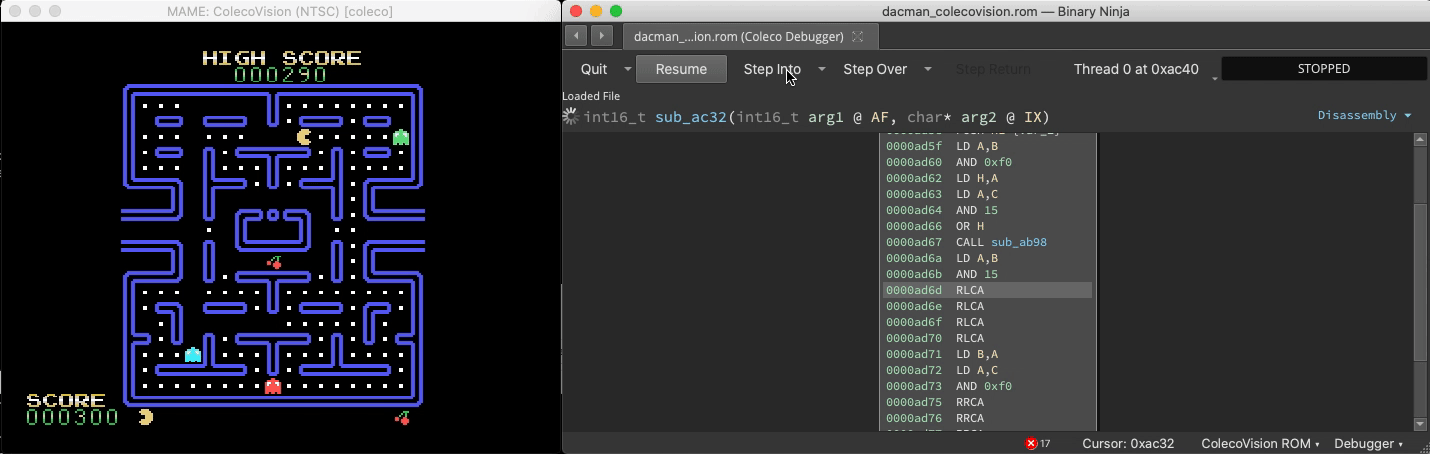
A headless script that breakpoints all Binja-identified functions and updates a live graphical map of the binary reveals which functions are responsible for gameplay elements and shows their relative sizes and proximity:
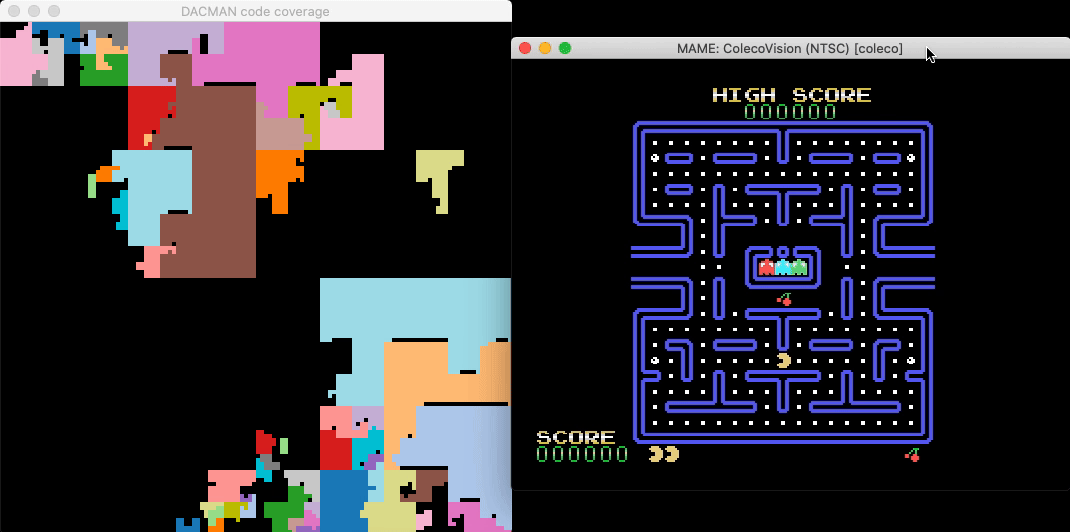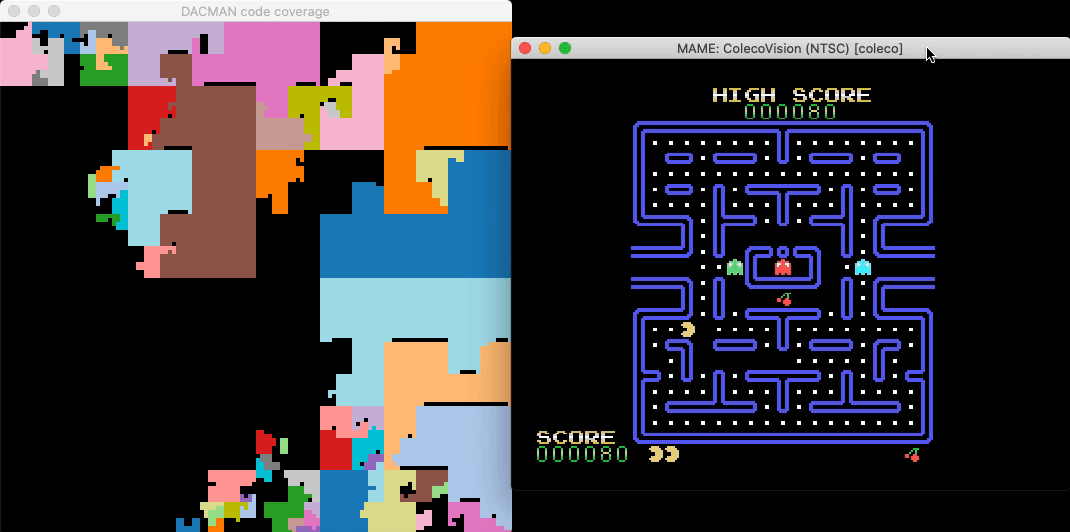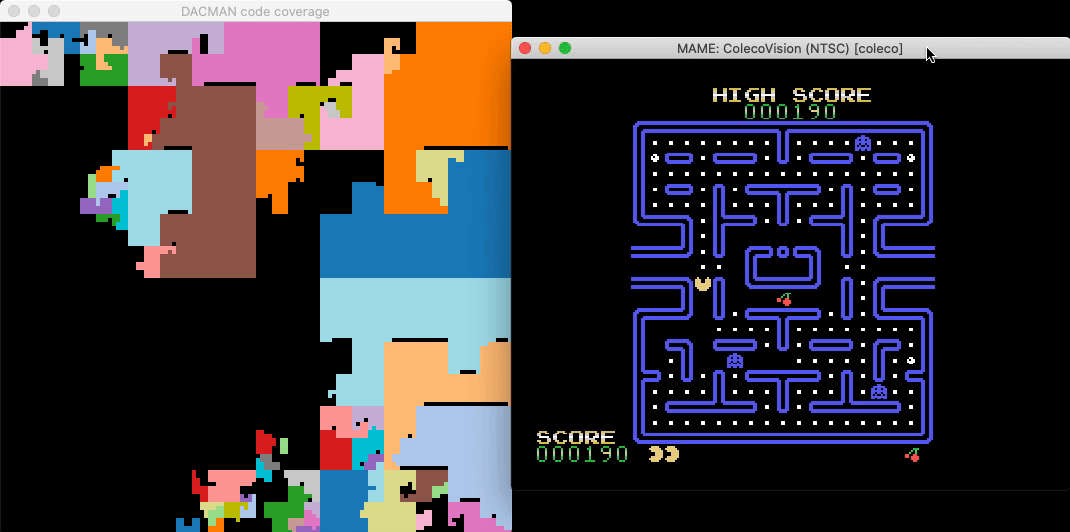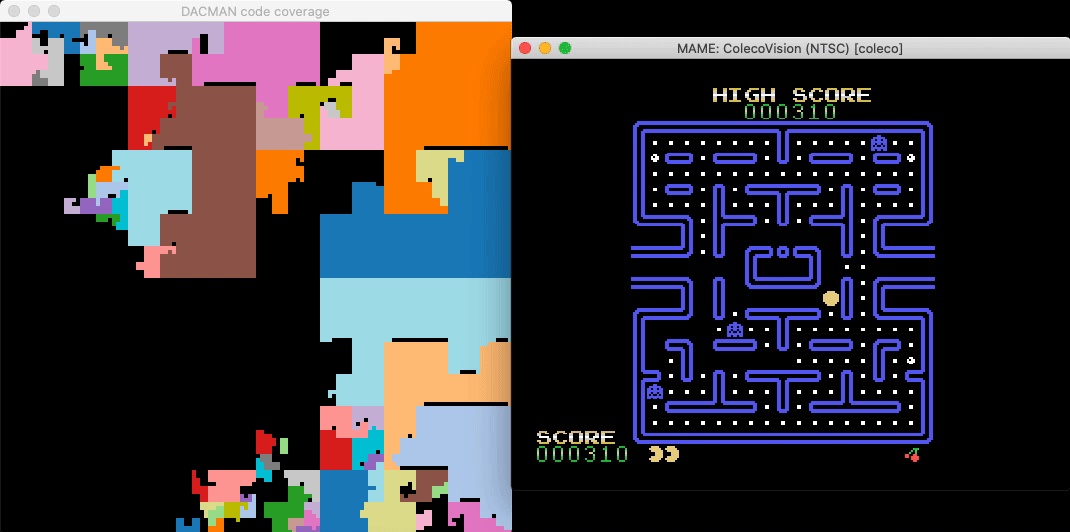
Count Opcodes
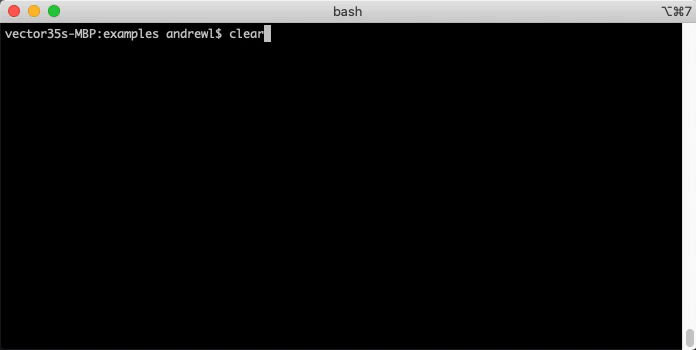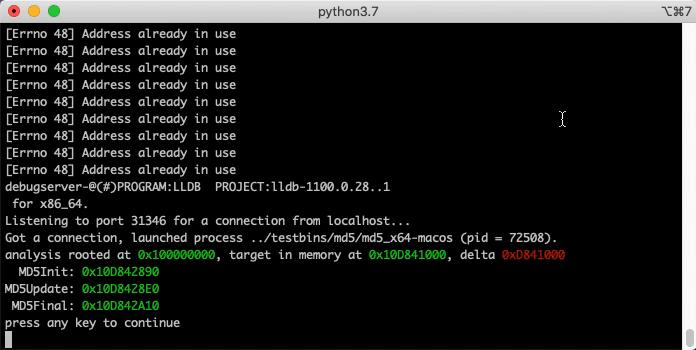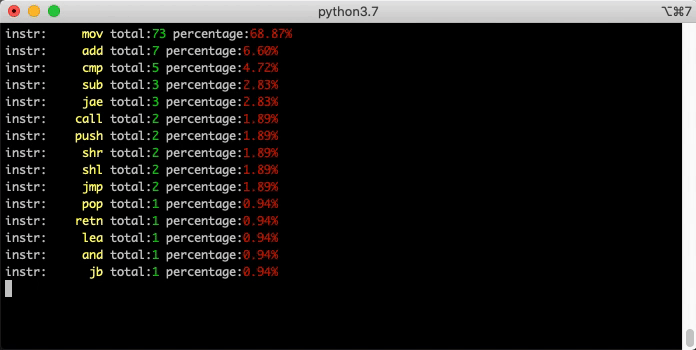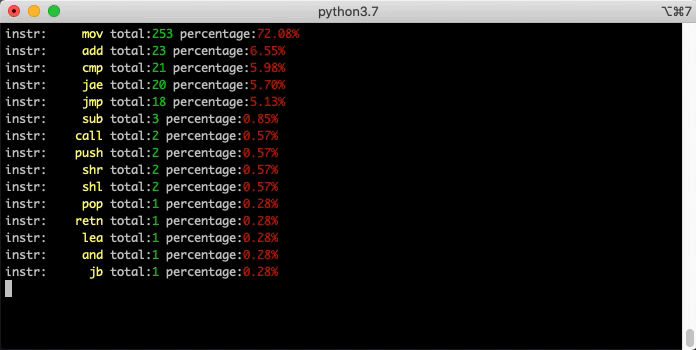
The UI is not the only consumer of BNDP’s API. You can write “headless” scripts too. Here’s a simple example that runs md5 and single-steps while counting all the opcodes executed:
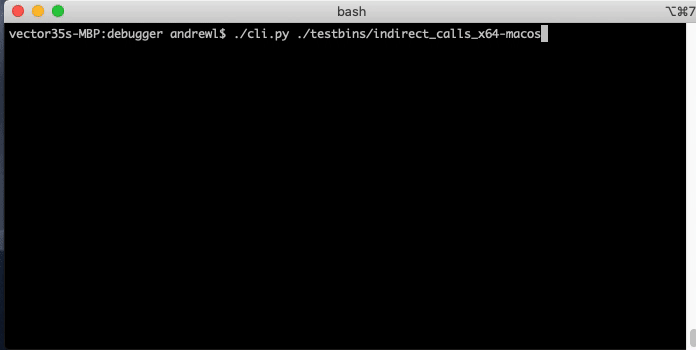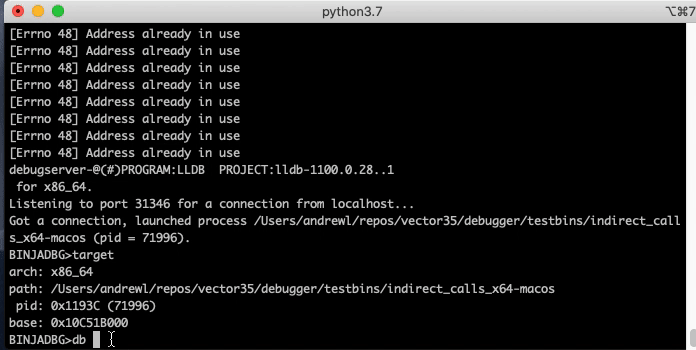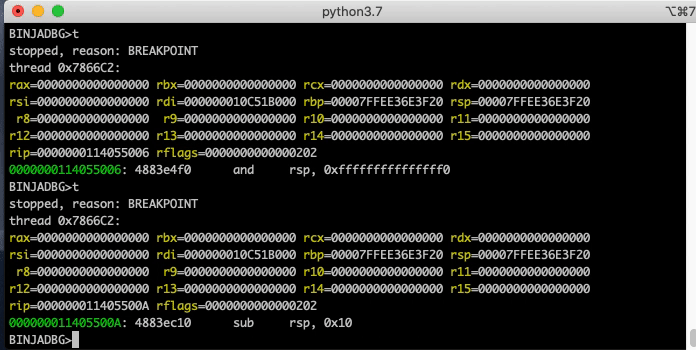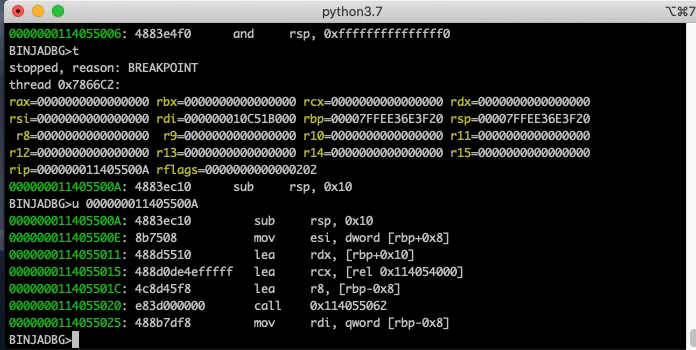
CLI Debugger
The headless API is complete enough that a respectable little CLI debugger can be made in a few hundred lines of code.
Design
Multiplatform Architecture
BNDP can connect to three back-ends: gdb, lldb, and dbgeng. The target is decoupled from BNDP in the first two modes, communicating using the RSP protocol over a socket. Theoretically any platform for which a gdb server exists can be debugged. In dbgeng mode, BNDP is runtime linked to Windows debugger engine and can debug local binaries.
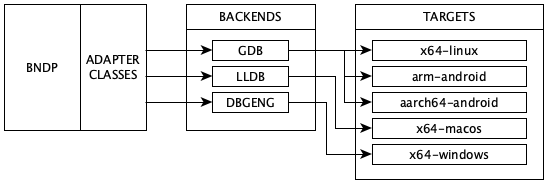
Supported Platforms
BNDP is tested on x64-linux, arm-android and aarch64-android binaries in gdb mode, x64-macos binaries in lldb mode, and x64-windows binaries in dbgeng mode.
You should have success on the 32-bit x86 versions of the above binaries, but they’re not as rigorously tested as 64-bit.
Adapter Classes: Generalizing Back-ends
Each of the adapters is expected to provide some primitive operations, like reading registers, stepping, breakpoints, etc. The comprehensive, but still short, list is the abstract functions in class DebugAdapter in DebugAdapter.py.
With classes and inheritance, we’re able to factor out common behavior among adapters. For instance, GDB and LLDB have much in common, with LLDB speaking an augmented RSP protocol. The current class diagram has plenty of room for an additional adapter and its corresponding back-end:
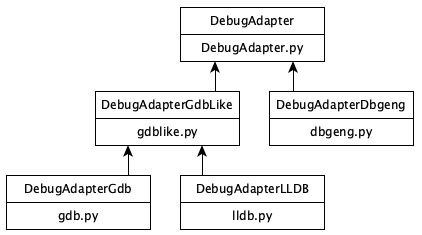
Higher level operations like “step over” are provided by some back-ends (like dbgeng) but not others (like gdb and lldb). For these, the operation is synthesized with primitive operations. “Step over” might involve disassembling to detect call or loop instructions and setting a one-shot breakpoint. “Go up” might involve reading the stack and setting a one-shot breakpoint at the return address.
Note that we intentionally did not write this blog post to be documentation on all features of the debugger, or a how-to guide for using it. Rather, we want to show what’s possible and talk about the design of the debugger. If you’re interested in simpler user documentation, keep an eye out on the project repository where we’ll post updated user documentation as it’s released.