One of the first steps a reverse engineer must take when statically analyzing a position-dependent raw firmware binary is to determine the base address of the image at runtime. Those who have had the pleasure of reversing a bootloader or raw embedded Linux kernel image understand that this can be a frustrating process of trial and error.
Today, we’re excited to unveil a new feature in Binary Ninja that aims to alleviate this challenge. Even better, this is available now in builds on our development channel!
Binary Ninja Base Address Scan Engine (BASE)
Binary Ninja 4.1 will introduce Base Address Scan Engine (BASE), a new feature that assists users in identifying the base address for raw position-dependent binaries. This feature has been incorporated into Triage View within the Binary Ninja UI and is also exposed through the API for batch, headless scripting. It runs analysis on the binary and uses a combination of techniques to ultimately present the user with a list of candidate base addresses. Once the user selects a base address, they can rebase the binary and run full analysis with a single click.
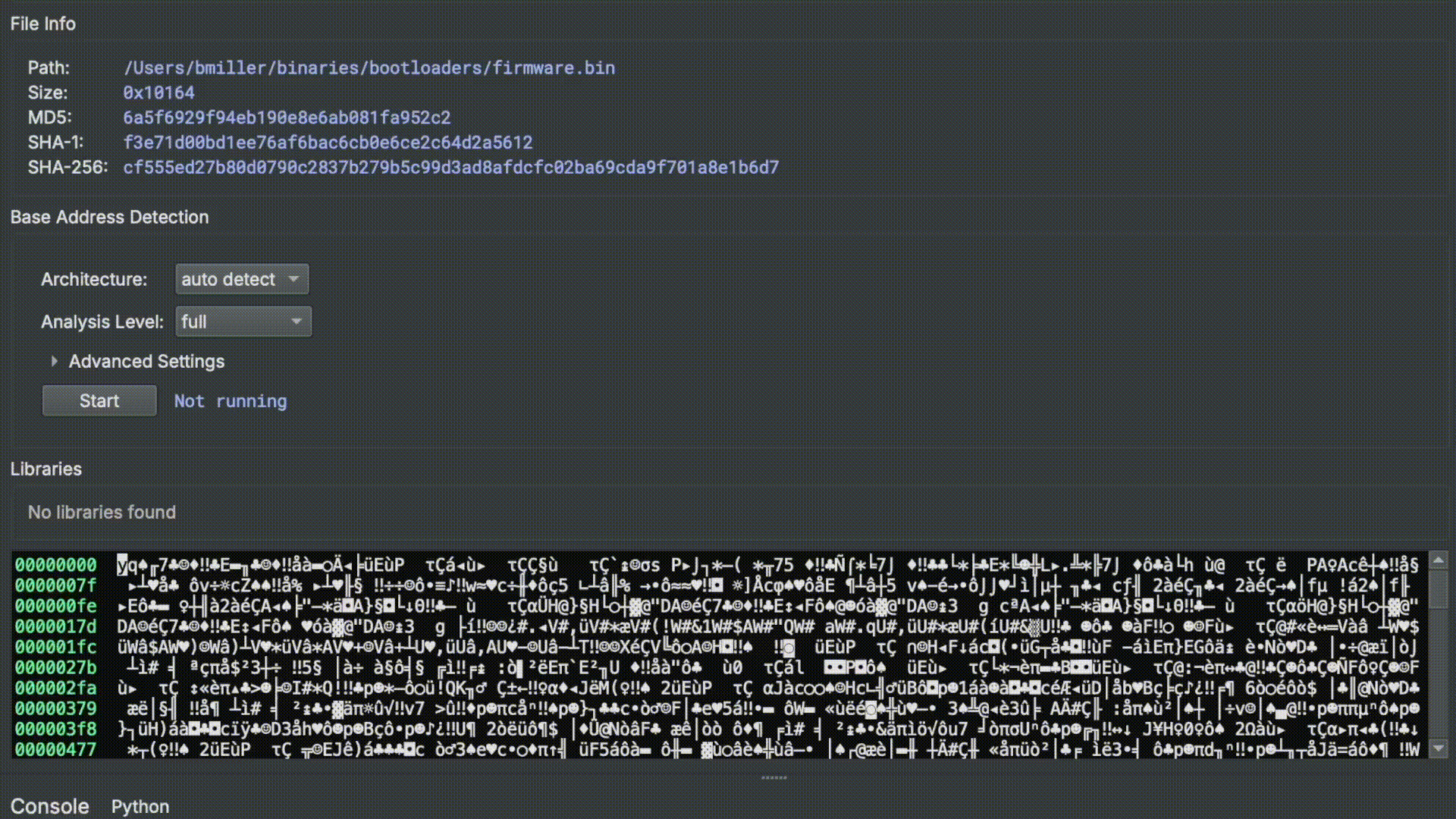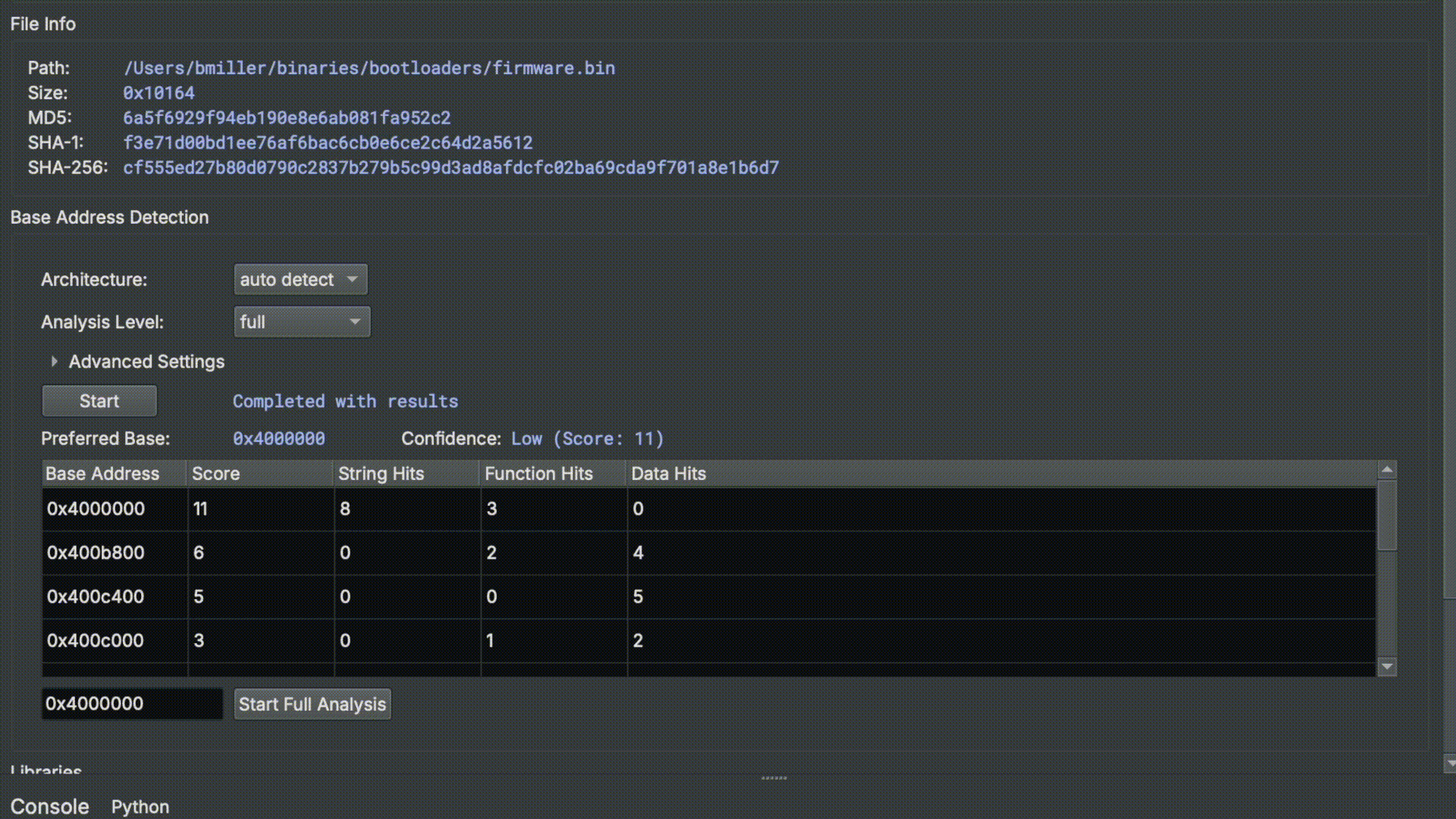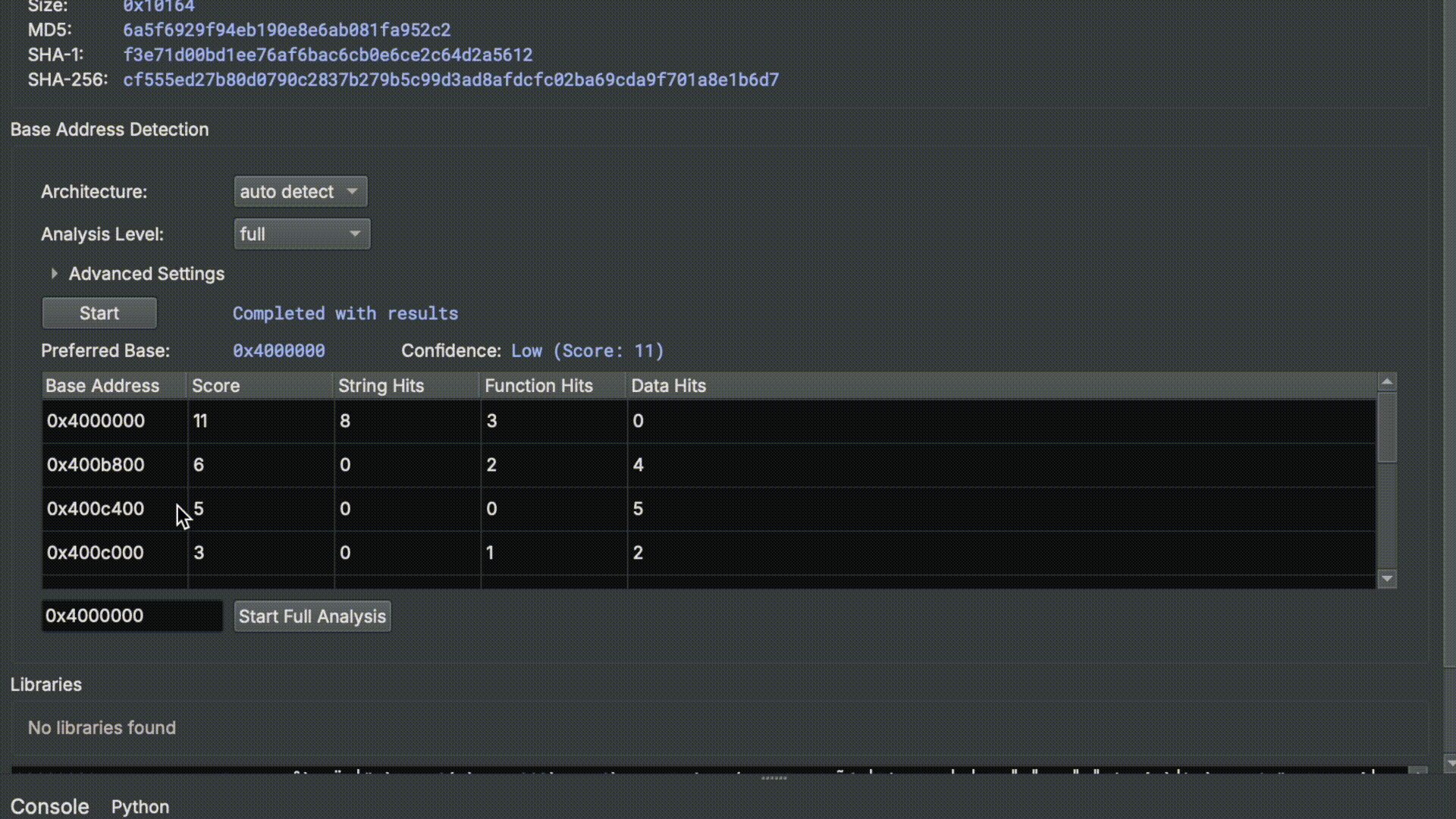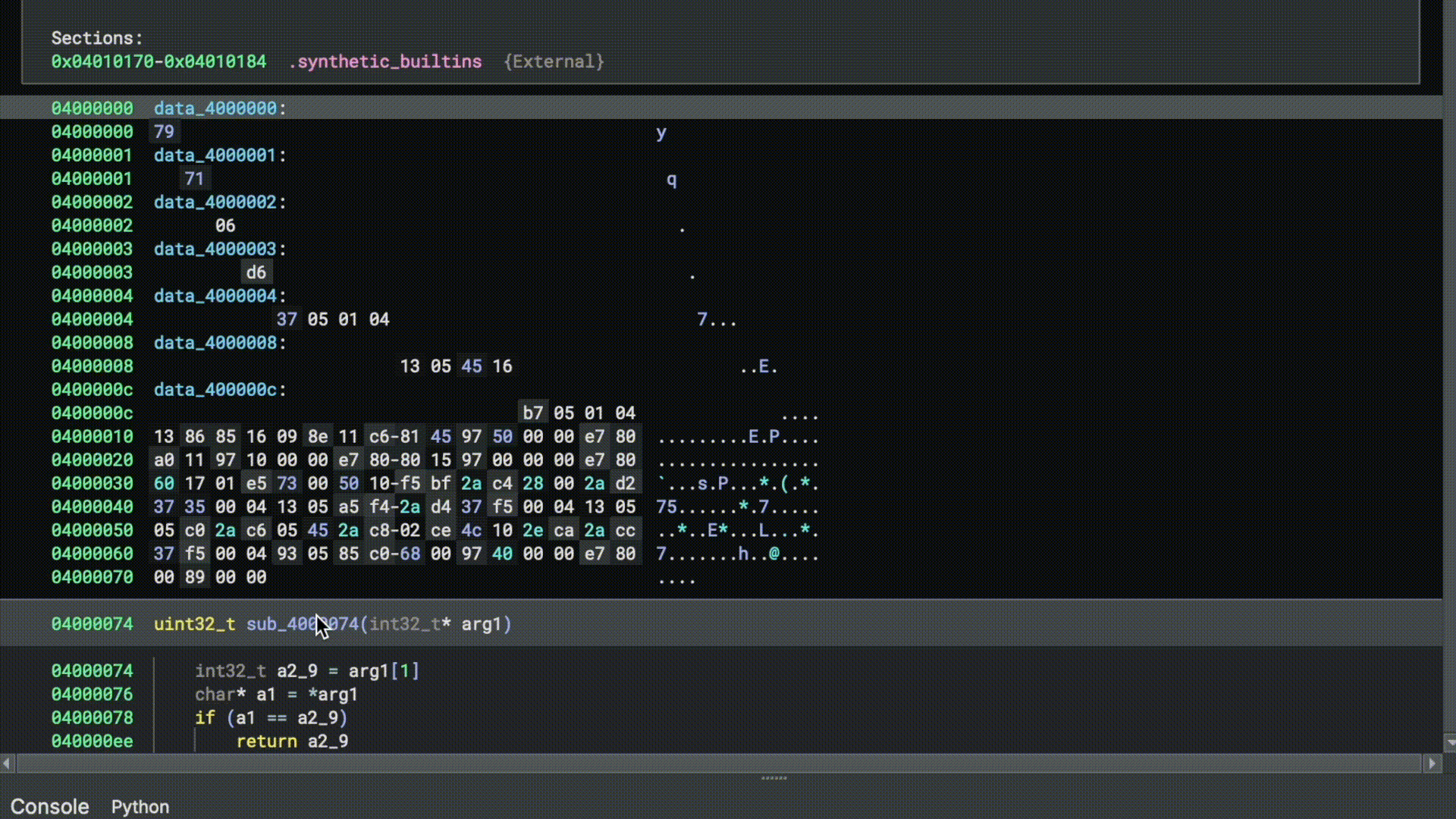
Position-dependent vs. Position-independent Programs
Before we dive into this new Binary Ninja feature, it is important to understand the differences between position-dependent and position-independent programs.
A position-independent program is built to run correctly regardless of where the binary lives in memory. It is able to compute pointers to strings, global variables, and functions dynamically, relative to the program counter (PC), or using relocations that are populated at runtime by a loader.
Position-dependent programs must run from a specific address in memory. The compiler can emit code that uses absolute addresses to reference strings, functions, and data variables and trust that they will be correct as long as the program is loaded at the correct base address.
Most user space programs that run on modern desktop operating systems are built position-independent. Latest clang, gcc,
and other compilers apply the --fPIC flag by default. These binaries are also in well-known file formats (ELF, PE,
Mach-O) and contain header information to tell the loader how and where to load the binary into memory. Discovering the
base address for these binaries is not a concern as Binary Ninja is able to parse header information and load the binary
at the correct base address for analysis.
Programs that run bare-metal in resource-constrained environments are often built position-dependent. They must be small to account for space constraints in non-volatile storage, and they must run more efficiently. They cannot afford to be built position-independent with extra instructions required to dynamically compute pointers relative to PC and there might not be a previous loader that can fix up runtime relocations. Therefore, they are in raw format and the entry point of the code often starts at the first byte of the file. Examples of these binaries include bootloaders, raw embedded Linux kernels, and monolithic Real-Time Operating Systems (RTOS). For these types of binaries, reverse engineers must determine the base address on their own, which is the basis for this new Binary Ninja feature.
Why the Base Address Matters
Without loading a position-dependent binary at the correct base address, pointers meant to reference strings, functions,
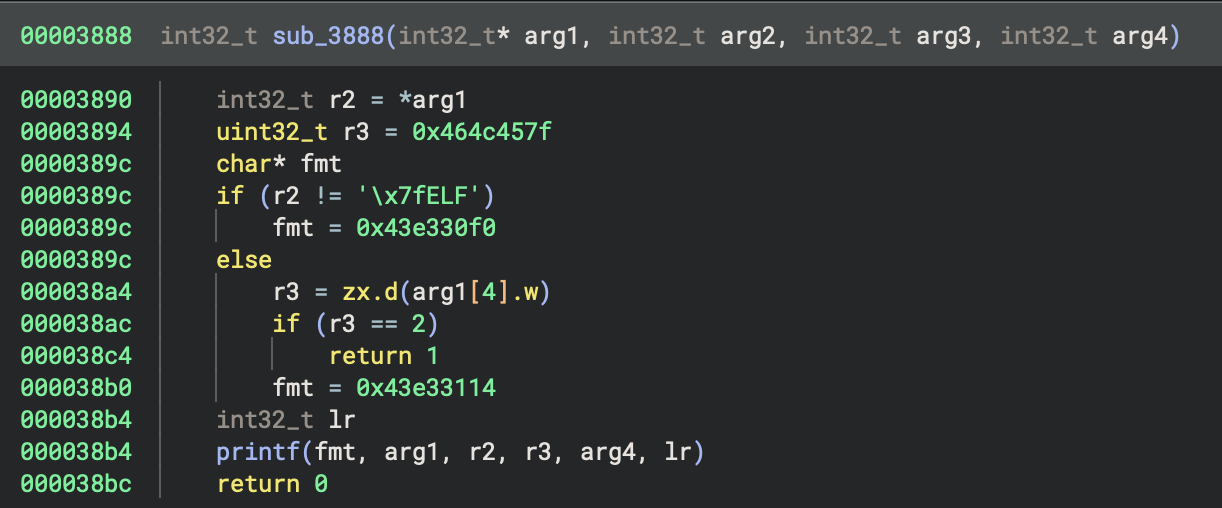
and data variables will point to incorrect locations. This severely limits analysis. Below is a simple example from a
Das U-Boot bootloader built for an ARMv7 platform. The binary is loaded at base address 0x00000000. The pointers,
meant to point to strings at 0x43e330f0 and 0x43e33114, point to memory regions that aren’t backed by the file.
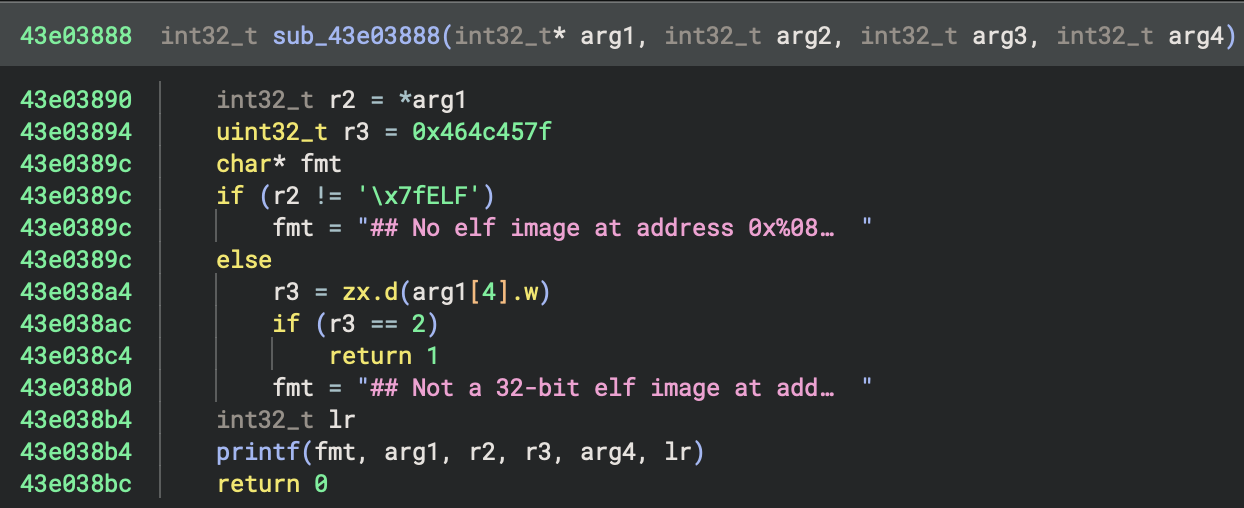
The image below depicts the same function, only the binary has been loaded at the correct base address. As a result, the pointers point to the correct location and Binary Ninja is able to resolve and display the referenced strings.
How does BASE work?
Binary Ninja’s base address scan engine (BASE) starts by loading the raw binary at 0x00000000 before running initial
analysis. Once initial analysis is complete, BASE builds a list of offsets for each “point-of-interest” (POI) in the
binary. A point-of-interest consists of a string, function, or data variable that could possibly be referenced by a
constant pointer value.
After BASE finishes building a list of POIs, it analyzes global data variables and BN Low Level IL (LLIL) instructions to identify instructions that are potentially computing pointers. Once these instructions are identified, BASE attempts to resolve the value of the pointer. Identified pointers are stashed in a list. It is important to understand that the pointer list is subject to false-positives and will likely contain some pointer-width integers that aren’t pointers at all. It can also contain pointers that are meant to reference memory regions that are not backed by the file.
Once all candidate pointers have been identified, BASE runs a clustering algorithm on the pointer list to group pointers that are within range of each other into separate lists. Pointer ranges are determined based on the size of the binary and are later used to compute search ranges. Below is an example of a reduced set of values from a BASE pointer list for a boot ROM firmware sample, prior to execution of the clustering algorithm.
[
0x04002f42, 0x00000000, 0x000002aa, 0x04004ecc,
0x04004eda, 0xfffff000, 0xffffff10, 0x0400e8b4,
0x0400e9d5, 0x0400eb84, 0x02001a3c, 0x02001b00,
0x0400ec18, 0x0400ecc4, 0x10000000, 0x50000000,
0x00001000, 0x00003c84, 0x0000401f, 0x000022f0,
]
Below is that same list of possible pointer values after it runs through BASE’s clustering algorithm. In this example,
the binary is 64K in size, so values that are within 64K of each other are grouped in the same cluster. Outlier values
that are not within range of any other value (such as 0x500000000 and 0x100000000) are filtered out. By clustering
pointers, it allows BASE to compute accurate search ranges and to skip memory ranges that don’t have any associated
pointers. This drastically speeds up the search and is especially important on 64-bit architectures where the base
address can reside anywhere between 0x0000000000000000 and 0xffffffffffffffff.
[
[
0x04002f42, 0x04004ecc, 0x04004eda, 0x0400e8b4,
0x0400e9d5, 0x0400eb84, 0x0400ec18, 0x0400ecc4,
],
[
0x00000000, 0x000002aa, 0x00001000, 0x000022f0,
0x00003c84, 0x0000401f
],
[
0xfffff000, 0xffffff10,
],
[
0x02001a3c, 0x02001b00,
],
]
After the pointers are grouped into clusters, those that contain a significantly low amount of pointers (relative to
the other clusters) are thrown away. The remaining groups of potential pointer values are used to compute search ranges.
In this example, (2) clusters are ignored, leaving the clusters containing values in the 0x04002f42-0x0400ecc4 and
0x00000000-0x0000401f ranges. From these values, BASE computes base address search ranges. It is possible that only a
portion of the pointer values in a cluster are meant to point to a file-backed string, function, or data variable.
Therefore, BASE computes a search range that is slightly wider than the range of pointers in a cluster. In this example,
BASE computes a search range of 0x3ffac00-0x4018000 for the cluster containing pointers from 0x04002f42-0x0400ecc4.
This is based on the file size and the alignment settings.
After computing search ranges, BASE uses a scanning technique to determine how many pointers point to points-of-interest
(strings, functions, and data variables) at each candidate base address. It iterates through the base address search
range by incrementing the base address by the alignment value (1024 by default). At each base address, it checks every
pointer from the assigned cluster against every POI offset. BASE maintains a count of the total number of pointers that
align with POI offsets at each base address. The top 10 base addresses that contain the highest scores are presented to
the user as candidates. The diagram below is intended to describe the concept. On the left, the base address is set to
0x3fffc00. With the binary based at 0x3fffc00, no pointers in the cluster align with points-of-interest in the
binary. On the right, the binary is based at 0x4000000. At this base address, (5) pointers in the cluster align with
points-of-interest in the binary.

Advanced Settings
Triage View’s base address scan engine consists of advanced settings containing default values. The user can override
these settings to refine analysis. There are scenarios where adjusting an advanced setting is ideal. For example, if the
user knows the binary is an ARM 32-bit Linux kernel, and they know the OS page size is 4096 bytes, then it is safe to
assume that the kernel is loaded on a 4096 byte page boundary. Therefore, the alignment setting should be overridden to
0n4096. The default value of 0n1024 will work, but it will test 75% more base addresses, unnecessarily. Likewise,
the user can increase the lower boundary to 0xc00000000, which is the standard for the start of the virtual address
range for 32-bit Linux kernels. The table below provides a brief description of each advanced setting.
| Setting | Description | Default |
|---|---|---|
| Min. String Length | Minimum length of string to be considered a point-of-interest | 0n10 |
| Alignment | Byte boundary to align the base address while scanning | 0n1024 |
| Lower Boundary | Lowest address to begin search for candidate base address | 0x0 |
| Upper Boundary | Highest address to end search for candidate base address | 0xffffffffffffffff |
| Points of Interest | Specifies types of points-of-interest to use for analysis (all, strings only, functions only) | All |
| Max Pointers | Maximum amount of pointers to allow in each pointer cluster | 0n128 |
BASE API
New Python and C++ classes have been added to the Binary Ninja API along with a python script, named
raw_binary_base_detection.py,
that demonstrates usage.
Python 3.12.3 (main, Apr 9 2024, 08:09:14) [Clang 15.0.0 (clang-1500.3.9.4)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> from binaryninja import *
>>> bad = BaseAddressDetection("u-boot-armv7.bin")
>>> bad.detect_base_address()
True
>>> hex(bad.preferred_base_address)
'0x43e00000'
>>> for addr, score in bad.scores:
... print(f"{hex(addr)} => {score}")
...
0x43e00000 => 86
0x43f4b400 => 8
0x43f44c00 => 8
0x43e00c00 => 8
0x43df5400 => 8
0x43df8c00 => 7
0x43f7cc00 => 6
0x43e14800 => 6
0x43e0b400 => 6
0x43dfd800 => 6
raw_binary_base_detection.py can run against a single position-dependent raw binary or a directory containing multiple
binary samples. It outputs results of base detection analysis to stdout in JSON format. Below is example output after
running the script against an AArch64 Apple iPhone boot ROM.
{
"filename": "SecureROM for t8015si, iBoot-3332.0.0.1.23",
"preferred_candidate": {
"address": "0x100000000",
"confidence": 1
},
"aborted": false,
"last_tested": "0xfffffffffffe0000",
"candidates": {
"0x100000000": {
"score": 6,
"function hits": 4,
"string hits": 1,
"data hits": 0
},
"0x80000000": {
"score": 6,
"function hits": 6,
"string hits": 0,
"data hits": 0
},
"0x7fff9400": {
"score": 6,
"function hits": 6,
"string hits": 0,
"data hits": 0
},
"0x0": {
"score": 6,
"function hits": 5,
"string hits": 0,
"data hits": 0
},
"0x7fff8800": {
"score": 5,
"function hits": 5,
"string hits": 0,
"data hits": 0
},
"0x80008000": {
"score": 4,
"function hits": 3,
"string hits": 0,
"data hits": 0
},
"0x7ffffc00": {
"score": 4,
"function hits": 4,
"string hits": 0,
"data hits": 0
},
"0x7fffe400": {
"score": 4,
"function hits": 4,
"string hits": 0,
"data hits": 0
},
"0x7fff8c00": {
"score": 4,
"function hits": 4,
"string hits": 0,
"data hits": 0
},
"0x7fff7800": {
"score": 4,
"function hits": 4,
"string hits": 0,
"data hits": 0
}
}
}
Open Source Alternatives
There are many great open source tools for base address recovery. Like Binary Ninja BASE, each tool has its own limitations. Some of these tools take a scanning approach, while others attempt to determine the base address by detecting intersections between discovered 32-bit or 64-bit values. Below is a list of honorable mentions:
- Binbloom - fast and accurate for binaries with a large amount of
global pointers and strings; supports 32-bit and 64-bit
- Ineffective against binary samples without strings or global pointer values
- allyourbase.py - creative approach that also works well on binaries
containing strings and global pointers; supports 32-bit and 64-bit
- Similar limitations as Binbloom
- FirmXRay - takes similar approach as BN BASE; uses Ghidra for code analysis
- 32-bit ARM support only; code heuristics operate on ARM assembly text
- rbasefind - scanning approach that discovers intersection of 32-bit words
- Reliant on strings and global pointers; 32-bit only
These tools use strings exclusively for points-of-interest and have limited ability to auto-detect architecture endianness and pointer-width. Except for FirmXRay, they are unable to identify pointer values that are computed by code at runtime. One characteristic that all these tools have in common is that they are only as good as their ability to discover pointers. This is where BN BASE has a slight advantage, since its heuristics leverage Binary Ninja IL for pointer discovery. With that said, many of the open source tools work great on the right firmware samples, and they all directly contributed to the design of BN BASE.
Try it Out!
Binary Ninja Base Address Scan Engine is set to debut alongside the release of Binary Ninja 4.1. You can purchase Binary Ninja here. Existing customers have the option to switch to the development update channel for early access to this feature. Once you’ve loaded a raw position-dependent binary, simply navigate to Triage view and give it a try! Share your feedback with us on the Binary Ninja public slack.