It’s been a long time coming, but it’s finally here! Version 1.2 of Binary Ninja launches today with a huge list of improvements. There’s so many features that we’re splitting this blog post into three pieces. This post covers half of the changes that have happened since the last stable release back in May. The next post will cover the remaining features from the last stable, and the third will be a higher level overview of everything that’s happened since 1.1 from two years ago.
We’re not covering all bugs fixed to keep this from turning into a full-length novel. For more details, you can always check the list of closed issues.
Highlights
If you just want the highlights, here’s a short list of some of the most noticeable new features:
- Tags/Bookmarks System
- Type Library System and Type Libraries
- Plugin Manager
- Analysis Caching now in Personal
- Enhanced Settings System
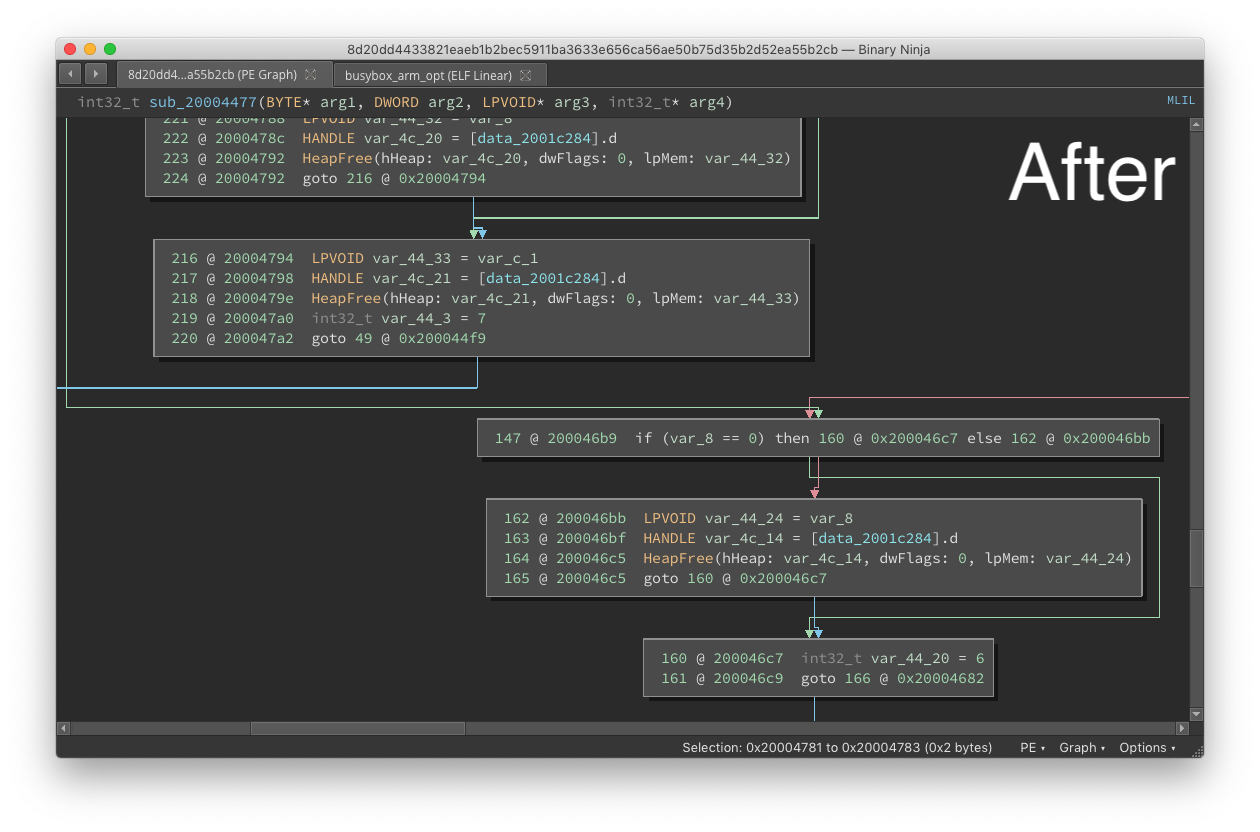
Tags
The new tags system grew out of a common request for some sort of bookmark set/navigate hot-keys. We could have just implemented a simple hot-key bookmark system (indeed, with UI plugins this has been possible for some time now).
Instead, we wanted to build a more robust feature. What resulted is the Tags API. This new API allows for a simple bookmark system but also much more complex Tags system. Consider, for example, taking the results of a large scale fuzzing job and annotating all crashing locations in a binary with a Tag indicating not only the type of crash but also some additional context such as the register state at the moment of crash.
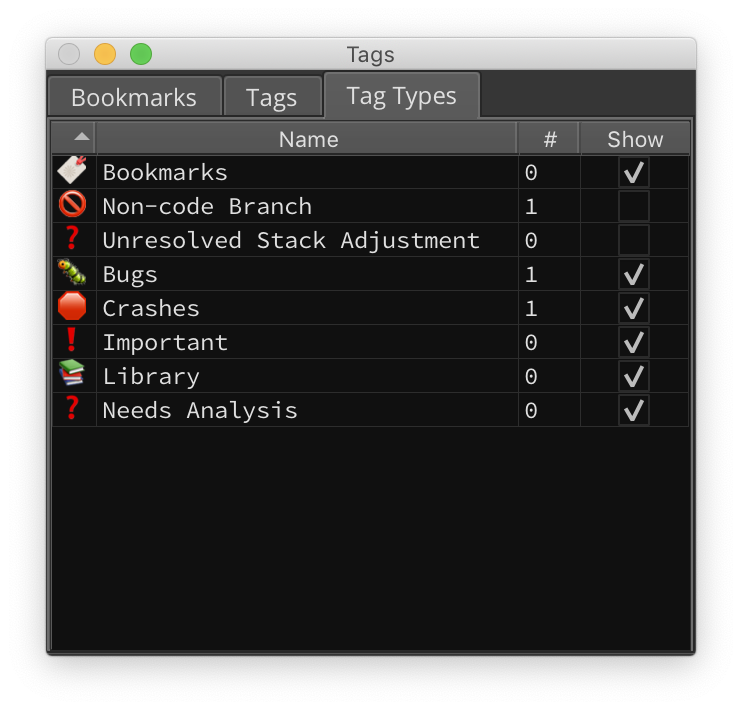 Tag Types - Figure 1
Tag Types - Figure 1
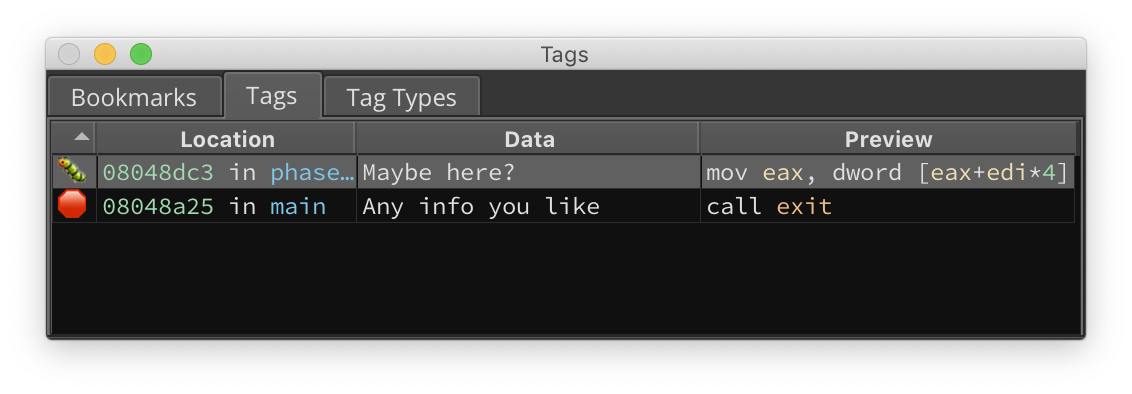 List of all tags - Figure 2
List of all tags - Figure 2
To get you started, we’ve built in several different types of tags by default, but you can of course make your own by right-clicking in the “Tag Types” window. Once you’ve decided which type to use, just right-click and select Add Tags from the context-menu. And of course, there are many new APIs for tags, but you’ll most likely want to use create_user_data_tag for data that’s not in a function, create_user_address_tag for addresses inside functions, or create_user_function_tag for tags on functions themselves. They’ll all show in the UI, but this gives plugin authors a bit more control about the types of tags they are creating.
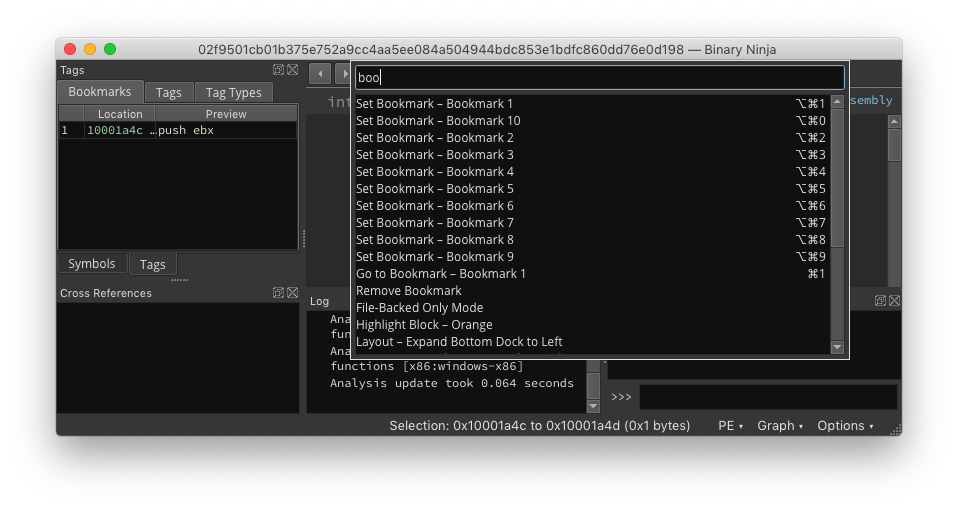 Adding Bookmarks - Figure 3
Adding Bookmarks - Figure 3
And of course, bookmarks can be easily added and navigated to with a built-in set of hot-keys (CTL/CMD + ALT/OPTION + [Number])
Type Libraries
 Malware Sample Without Type Library - Figure 4
Malware Sample Without Type Library - Figure 4
 Malware Sample with Type Library - Figure 5
Malware Sample with Type Library - Figure 5
One of the most frequently requested features in 1.2, support for type libraries is finally here! The built-in library itself is still fairly sparse, containing ws2_32, advapi32, and kernel32 on x86. More architectures, platforms, and libraries are coming soon.
You can also easily make your own type libraries, check back here for a forthcoming blog that will go into more detail on how you can extend the built-in libraries with your own.
Plugin Manager
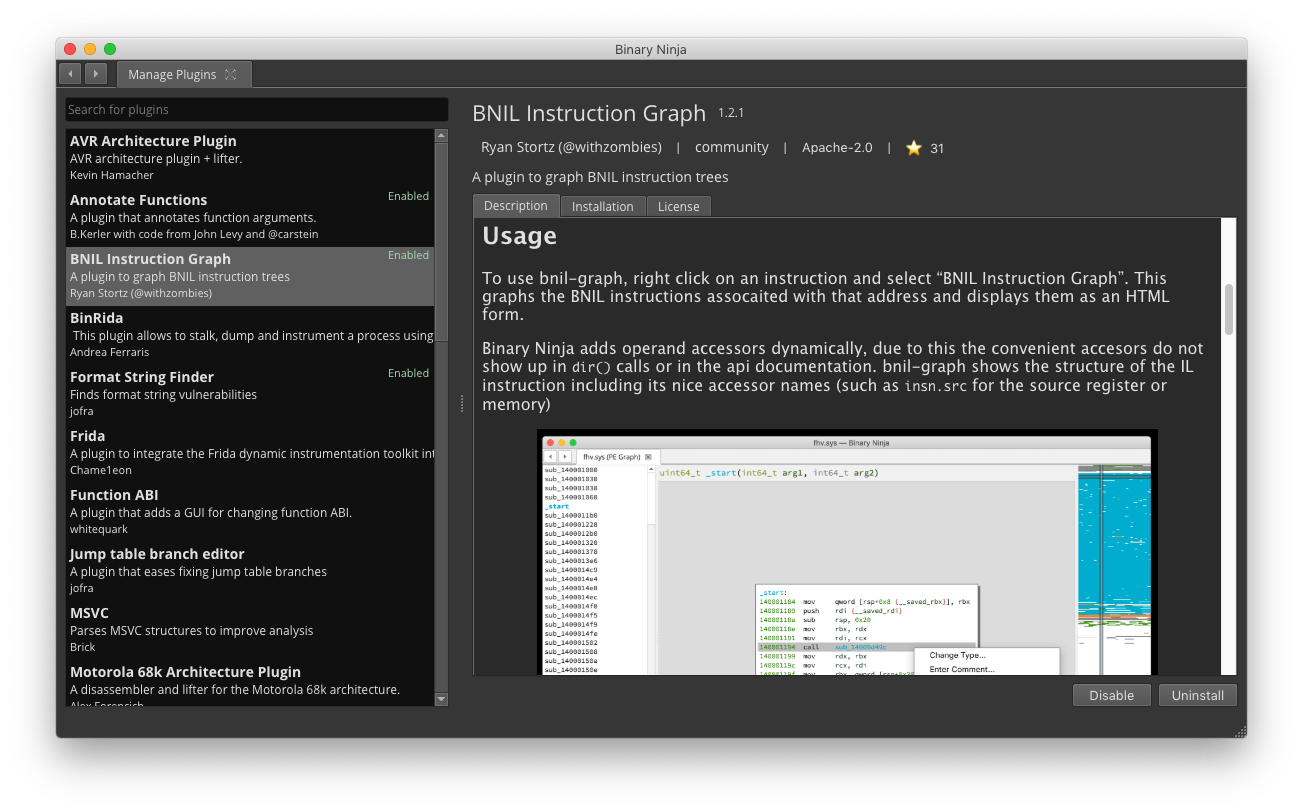 Plugin Manager - Figure 6
Plugin Manager - Figure 6
We’ve had our community repository of plugins for several years now since we know it’s important to encourage a healthy ecosystem of plugins that are actively maintained. And now in 1.2, it’s even easier to discover and install plugins. Access the plugin manager via (CMD/CTL + M), or via the command-palette as Manage Plugins.
Not only can you search for plugins you might want to install, but you can see their documentation (including any animated images thanks to the new QWebEngine integration) and install them with one click. The plugin manager has several tricks hidden in its search bar as well. You can use a number of keywords such as @installed or others to search for plugins in a particular state or category.
Analysis Caching
We’ve always planned to roll-down features from Commercial into our Student/Non-commercial version and during this last stable we went ahead and did just that. Analysis caching makes opening existing bndb’s significantly faster by caching much of the analysis data. This is particularly important when working with large binaries.
Enhanced Settings System
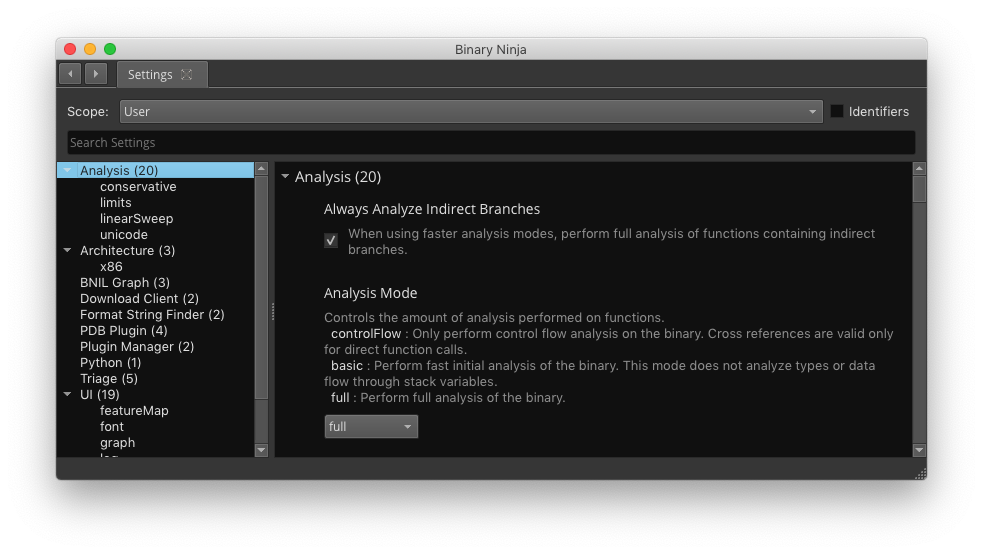 Ehanced Settings System - Figure 7
Ehanced Settings System - Figure 7
Our settings system has had a complete overhaul. Instead of the small preferences dialog in addition to the more expansive advanced settings, we now have a unified Settings UI where all settings can be searched. These settings can be specific to a single Binary View, globally for the user, and also come with defaults you can always revert to.
Open with Options
The ability to open a binary has been enhanced with the addition of Load Options. Load Options allow for the creation of a BinaryView with user modifiable settings. The available settings are also customizable by the BinaryViewType that is responsible for creating the BinaryView.
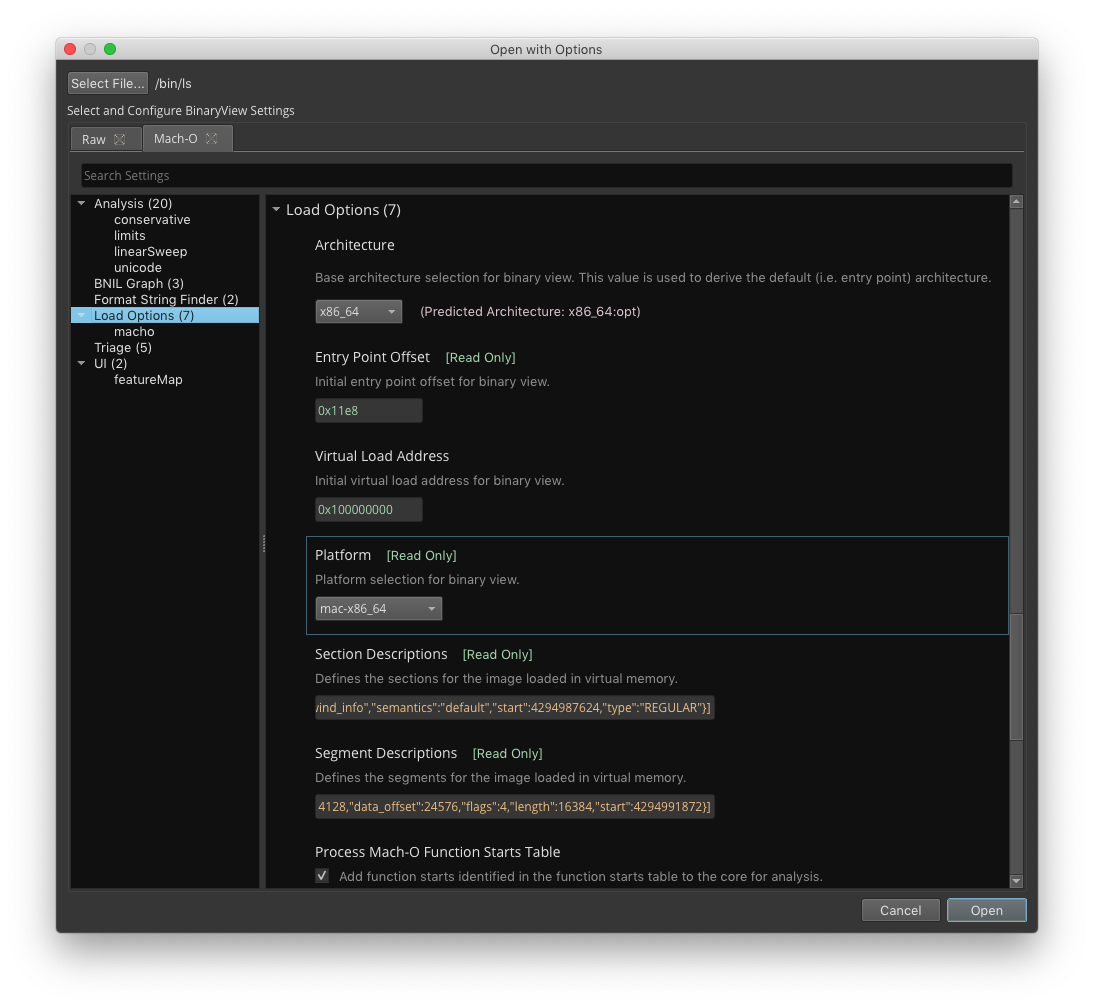 Load Options - Figure 8
Load Options - Figure 8
Support for Loading Raw Binaries
The addition of the “Mapped” BinaryViewType allows for the loading of raw binaries. One can quickly open an image and specify the architecture, entry point, load address, and load map (segments/sections) for a binary.
Image Base Configuration
It is now possible to load a binary that is relocatable at a custom load address. Customizable load addresses are supported for ELF, Mach-O, PE, Mapped, and even custom BinaryViewTypes. Of course you can always rebase a raw file format as well.
Note: Currently rebasing is only available on initial image load. Rebasing existing Binary Ninja databases (bndb’s) and dynamic rebasing is coming to dev soon!
Architecture Detection
We’ve added the ability to automatically detect the architecture of a binary blob which can be especially helpful for unknown firmware. This feature is currently used during the Open with Options operation and provides default architecture selection and/or hints through the Load Options.
Extensible Load Option Support
Our API’s now enable custom load options to be provided during the BinaryView creation process. For example, Mach-O BinaryViewTypes provide a setting to optionally process the function starts segment of a Mach-O image. This enables BinaryViewType creators to provide fine-grained control over the image load process.
Other Improvements
The remaining improvements we’ve split into several categories. The first two categories are coming in this post and the remaining will be coming in Part 2 later this week:
File Formats
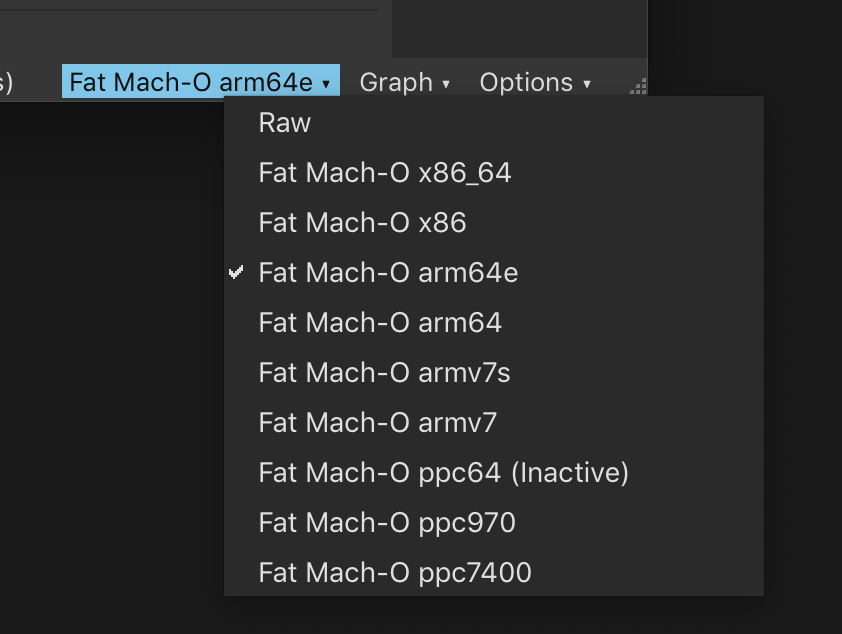 Mach-O FAT - Figure 9
Mach-O FAT - Figure 9
- Feature: Fat Mach-O support – Mach-O FAT files can be opened and each individual architecture will load as a separate BinaryView available from the bottom-right view selection menu.
- Fix: Improved handling of some malformed PE headers (Flare-On challenge #5)
Analysis
- Feature: User-defined cross-references – can be used, for example, to annotation an indirect control flow branch with information from dynamic analysis
- Feature: Large database support (no file size limit) – chunking sqlite records means bndb files can now be larger than your hard drive
- Feature: Heuristic branch-table clamping – substantial improvements for some jump table range detection, prevents a few malformed cases from going off the rails
- Fix: Many data-flow/value-set analysis improvements
- Fix: Linear-sweep performance and accuracy improvements – Our linear sweep improves with each release. We are using the term “linear sweep” in this context to mean our heuristic function start detector, not “linear disassembly of bytes”. In this most recent stable, we not only incorporated entropy-based heuristics, but also added a number of other improvements. Some test binaries improved analysis times by an order of magnitude while retaining (or improving) their previous accuracy. Keep an eye out for a forthcoming blog with hard numbers and samples for both accuracy and performance!
- Fix: Resolved a performance issue in binaries with large symbol tables – was due to the number of updates in the UI to the function list.
- Fix: Improved function type parameter detection and propagation – especially important because of the new type library support!
- Fix: Large reduction in analysis non-determinism – different function analysis order (always possible with a truly multi-threaded analysis) could result in non-deterministic analysis. This change minimizes, but does not eliminate potential problems with function analysis ordering.