
Lifting is the critical step to unlocking Binary Ninja’s powerful analysis and decompilation. Often the “left as an exercise to the reader” of Binary Ninja custom architecture tutorials, it is both a lengthy process and one with a lot of subtlety. From simple instructions to flags and intrinsics, the lifting process describes the behavior of every instruction. Let’s write a lifter for Quark!
Contents
This is Part 2 of a three-part series. Here is the full list of contents:
Recap
In Part 1, we covered the basics of disassembly. We implemented trivial control flow recovery, patching, and even added an assembler. Thanks to Binary Ninja’s built-in ELF loader, we were able to skip writing a file format loader and spent the entire time turning instructions into tokens.
Lifting
To write a lifter, we need to implement get_instruction_low_level_il. The lifter needs the same information as the disassembler, so the scaffolding is very similar:
def get_instruction_low_level_il(self, data: bytes, addr: int, il: LowLevelILFunction) -> Optional[int]:
info = QuarkInstruction(int.from_bytes(data, 'little'))
op = QuarkOpcode(info.op)
match op:
# Regular ops here
case QuarkOpcode.integer_group:
int_op = QuarkIntegerOpcode(info.b)
match int_op:
# Integer ops have their own group
case _:
il.append(il.unimplemented())
case QuarkOpcode.cmp:
cmp_op = QuarkCompareOpcode(info.b & 7)
match cmp_op:
# Comparison ops have their own group
case _:
il.append(il.unimplemented())
case QuarkOpcode.icmp:
cmp_op = QuarkCompareOpcode(info.b & 7)
match cmp_op:
case _:
il.append(il.unimplemented())
case _:
il.append(il.unimplemented())
return 4
From here, implementing the lifter involves going through every instruction in the disassembly and translating it into IL expressions, trying to keep it simple. Most operations in Quark translate cleanly into Low Level IL, though there are some weird outliers. Below we documented the cases we ran into while writing this, which hopefully covers anything you might run into.
Basics
It is easier to understand lifters when there are helper functions that reduce the size of the code in each case. Given that, we will write a few helpers for looking up registers based on how the instructions usually operate.
# Get name of register in `a` component of instruction
def ra():
# sanity: make sure we don't lift anything that references ip directly
assert info.a != self.ip_reg_index, "Can't handle ip"
return il.arch.get_reg_name(info.a)
# Get expression to get the register in `a` component of instruction
def ra_expr():
# Special case ip register by emitting a constant with its value
if info.a == self.ip_reg_index: # ip
return il.const(4, addr + 4)
return il.reg(4, il.arch.get_reg_name(info.a))
# Same exists for `b`, `c`, and `d` components of the instruction
We will also implement a helper for cval, the Quark equivalent of more complicated constant value and addressing mode encodings found in other architectures.
def cval():
if info.largeimm:
return il.const(4, info.imm11)
elif info.smallimm:
return il.const(4, rol(info.imm5, info.d))
else:
if info.d == 0:
return rc_expr()
il.append(il.set_reg(4, LLIL_TEMP(0), il.shift_left(4, rc_expr(), il.const(4, info.d))))
return il.reg(4, LLIL_TEMP(0))
Having these helper functions available made the rest of lifting significantly more terse and easy to understand. The power of being able to fit an entire instruction’s IL in one line cannot be understated.
With all of this scaffolding in place, it’s time to start implementing instructions. We do this by grouping instructions into similar behaviors and writing lifter code for them, one at a time. Since every instruction is currently lifted as unimplemented, we can use the Tags sidebar to see which instructions we have yet to implement.
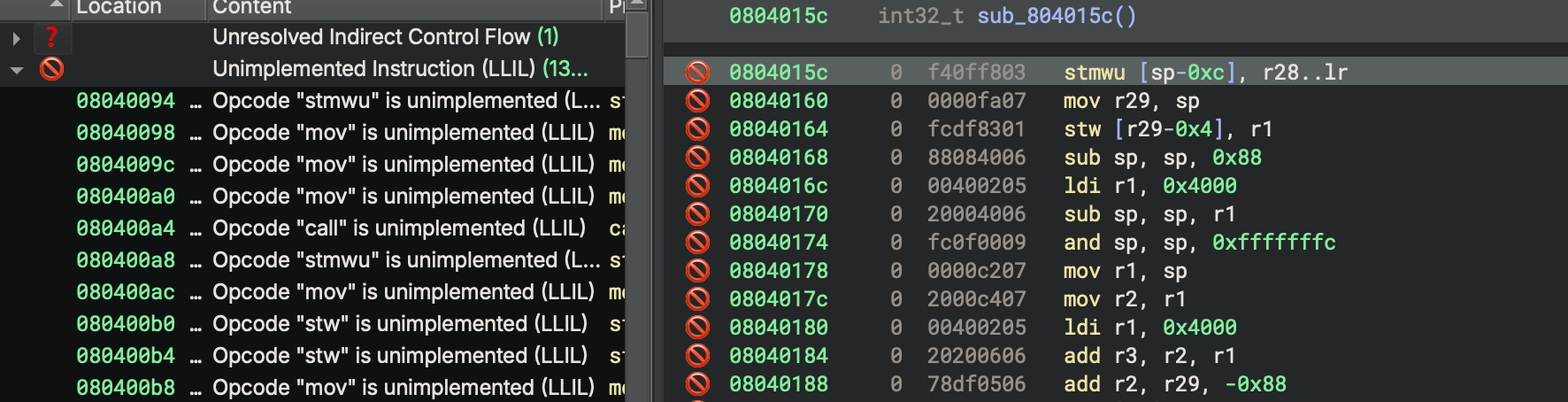 Tags sidebar showing unimplemented instructions
Tags sidebar showing unimplemented instructions
Loads and Stores
Load and store instructions are the main way stack variables are used, and Quark has a decent number of them. Their general format is pretty simple, though you should be careful to insert zx and low_part instructions to extend and shrink value sizes to match memory/register sizes. There are a couple of details here:
- Check the semantics on loads smaller than the register width, and whether they zero or ignore the upper bits in the existing register
- Quark has “load and update” instructions that increment the source register. We’ve chosen to lift these using a temporary register, as the VM does the update prior to the load.
- Loads into registers should check for loads to
ip, as lifting those as with direct register access will not have any effect on control flow. They need to instead be lifted as jumps. To make this blog easier to read, we’ve left these as calls toil.set_reghere. See the section at the end for how we handled this in practice. - Complicated addressing modes may be better to lift with temporary registers. While it’s valid to lift complicated statements to deeply nested LLIL expressions, certain optimizations don’t traverse deep expression trees and will fail unless you split expressions into sequences of more simple instructions.
Here are a few examples of how we lift these:
case QuarkOpcode.ldb: # Load byte
il.append(il.set_reg(4, ra(), il.zero_extend(4, il.load(1, il.add(4, rb_expr(), cval())))))
case QuarkOpcode.ldw: # Load word
il.append(il.set_reg(4, ra(), il.load(4, il.add(4, rb_expr(), cval()))))
case QuarkOpcode.ldbu: # Load byte and update source, inc by 1
addr = LLIL_TEMP(1)
il.append(il.set_reg(4, addr, il.add(4, rb_expr(), cval())))
il.append(il.set_reg(4, rb(), il.add(4, il.reg(4, addr), il.const(4, 1))))
il.append(il.set_reg(4, ra(), il.zero_extend(4, il.load(1, il.reg(4, addr)))))
case QuarkOpcode.ldi: # Load immediate
il.append(il.set_reg(4, ra(), il.const(4, info.imm17)))
case QuarkOpcode.ldih: # Load immediate high
il.append(il.set_reg(4, ra(), il.or_expr(4, il.zero_extend(4, il.low_part(2, ra_expr())), il.const(4, info.immhi))))
case QuarkOpcode.stb: # Store byte
il.append(il.store(1, il.add(4, rb_expr(), cval()), il.low_part(1, ra_expr())))
case QuarkOpcode.stw: # Store word
il.append(il.store(4, il.add(4, rb_expr(), cval()), ra_expr()))
case QuarkOpcode.integer_group:
int_op = QuarkIntegerOpcode(info.b)
match int_op:
case QuarkIntegerOpcode.mov: # Move into register
if info.a == self.ip_reg_index: # mov to ip is a jump
il.append(il.jump(cval()))
else:
il.append(il.set_reg(4, ra(), cval()))
Calls
Quark uses a Link Register to enable subroutine calls. We informed Binary Ninja about this previously when we set up the Architecture class:
class QuarkArch(Architecture):
# ...
link_reg = 'lr'
We should not model the lr behavior at call sites ourselves. All we need to do is emit the call instruction and Binary Ninja will understand that lr gets the return address written to it. Some architectures implement call by pushing the return address onto the stack and then jumping to the target. Lifting these looks identical: you do not need to model the stack push behavior. Lifting call is then simple. All you need to do is calculate the proper target address:
match op:
case QuarkOpcode.call: # direct call
il.append(il.call(il.const(4, addr + 4 + (info.imm22 << 2))))
case QuarkOpcode.integer_group:
int_op = QuarkIntegerOpcode(info.b)
match int_op:
case QuarkIntegerOpcode.call: # indirect call
addr = LLIL_TEMP(1)
il.append(il.set_reg(4, addr, ra_expr()))
il.append(il.call(il.reg(4, addr)))
For indirect calls, we opted to write the address to a temporary register prior to the call. This is probably unnecessary, but it errs on the side of using more temporary registers so LLIL pattern matching would not need to handle recursive cases. Nothing in the core cares about this case, but if you later write scripts searching LLIL, you won’t have to bother making them handle deeply nested trees.
Arithmetic
Quark’s arithmetic instructions are largely basic, fixed size, and single operation, with only two double-precision operations. Of these arithmetic operations, only two instructions use/set flags, which we will handle next. For now, the rest of them fit neatly into LLIL instructions. For double precision operations, be sure to use set_reg_split to write the result value and reg_split to read the operands.
case QuarkOpcode.add:
il.append(il.set_reg(4, ra(), il.add(4, rb_expr(), cval())))
case QuarkOpcode.sub:
il.append(il.set_reg(4, ra(), il.sub(4, rb_expr(), cval())))
case QuarkOpcode.mulx: # double precision
il.append(il.set_reg_split(4, rd(), ra(), il.mult_double_prec_unsigned(4, rb_expr(), rc_expr())))
case QuarkOpcode.imulx: # double precision
il.append(il.set_reg_split(4, rd(), ra(), il.mult_double_prec_signed(4, rb_expr(), rc_expr())))
case QuarkOpcode.div:
il.append(il.set_reg(4, ra(), il.div_unsigned(4, rb_expr(), cval())))
case QuarkOpcode.idiv:
il.append(il.set_reg(4, ra(), il.div_signed(4, rb_expr(), cval())))
case QuarkOpcode.mod:
il.append(il.set_reg(4, ra(), il.mod_unsigned(4, rb_expr(), cval())))
case QuarkOpcode.imod:
il.append(il.set_reg(4, ra(), il.mod_signed(4, rb_expr(), cval())))
Additionally, like many architectures, Quark has instructions for “add with carry” and “subtract with borrow” to enable larger size arithmetic. The only catch is that they require the use of flags for the carry-in/carry-out value, which the next operation in the sequence will have to read. In the lifter, this part is simple:
case QuarkOpcode.addx:
il.append(il.set_reg(4, ra(), il.add_carry(4, rb_expr(), cval(), il.flag('cc3'), flags='addx')))
case QuarkOpcode.subx:
il.append(il.set_reg(4, ra(), il.sub_borrow(4, rb_expr(), cval(), il.flag('cc3'), flags='addx')))
The only new part here is the use of a Flag Write Type, which we will now specify in the Architecture. We chose to call the Flag Write Type addx because it is specific to the addx family of instructions. Then, we indicate that it sets the cc3 flag with the flags_written_by_flag_write_type property:
class QuarkArch(Architecture):
# ...
flags = [
'cc0', 'cc1', 'cc2', 'cc3',
]
flag_write_types = {
'addx',
}
flags_written_by_flag_write_type = {
'addx': ['cc3'],
# ...
}
After doing this, we can see the lifting for these instructions:
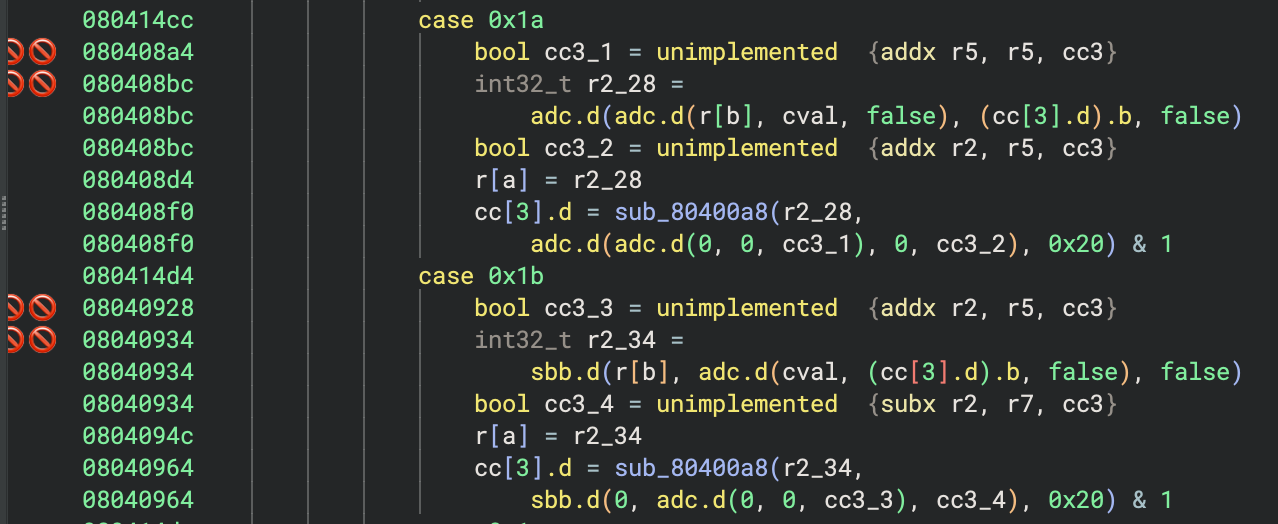
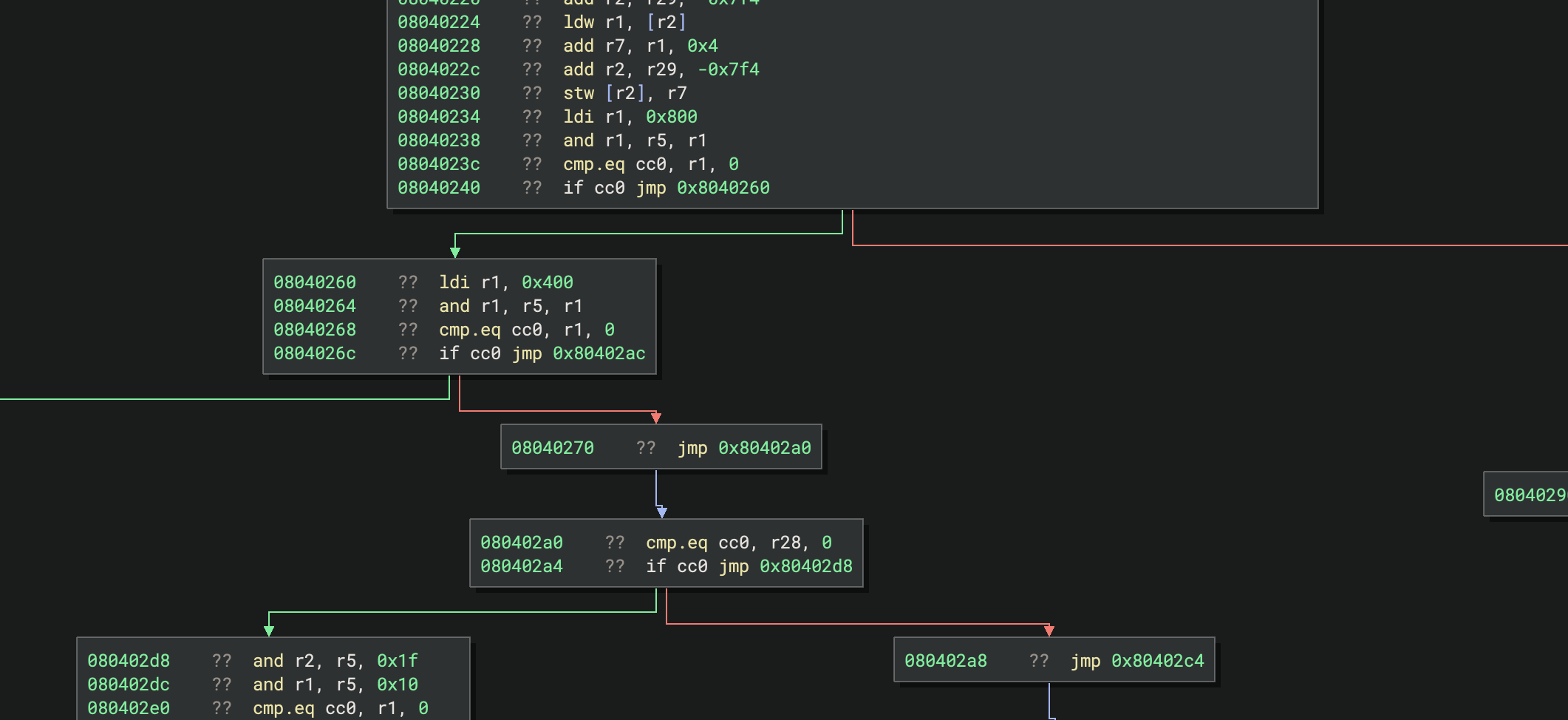
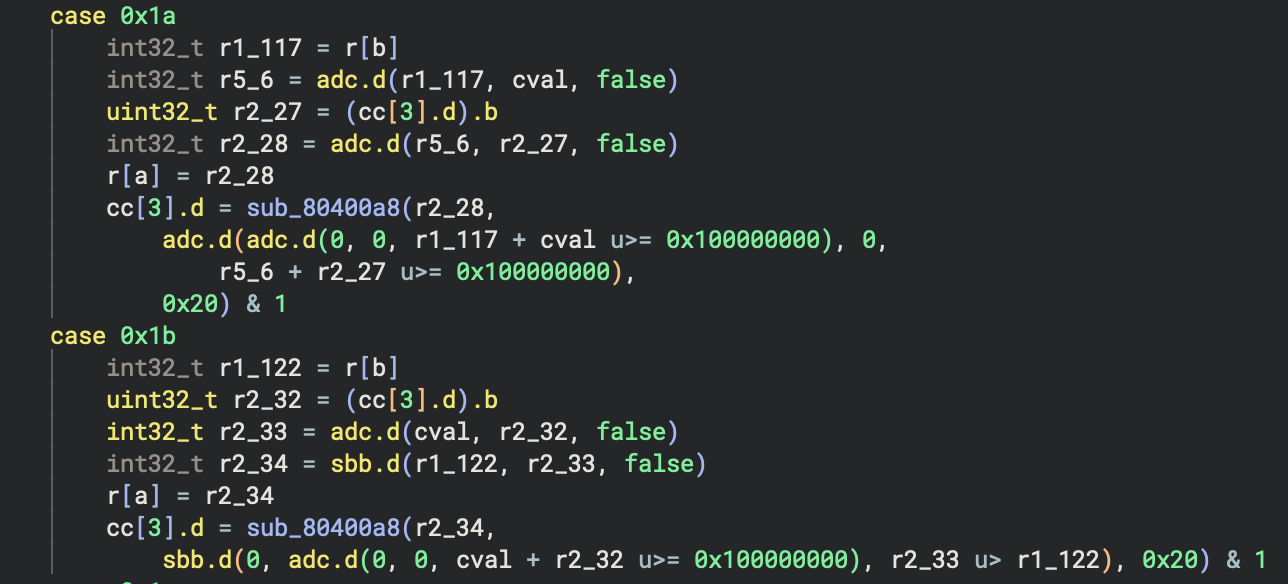
The adc.d(...) instructions are produced, but now they are creating a bunch of unimplemented instructions! Looking at the tags created, we can see the reason:
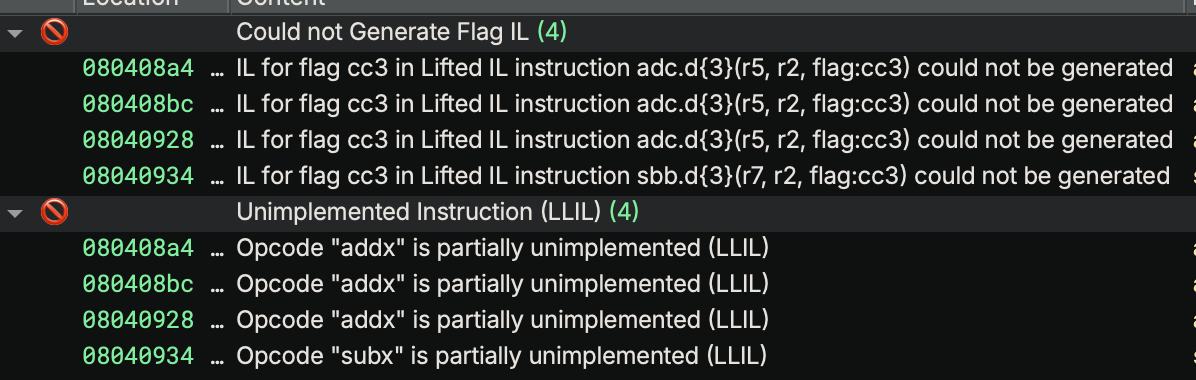
Reading the value of flag cc3 is causing Binary Ninja to attempt to look up its value, but there is nothing to explain how adc or sbb set the flag in their output. To do that, we need to implement the get_flag_write_low_level_il function and tell Binary Ninja what the value of the flag will be when it gets used. This function gets called for uses of flags with unknown definitions, and it produces an IL expression representing the value of the flag. But what is the value of the carry-out flag for adc or sbb? Let’s look at the semantics of those instructions:
adc- Add with Carry: Adds two 32-bit integers and the 1-bit carry flag. Returns a 32-bit integer and a 1-bit carry if the addition overflowed the 32-bit integer maximum. So the expression that represents the value of the carry flag would be,a + b + carry >= UINT32_MAXsbb- Subtract with Borrow: Subtracts two 32-bit integers and 1-bit carry flag (added to the value being subtracted), returns a 32-bit integer and a 1-bit carry if the value being subtracted (plus the carry) was greater than the value from which it was being subtracted. So the expression that represents the value of the carry flag would be,(b + carry) > a
Now that we know what the expression of the resulting carry flag is, we can implement get_flag_write_low_level_il and tell Binary Ninja what IL to generate for the carry flag. To start, here is the function prototype:
def get_flag_write_low_level_il(
self, op: LowLevelILOperation, size: int, write_type: Optional[FlagWriteTypeName], flag: FlagType,
operands: List['ILRegisterType'], il: 'LowLevelILFunction'
) -> 'ExpressionIndex':
...
First, let’s define a few helper functions to convert the operands into IL expressions:
def get_expr_for_register_or_constant(size, operand):
if isinstance(operand, ILRegister):
return il.reg(size, operand)
elif isinstance(operand, ILFlag): # Fixed in >= 5.3
return il.flag(operand.index)
elif isinstance(operand, int):
return il.const(size, operand)
else:
assert False, "Not handled"
def get_expr_for_flag_or_constant(operand):
# For ADC/SBB/RLC/RRC, the carry flag is passed as a temporary "register".
# This is super specific and only affects those four instructions and one operand,
# and will be fixed in future versions, but we need to handle it for now:
if isinstance(operand, ILRegister):
return il.flag(operand.index)
elif isinstance(operand, ILFlag): # Fixed in >= 5.3
return il.flag(operand.index)
elif isinstance(operand, int):
return il.const(size, operand)
else:
assert False, "Not handled"
And then we can implement the Flag Write Type. Our function gets called with the Flag Write Type’s name and the producing operation, which we test for and return the appropriate IL expression:
match write_type:
case 'addx':
if op == LowLevelILOperation.LLIL_ADC:
# ((first + second + carry) >> 32) & 1
# Which is the same as (first + second + carry) >= 0x1_0000_0000
return il.compare_unsigned_greater_equal(
8,
il.add(
8, # extend the width of these operands so we can test the overflow
il.zero_extend(8, get_expr_for_register_or_constant(size, operands[0])),
il.add(
8,
il.zero_extend(8, get_expr_for_register_or_constant(size, operands[1])),
il.zero_extend(8, get_expr_for_flag_or_constant(operands[2])) # !! flag
)
),
il.const(8, 0x1_0000_0000)
)
if op == LowLevelILOperation.LLIL_SBB:
# ((first - (second + carry)) >> 32) & 1
# Which is zero unless (second + carry) > first
return il.compare_unsigned_greater_than(
size,
il.add(
size,
get_expr_for_register_or_constant(size, operands[1]),
get_expr_for_flag_or_constant(operands[2]) # !! flag
),
get_expr_for_register_or_constant(size, operands[0])
)
return il.unimplemented()
And now our large-width arithmetic is lifted properly, although carry-addition is rather difficult to read given Binary Ninja’s lack of optimizations for it:
System Calls
Lifting system calls is easy. Similar to a call instruction, the LLIL operation for a system call is simply, il.system_call(). But how do we specify the system call number? Since many architectures use a register to determine system call number, Binary Ninja makes us pass it in a register.
The Quark architecture embeds the system call number in the syscall instruction itself, so to put that into a register for Binary Ninja, we add an extra synthetic register to the Architecture’s regs list.
# Previously
class QuarkArch(Architecture):
regs = {
# ...
'syscall_num': RegisterInfo('syscall_num', 4),
}
Then, we can lift the syscall instruction by setting that register and performing a system call:
case QuarkOpcode.syscall:
il.append(il.set_reg(4, 'syscall_num', il.const(4, info.imm22)))
il.append(il.system_call())
Seeing this, you may be curious how Binary Ninja can resolve system call names and parameter types. That is explained in Part 3’s section on calling conventions.
Intrinsics
Certain operations don’t map cleanly to existing LLIL operations. In those cases, it is often better to lift them as intrinsics: architecture-specific operations that analysis will not try to process. Choosing when to model complex operations as intrinsics is often a matter of taste and effort. We generally recommend these principles:
- Operations that can affect constant propagation are better as non-intrinsic (so constant propagation can run)
- Operations that would need many smaller operations are often better as intrinsics (to reduce clutter)
- SIMD operations are largely not supported by dataflow, so they are better as intrinsics
- Operations that rely on external data or actions (e.g. randomness) need to be intrinsics
In the case of Quark, we’ve chosen to implement endian byte-swapping as an intrinsic. It is largely irrelevant to constant propagation dataflow, so likely all uses of it will simply clutter our decompilation with precise semantics about an operation that is otherwise easy to understand. To do this, we first need to define the intrinsics in our Architecture subclass:
class QuarkArch(Architecture):
# ...
intrinsics = {
'__byteswaph': IntrinsicInfo(
# inputs
[IntrinsicInput(Type.int(2, False), 'input')],
# outputs
[Type.int(4, False)]
),
'__byteswapw': IntrinsicInfo(
[IntrinsicInput(Type.int(4, False), 'input')],
[Type.int(4, False)]
),
}
Each intrinsic needs to specify its list of inputs and outputs. When defining them for the architecture, these are represented with Types, which are likely integers. In this case, __byteswaph operates on a 2-byte input but clobbers the entire output register, so its output is a 4-byte integer. __byteswapw operates on a 4-byte unsigned integer and returns another 4-byte unsigned integer.
After specifying the intrinsics, lifting them just requires you to specify the list of input expressions and output registers. The one oddity here is that intrinsics are full instructions–they should not be used as a sub-expression of a (for example) set_reg instruction. Their outputs need to go into registers, so you may need to create temporary registers if your intrinsics have more complicated semantics. For Quark, this was pretty simple:
case QuarkIntegerOpcode.swaph:
il.append(il.intrinsic([ra()], '__byteswaph', [il.low_part(2, rc_expr())]))
case QuarkIntegerOpcode.swapw:
il.append(il.intrinsic([ra()], '__byteswapw', [rc_expr()]))
Flags
Quark, like many other architectures, uses flags to control conditional branches. There are dedicated instructions to set the flags, and different instructions that read them and affect control flow. Because of this, we need to use dataflow for resolving the conditional instructions that use flags.
When it comes to flags and conditional instructions, there are three overall strategies:
- Explicit Flag Usage
- Flag Conditions (not covered here, see Addendum)
- Semantic Flag Groups
While you could have every operation that modifies flags emit IL instructions to set every flag, this is quite tedious since many architectures have arithmetic operations that affect a large number of flags. Trying to lift all of these instructions with explicit flag calculation produces a lot of clutter in the IL, all for flags that are rarely used. Binary Ninja’s flag system was designed to minimize this clutter, and we call it Semantic Flags. Using this system, IL is only generated for flags that are used, eliminating a large number of unnecessary flag writes.
Depending on the circumstances, you will want to lift different instructions using the different techniques. We’re going to cover explicit flags and semantic flags here.
Explicit Flags
Instructions whose explicit purpose is setting flags can be lifted as direct flag writes. The lifting for this is the most obvious approach to flags: get and set their value based on an expression. Here are a few from Quark:
case QuarkOpcode.integer_group:
int_op = QuarkIntegerOpcode(info.b)
match int_op:
case QuarkIntegerOpcode.setcc:
il.append(il.set_flag(il.arch.get_flag_index(f"cc{info.a & 3}"), il.const(0, 1)))
case QuarkIntegerOpcode.clrcc:
il.append(il.set_flag(il.arch.get_flag_index(f"cc{info.a & 3}"), il.const(0, 0)))
case QuarkIntegerOpcode.notcc:
il.append(il.set_flag(il.arch.get_flag_index(f"cc{info.a & 3}"), il.not_expr(0, il.flag(f"cc{info.c & 3}"))))
case QuarkIntegerOpcode.movcc:
il.append(il.set_flag(il.arch.get_flag_index(f"cc{info.a & 3}"), il.flag(f"cc{info.c & 3}")))
case QuarkIntegerOpcode.andcc:
il.append(il.set_flag(il.arch.get_flag_index(f"cc{info.a & 3}"), il.and_expr(0, il.flag(f"cc{info.c & 3}"), il.flag(f"cc{info.d & 3}"))))
case QuarkIntegerOpcode.orcc:
il.append(il.set_flag(il.arch.get_flag_index(f"cc{info.a & 3}"), il.or_expr(0, il.flag(f"cc{info.c & 3}"), il.flag(f"cc{info.d & 3}"))))
case QuarkIntegerOpcode.xorcc:
il.append(il.set_flag(il.arch.get_flag_index(f"cc{info.a & 3}"), il.xor_expr(0, il.flag(f"cc{info.c & 3}"), il.flag(f"cc{info.d & 3}"))))
Since these instructions act specifically on flags, lifting them as explicit flag sets and uses makes sense.
Semantic Flag Groups
The Semantic Flags system in Binary Ninja allows you to specify many advanced behaviors for flags. It does this via a deferred flag resolution system, where flag-setting expressions are only generated when the flags are used. Instead of emitting IL for every flag every time an instruction could modify it, the modifying instructions are tagged with a Flag Write Type that indicates which flags are written. When a flag is used, it gets lifted as testing a Semantic Flag Group, which Binary Ninja can then resolve to the expression setting the flag and then inline that expression. For most common operations, these comparisons can be represented by built-in operations automatically, but there is enough flexibility in the system to support more complex behaviors.
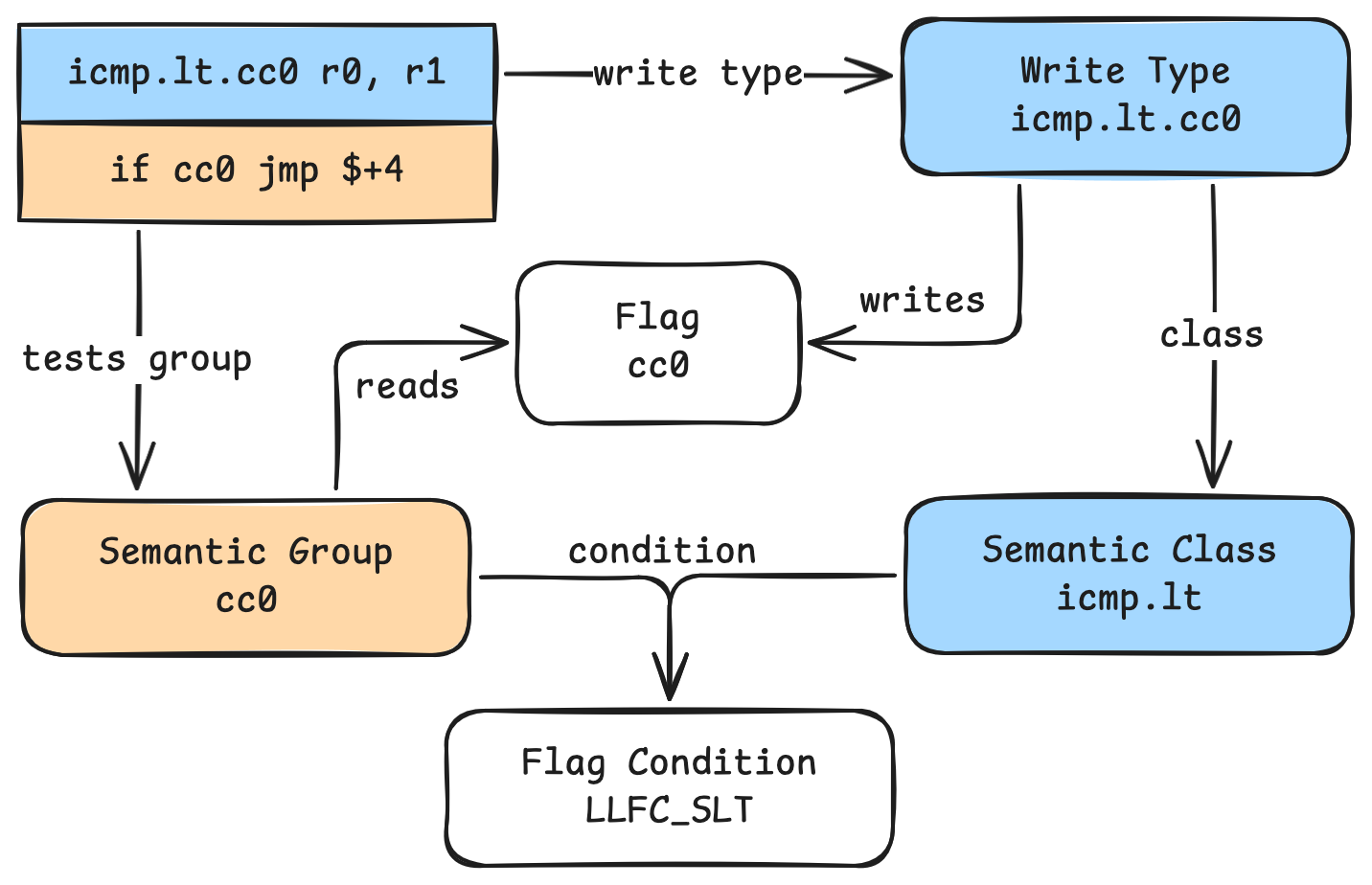
Let’s see what we need to specify in our architecture. First, our flags:
class QuarkArch(Architecture):
# ...
flags = [
'cc0', 'cc1', 'cc2', 'cc3',
]
Certain architectures have flags that follow one of a few predefined behaviors, known as Flag Roles. These include a carry flag, zero flag, overflow flag, etc. If your architecture has those types of flags, you can specify them, and Binary Ninja will automatically resolve many types of comparison expressions. Quark, however, doesn’t have dedicated flags for these behaviors, so we mark every flag as SpecialFlagRole.
flag_roles = {
'cc0': FlagRole.SpecialFlagRole,
'cc1': FlagRole.SpecialFlagRole,
'cc2': FlagRole.SpecialFlagRole,
'cc3': FlagRole.SpecialFlagRole,
}
The instructions that set flags need to specify a Flag Write Type, which informs Binary Ninja both which flags the instruction sets and what type of operation to use for setting the flag. Generally speaking, every different type of operation and flag should get its own Flag Write Type. So for architectures where all arithmetic instructions modify a specific carry/zero/overflow flag in the same way, you would have one Flag Write Type for that behavior. In Quark, as in some architectures like PowerPC, there is not one dedicated flag for carry/zero/overflow/etc, and so we need to create Flag Write Types for every combination of flag and comparison operation. Quark has four flags, eight signed comparison operations, and eight unsigned comparison operations. This leads to a total of 64 Flag Write Types, plus the addx type mentioned previously:
flag_write_types = {
# Each of the 8 unsigned comparisons that could affect cc0
'cmp.lt.cc0', 'cmp.le.cc0', 'cmp.ge.cc0', 'cmp.gt.cc0', 'cmp.eq.cc0', 'cmp.ne.cc0', 'cmp.z.cc0', 'cmp.nz.cc0',
# Same thing for the signed comparisons
'icmp.lt.cc0', 'icmp.le.cc0', 'icmp.ge.cc0', 'icmp.gt.cc0', 'icmp.eq.cc0', 'icmp.ne.cc0', 'icmp.z.cc0', 'icmp.nz.cc0',
# Same thing for the other flags
'cmp.lt.cc1', 'cmp.le.cc1', 'cmp.ge.cc1', 'cmp.gt.cc1', 'cmp.eq.cc1', 'cmp.ne.cc1', 'cmp.z.cc1', 'cmp.nz.cc1',
'icmp.lt.cc1', 'icmp.le.cc1', 'icmp.ge.cc1', 'icmp.gt.cc1', 'icmp.eq.cc1', 'icmp.ne.cc1', 'icmp.z.cc1', 'icmp.nz.cc1',
'cmp.lt.cc2', 'cmp.le.cc2', 'cmp.ge.cc2', 'cmp.gt.cc2', 'cmp.eq.cc2', 'cmp.ne.cc2', 'cmp.z.cc2', 'cmp.nz.cc2',
'icmp.lt.cc2', 'icmp.le.cc2', 'icmp.ge.cc2', 'icmp.gt.cc2', 'icmp.eq.cc2', 'icmp.ne.cc2', 'icmp.z.cc2', 'icmp.nz.cc2',
'cmp.lt.cc3', 'cmp.le.cc3', 'cmp.ge.cc3', 'cmp.gt.cc3', 'cmp.eq.cc3', 'cmp.ne.cc3', 'cmp.z.cc3', 'cmp.nz.cc3',
'icmp.lt.cc3', 'icmp.le.cc3', 'icmp.ge.cc3', 'icmp.gt.cc3', 'icmp.eq.cc3', 'icmp.ne.cc3', 'icmp.z.cc3', 'icmp.nz.cc3',
# And addx, which has its own special behavior
'addx'
}
Each of the Flag Write Types should specify which flags it writes. This field is how Binary Ninja knows when the flag gets written, as the comparison operations don’t set the flags directly. Since Quark’s Flag Write Types are split out per flag and per operation, each will only write one flag. If you had a combined carry/zero/overflow Flag Write Type, it would modify multiple flags at once.
flags_written_by_flag_write_type = {
# Each of these comparisons only affects one flag at a time
'cmp.lt.cc0': ['cc0'], 'cmp.le.cc0': ['cc0'], 'cmp.ge.cc0': ['cc0'], 'cmp.gt.cc0': ['cc0'], 'cmp.eq.cc0': ['cc0'], 'cmp.ne.cc0': ['cc0'], 'cmp.z.cc0': ['cc0'], 'cmp.nz.cc0': ['cc0'],
'icmp.lt.cc0': ['cc0'], 'icmp.le.cc0': ['cc0'], 'icmp.ge.cc0': ['cc0'], 'icmp.gt.cc0': ['cc0'], 'icmp.eq.cc0': ['cc0'], 'icmp.ne.cc0': ['cc0'], 'icmp.z.cc0': ['cc0'], 'icmp.nz.cc0': ['cc0'],
'cmp.lt.cc1': ['cc1'], 'cmp.le.cc1': ['cc1'], 'cmp.ge.cc1': ['cc1'], 'cmp.gt.cc1': ['cc1'], 'cmp.eq.cc1': ['cc1'], 'cmp.ne.cc1': ['cc1'], 'cmp.z.cc1': ['cc1'], 'cmp.nz.cc1': ['cc1'],
'icmp.lt.cc1': ['cc1'], 'icmp.le.cc1': ['cc1'], 'icmp.ge.cc1': ['cc1'], 'icmp.gt.cc1': ['cc1'], 'icmp.eq.cc1': ['cc1'], 'icmp.ne.cc1': ['cc1'], 'icmp.z.cc1': ['cc1'], 'icmp.nz.cc1': ['cc1'],
'cmp.lt.cc2': ['cc2'], 'cmp.le.cc2': ['cc2'], 'cmp.ge.cc2': ['cc2'], 'cmp.gt.cc2': ['cc2'], 'cmp.eq.cc2': ['cc2'], 'cmp.ne.cc2': ['cc2'], 'cmp.z.cc2': ['cc2'], 'cmp.nz.cc2': ['cc2'],
'icmp.lt.cc2': ['cc2'], 'icmp.le.cc2': ['cc2'], 'icmp.ge.cc2': ['cc2'], 'icmp.gt.cc2': ['cc2'], 'icmp.eq.cc2': ['cc2'], 'icmp.ne.cc2': ['cc2'], 'icmp.z.cc2': ['cc2'], 'icmp.nz.cc2': ['cc2'],
'cmp.lt.cc3': ['cc3'], 'cmp.le.cc3': ['cc3'], 'cmp.ge.cc3': ['cc3'], 'cmp.gt.cc3': ['cc3'], 'cmp.eq.cc3': ['cc3'], 'cmp.ne.cc3': ['cc3'], 'cmp.z.cc3': ['cc3'], 'cmp.nz.cc3': ['cc3'],
'icmp.lt.cc3': ['cc3'], 'icmp.le.cc3': ['cc3'], 'icmp.ge.cc3': ['cc3'], 'icmp.gt.cc3': ['cc3'], 'icmp.eq.cc3': ['cc3'], 'icmp.ne.cc3': ['cc3'], 'icmp.z.cc3': ['cc3'], 'icmp.nz.cc3': ['cc3'],
# addx always modifies the cc3 flag
'addx': ['cc3']
}
From here, you could extend the implementation of get_flag_write_low_level_il we started above, and handle emitting IL for every one of these flag write types. That does work, but leads to you writing a lot of extra code to handle behaviors that Binary Ninja could automatically resolve for you.
To use Binary Ninja’s built-in conditional support, we need to specify a few more constructs. First, we need to list the Semantic Flag Classes for each operation. These classes represent the different types of conditions tested, and each will map to a different IL expression generated. We define one class per unique comparison operation: signed/unsigned less than, less or equal, greater or equal, and greater than; sign-agnostic equality, non-equality, zero, and non-zero. Every Flag Write Type maps to one of these classes, but the classes themselves don’t require specific flags.
semantic_flag_classes = [
'cmp.lt', 'cmp.le', 'cmp.ge', 'cmp.gt',
'icmp.lt', 'icmp.le', 'icmp.ge', 'icmp.gt',
'eq', 'ne', 'z', 'nz',
]
semantic_class_for_flag_write_type = {
'cmp.lt.cc0': 'cmp.lt', 'cmp.le.cc0': 'cmp.le', 'cmp.ge.cc0': 'cmp.ge', 'cmp.gt.cc0': 'cmp.gt', 'cmp.eq.cc0': 'eq', 'cmp.ne.cc0': 'ne', 'cmp.z.cc0': 'z', 'cmp.nz.cc0': 'nz',
'icmp.lt.cc0': 'icmp.lt', 'icmp.le.cc0': 'icmp.le', 'icmp.ge.cc0': 'icmp.ge', 'icmp.gt.cc0': 'icmp.gt', 'icmp.eq.cc0': 'eq', 'icmp.ne.cc0': 'ne', 'icmp.z.cc0': 'z', 'icmp.nz.cc0': 'nz',
'cmp.lt.cc1': 'cmp.lt', 'cmp.le.cc1': 'cmp.le', 'cmp.ge.cc1': 'cmp.ge', 'cmp.gt.cc1': 'cmp.gt', 'cmp.eq.cc1': 'eq', 'cmp.ne.cc1': 'ne', 'cmp.z.cc1': 'z', 'cmp.nz.cc1': 'nz',
'icmp.lt.cc1': 'icmp.lt', 'icmp.le.cc1': 'icmp.le', 'icmp.ge.cc1': 'icmp.ge', 'icmp.gt.cc1': 'icmp.gt', 'icmp.eq.cc1': 'eq', 'icmp.ne.cc1': 'ne', 'icmp.z.cc1': 'z', 'icmp.nz.cc1': 'nz',
'cmp.lt.cc2': 'cmp.lt', 'cmp.le.cc2': 'cmp.le', 'cmp.ge.cc2': 'cmp.ge', 'cmp.gt.cc2': 'cmp.gt', 'cmp.eq.cc2': 'eq', 'cmp.ne.cc2': 'ne', 'cmp.z.cc2': 'z', 'cmp.nz.cc2': 'nz',
'icmp.lt.cc2': 'icmp.lt', 'icmp.le.cc2': 'icmp.le', 'icmp.ge.cc2': 'icmp.ge', 'icmp.gt.cc2': 'icmp.gt', 'icmp.eq.cc2': 'eq', 'icmp.ne.cc2': 'ne', 'icmp.z.cc2': 'z', 'icmp.nz.cc2': 'nz',
'cmp.lt.cc3': 'cmp.lt', 'cmp.le.cc3': 'cmp.le', 'cmp.ge.cc3': 'cmp.ge', 'cmp.gt.cc3': 'cmp.gt', 'cmp.eq.cc3': 'eq', 'cmp.ne.cc3': 'ne', 'cmp.z.cc3': 'z', 'cmp.nz.cc3': 'nz',
'icmp.lt.cc3': 'icmp.lt', 'icmp.le.cc3': 'icmp.le', 'icmp.ge.cc3': 'icmp.ge', 'icmp.gt.cc3': 'icmp.gt', 'icmp.eq.cc3': 'eq', 'icmp.ne.cc3': 'ne', 'icmp.z.cc3': 'z', 'icmp.nz.cc3': 'nz',
}
Then, we define Semantic Flag Groups. These are groups of flags that conditional instructions can test together. On certain architectures, conditionals might read multiple flags to determine whether a branch is taken, such branching if both the carry and overflow flag are set. On Quark, however, each branch can only read one flag at a time. This means our Semantic Flag Groups will be one-to-one with the flags. We specify each group and which flags that group tests:
semantic_flag_groups = [
'cc0',
'cc1',
'cc2',
'cc3',
]
flags_required_for_semantic_flag_group = {
'cc0': ['cc0'],
'cc1': ['cc1'],
'cc2': ['cc2'],
'cc3': ['cc3'],
}
Automatically Implementing Conditions
Next, we specify which conditions are used for each combination of Semantic Flag Classes and Semantic Flag Groups. When Binary Ninja sees a use of a Semantic Flag Group, it will look up the corresponding Flag Write Type for each flag in the group, and the corresponding Semantic Flag Class for each Flag Write Type. If all of those Semantic Flag Classes are the same, Binary Ninja will look up the Semantic Flag Condition from the architecture and emit the corresponding IL expression for that condition. For Quark, we define a map from each Semantic Flag Group (one-to-one with each flag) and each Semantic Flag Class (one for every type of comparison) to the corresponding condition:
flag_conditions_for_semantic_flag_group = {
'cc0': {
'cmp.lt': LowLevelILFlagCondition.LLFC_ULT,
'cmp.le': LowLevelILFlagCondition.LLFC_ULE,
'cmp.ge': LowLevelILFlagCondition.LLFC_UGE,
'cmp.gt': LowLevelILFlagCondition.LLFC_UGT,
'icmp.lt': LowLevelILFlagCondition.LLFC_SLT,
'icmp.le': LowLevelILFlagCondition.LLFC_SLE,
'icmp.ge': LowLevelILFlagCondition.LLFC_SGE,
'icmp.gt': LowLevelILFlagCondition.LLFC_SGT,
'eq': LowLevelILFlagCondition.LLFC_E,
'ne': LowLevelILFlagCondition.LLFC_NE,
},
'cc1': {
# ... same as cc0
},
'cc2': {
# ... same as cc0
},
'cc3': {
# ... same as cc0
},
}
This is effectively telling Binary Ninja:
- When you see a
cc0Semantic Flag Group test - Look at the relevant flag(s)
cc0is the only flag that group reads, as defined inflags_required_for_semantic_flag_group
- Figure out which instruction set them
- If that instruction has a Semantic Flag Class of
icmp.lticmp.ltis the Semantic Flag Class corresponding to theicmp.lt.cc0Flag Write Type insemantic_class_for_flag_write_typeicmp.lt.cc0is the Flag Write Type used by aicmp.lt.cc0instruction during lifting
- Use the Flag Condition
LLFC_SLTto emit an IL expression for that Flag Group test- Specified by the
flag_conditions_for_semantic_flag_groupmap LLFC_SLTemits aLLIL_CMP_SLTexpression
- Specified by the
This will cause Binary Ninja, when resolving flags from Lifted IL to Low Level IL, to replace the instructions sub.d{icmp.lt.cc0}(expr1, expr2) ; if (cc0) with the instructions if (expr1 s< expr2), inlining the comparison at the test site.
Manually Implementing Conditions
You may notice we did not specify a condition for the z and nz Semantic Flag Classes. That is because these do not map cleanly to one of the built-in Flag Conditions and need to be lifted manually by us. Since there is no condition in the flag_conditions_for_semantic_flag_group mapping, Binary Ninja will call get_flag_write_low_level_il for each flag written by the Flag Write Type, to emit an expression that it will write to the flag. It will then call get_semantic_flag_group_low_level_il to get an expression that reads the relevant flags, to replace the test. We need to implement those ourselves.
Here are the updates to get_flag_write_low_level_il to emit expressions for the z and nz comparisons. Note that the returned expression is not appended to the IL function to create an IL instruction–the core will insert it into whichever instruction is necessary.
def get_flag_write_low_level_il(
self, op: LowLevelILOperation, size: int, write_type: Optional[FlagWriteTypeName], flag: FlagType,
operands: List['ILRegisterType'], il: 'LowLevelILFunction'
) -> 'ExpressionIndex':
# ...
match write_type:
case 'addx':
... # We implemented addx above for add-with-carry
# `nz` condition: Compare if the AND of two values is non-zero
case 'cmp.nz.cc0' | 'icmp.nz.cc0' | 'cmp.nz.cc1' | 'icmp.nz.cc1' | 'cmp.nz.cc2' | 'icmp.nz.cc2' | 'cmp.nz.cc3' | 'icmp.nz.cc3':
return il.compare_not_equal(
4,
il.and_expr(
4,
get_expr_for_register_or_constant(4, operands[0]),
get_expr_for_register_or_constant(4, operands[1])
),
il.const(4, 0)
)
# `z` condition: Compare if the AND of two values is zero
case 'cmp.z.cc0' | 'icmp.z.cc0' | 'cmp.z.cc1' | 'icmp.z.cc1' | 'cmp.z.cc2' | 'icmp.z.cc2' | 'cmp.z.cc3' | 'icmp.z.cc3':
return il.compare_equal(
4,
il.and_expr(
4,
get_expr_for_register_or_constant(4, operands[0]),
get_expr_for_register_or_constant(4, operands[1])
),
il.const(4, 0)
)
return il.unimplemented()
Here’s how we implement get_semantic_flag_group_low_level_il to read the flags tested by our Semantic Flag Groups:
def get_semantic_flag_group_low_level_il(
self, sem_group: Optional[SemanticGroupType], il: 'lowlevelil.LowLevelILFunction'
) -> 'lowlevelil.ExpressionIndex':
match sem_group: # Each Semantic Flag Group only tests one flag since conditional branches can only read one flag
case 'cc0':
return il.flag('cc0')
case 'cc1':
return il.flag('cc1')
case 'cc2':
return il.flag('cc2')
case 'cc3':
return il.flag('cc3')
case _:
return il.unimplemented()
This will cause Binary Ninja, when resolving flags from Lifted IL to Low Level IL, to replace the instructions and.d{cmp.z.cc0}(expr1, expr2) ; if (cc0) with the instructions flag:cc0 = (expr1 & expr2) == 0 ; if (flag:cc0). Having to use these callbacks causes Binary Ninja to spill the flag write to a separate instruction.
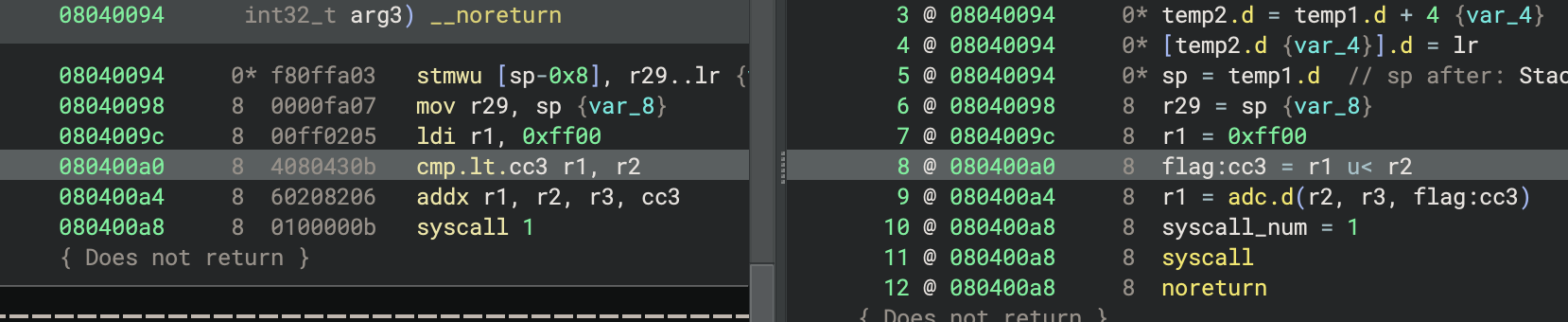
We also need to specify the IL generated for flag writes for the other comparison operations, in case their results are ever used by instructions that read flags directly (not through a Semantic Flag Group). You can see an example here, in a function that we modified to specifically use this behavior:

The solution to this is to modify get_flag_write_low_level_il to return valid IL expressions for the Flag Write Types representing the other operations. As before, the returned expression is not appended to the function as an instruction. Here’s how we implemented them:
def get_flag_write_low_level_il(
self, op: LowLevelILOperation, size: int, write_type: Optional[FlagWriteTypeName], flag: FlagType,
operands: List['ILRegisterType'], il: 'LowLevelILFunction'
) -> 'ExpressionIndex':
# ...
match write_type:
# ...
case 'cmp.lt.cc0' | 'cmp.lt.cc1' | 'cmp.lt.cc2' | 'cmp.lt.cc3':
return il.compare_unsigned_less_than(size, get_expr_for_register_or_constant(size, operands[0]), get_expr_for_register_or_constant(size, operands[1]))
case 'icmp.lt.cc0' | 'icmp.lt.cc1' | 'icmp.lt.cc2' | 'icmp.lt.cc3':
return il.compare_signed_less_than(size, get_expr_for_register_or_constant(size, operands[0]), get_expr_for_register_or_constant(size, operands[1]))
# ... etc for the rest of the comparisons
Having implemented all the Flag Write Types, we now see flags fully resolved when used by expressions:
Emitting Comparison Instructions
Now that we’ve specified how flags are used, we can lift the operations that write flags. You will notice that the comparisons are generally lifted as subtraction operations. This is because many major architectures implement comparisons as subtractions. In the case of Quark, subtractions don’t set any flags, but we chose to lift most of the comparisons as subtractions to highlight this commonly seen behavior. Due to the custom behavior of the nz and z comparison operations, we chose to lift these as and instructions. This likely has no effect, as the instruction gets replaced by the flags resolver as explained above, but for certain built-in operations, the choice of underlying instruction might affect which comparison is automatically generated.
def get_instruction_low_level_il(self, data: bytes, addr: int, il: LowLevelILFunction) -> Optional[int]:
# ...
match op:
case QuarkOpcode.cmp:
cmp_op = QuarkCompareOpcode(info.b & 7)
match cmp_op:
case QuarkCompareOpcode.lt:
# Flag Write Type as specified above
il.append(il.sub(4, ra_expr(), cval(), flags=f"cmp.lt.cc{info.b >> 3}"))
case QuarkCompareOpcode.le:
il.append(il.sub(4, ra_expr(), cval(), flags=f"cmp.le.cc{info.b >> 3}"))
# ... rest of these
case QuarkCompareOpcode.nz:
il.append(il.and_expr(4, ra_expr(), cval(), flags=f"cmp.nz.cc{info.b >> 3}"))
case QuarkCompareOpcode.z:
il.append(il.and_expr(4, ra_expr(), cval(), flags=f"cmp.z.cc{info.b >> 3}"))
case _:
il.append(il.unimplemented())
case QuarkOpcode.icmp:
cmp_op = QuarkCompareOpcode(info.b & 7)
match cmp_op:
case QuarkCompareOpcode.lt:
il.append(il.sub(4, ra_expr(), cval(), flags=f"icmp.lt.cc{info.b >> 3}"))
# ... same as above except icmp in the flag write type
Example: aarch64
In an attempt to cover a wider range of use cases for Semantic Flags, here’s how this is modeled in aarch64’s flags system. You can see the source code for how this was implemented this in our open-source architecture plugin. That part of the plugin was written by yrp, whose numerous contributions to the aarch64 architecture plugin have been greatly appreciated.
aarch64 uses the semantic flags system to model a different type of flag behavior. The arithmetic instructions set every flag based on the result of their operation, rather than having dedicated comparison operations (as in Quark). aarch64’s conditional instructions read various flags to determine if their condition is true, instead of just reading one flag at a time (also as in Quark). This leads to a significantly different model of flags, but it can still be represented in Semantic Flags. Here’s how it works:
- Four flags:
cthe carry flag, with role CarryFlagWithInvertedSubtractnthe negative sign flag, with role NegativeSignFlagvthe overflow flag, with role OverflowFlagzthe zero flag, with role ZeroFlag
- Two Flag Write Types:
*modifies all flags, used by integer operationsf*modifies all flags, used by floating point operations- Since all arithmetic instructions modify all flags, aarch64 only needs to differentiate between integer and floating point operations, e.g., a
cmp w13, w19is an integer operation that sets all four flags, so it has the*Flag Write Type. - The implementation of
get_flag_write_low_level_illargely punts toGetDefaultFlagWriteLowLevelILfor emitting expressions to set the flags. aarch64 is able to useGetDefaultFlagWriteLowLevelILbecause its flags can be assigned to built-in Flag Roles, whereas Quark had to implement this function manually. The one exception for aarch64 is that thecflag has custom behavior for theSBBinstruction, similar to how Quark has custom behavior for thecc3flag foraddx/subx.
- Two Semantic Flag Classes for the Flag Write Types:
intclass for the*Flag Write Typefloatclass for thef*Flag Write Type
- Semantic Flag Groups for each type of comparison:
eq,ne,cs,cc,mi,pl,vs,vc,hi,ls,ge,lt,gt,le- Every conditional instruction uses the specific Semantic Flag Group for that type of comparison, e.g., a
b.ltinstruction uses theltSemantic Flag Group. - Each of these groups has a set of required flags based on what flags the operation uses in determining the condition, e.g., the
ltSemantic Flag Group needs to read thenandvflags. - Instead of the
get_semantic_flag_group_low_level_ilfunction returning one single flag read, it calls the functionGetFlagConditionLowLevelIL, which uses the flag roles to emit the appropriate IL expression for the conditional. The actual implementation ofGetFlagConditionLowLevelILis currently private in the core’s source, but is available upon request if you are implementing an architecture and would like to debug your use of flags. We may publish it in the open-source repository at some point in the future.
- Conditions defined for the Semantic Flag Classes and Semantic Flag Groups:
eqandinthas conditionLLFC_Eeqandfloathas conditionLLFC_FEltandinthas conditionLLFC_SLT- … and so on
- All combinations of Semantic Flag Classes and Semantic Flag Groups are covered here, so there are no custom implementations like Quark’s
zcomparison.
And here is the previous Semantic Flags diagram for a signed less-than conditional branch on aarch64:
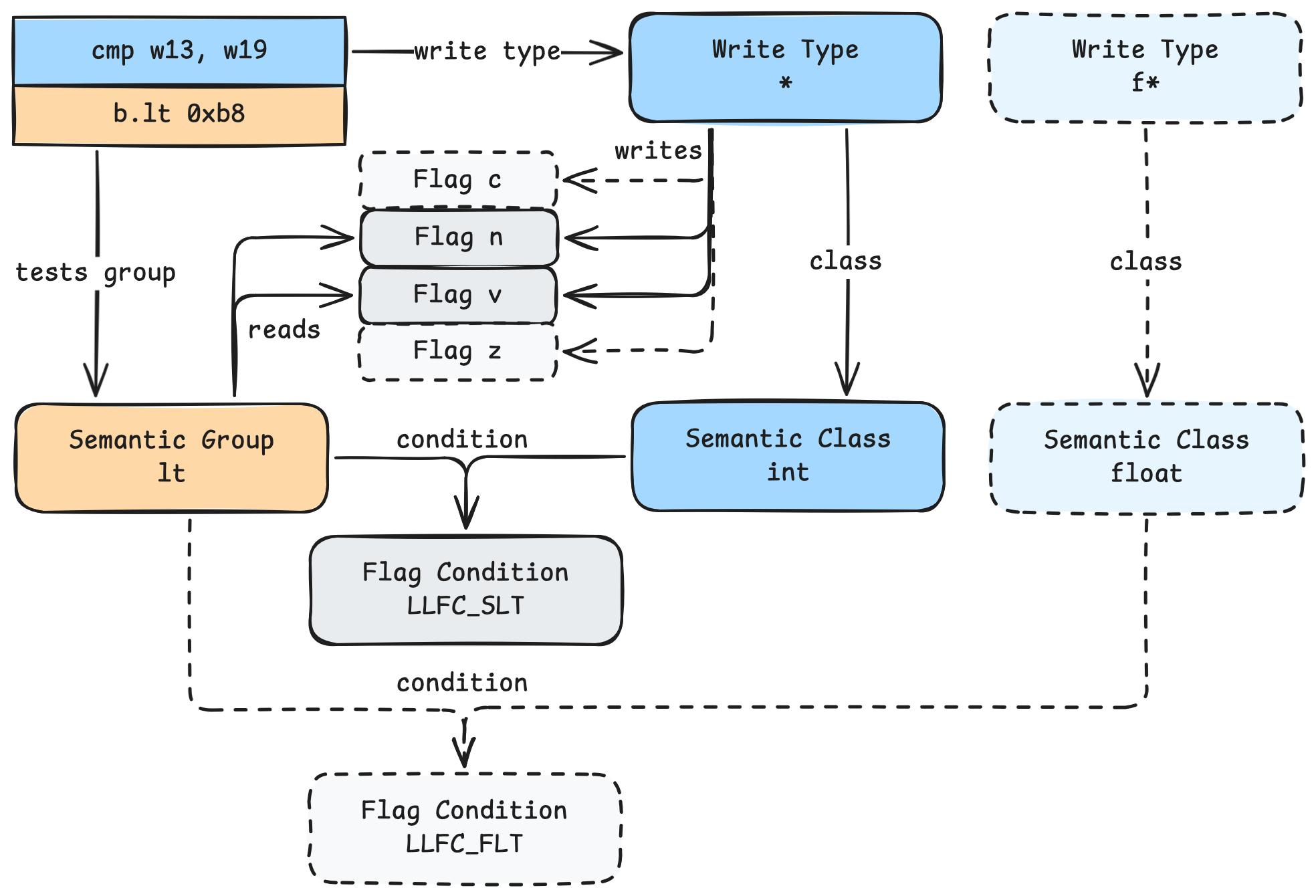
- The
cmp w13, w19instruction writes flags:- It has a Flag Write Type of
* - The aarch64 plugin defines the
*Flag Write Type as writing all four flags,c,n,v, andz. - The aarch64 plugin specifies that the
*Flag Write Type has the Semantic Flag Class ofint(all integer operations have the same Semantic Flag Class)
- It has a Flag Write Type of
- The
b.lt 0xb8instruction reads flags:- It has a Semantic Flag Group of
lt - The aarch64 plugin specifies that the
ltSemantic Flag Group tests flagsnandv
- It has a Semantic Flag Group of
- The aarch64 plugin specifies that, when the
ltSemantic Flag Group is testing flags written by theintSemantic Flag Class, Binary Ninja should use theLLFC_SLTcondition to emit the IL expression for that branch. - Included as an example, but not used in this case: The aarch64 plugin specifies that, when the
ltSemantic Flag Group is testing flags written by thefloatSemantic Flag Class, Binary Ninja should use theLLFC_FLTcondition to emit the IL expression for that branch.
There are a lot of moving parts to the Semantic Flags system, and specifying them all correctly can be tricky. We hope that this clears up how you can use it for implementing your own architecture plugins. If you have any questions or need support on this, please feel free to contact us.
Conditionals
Quark instructions can all be conditionally executed, depending on flags set when the instruction executes. Luckily for us, these conditions only apply to one instruction at a time (unlike thumb2’s itt blocks), so we’ve chosen to model this with simple if-expressions that skip the instruction if the condition is false. The tricky part about conditional branches is getting the IL labels correct. We need two labels, one to target if the instruction gets executed, and one to target if not. For the expression to test, since we handled flags above using Semantic Flags, we only need to use a flag_group expression. For Quark, we know that each of these groups only tests one flag. If your architecture has conditional branches that depend on multiple flags, you will still only need the one flag_group, as you should have defined those groups as requiring multiple flags as described above.
def get_instruction_low_level_il(self, data: bytes, addr: int, il: LowLevelILFunction) -> Optional[int]:
# ...
after = None
if info.cond & 8:
# Conditionally executed
before = LowLevelILLabel()
after = LowLevelILLabel()
if info.cond & 1: # Execute instruction if condition is true
il.append(
il.if_expr(
il.flag_group(f"cc{(info.cond >> 1) & 3}"),
before,
after
)
)
else: # Execute instruction if condition is false
il.append(
il.if_expr(
il.not_expr(0, il.flag_group(f"cc{(info.cond >> 1) & 3}")),
before,
after
)
)
# Label right before the real instruction, jumping here will execute it normally
il.mark_label(before)
match op:
# ... emit instruction
if after is not None:
# Label after the instruction, jumping here will skip execution
il.mark_label(after)
If your architecture has the concept of conditional jumps instead of conditionally executed instructions, you can emit the same if_expr in the lifting for those conditional jumps, and use il.get_label_for_address to get the IL label objects for the jump targets. Pass that function the address of the next instruction, or the destination, and it will give you the label at the start of the corresponding block. See the 6502 lifter in the NES example plugin.
If your architecture has the concept of conditionally executed blocks of instructions, you will need a fancier lifter that can piece apart the blocks in a way that represents how the control flow actually works. That will likely require overriding analyze_basic_blocks and having a custom implementation for block splitting, which is beyond the scope of this post. Look at the thumb2 architecture’s handling of itt instructions as a reference.
Other
There are a few other loose ends we still need to clean up. Notably, the fact that instructions can write directly to the ip register, which Binary Ninja does not recognize as a jump. For these cases, we split the register setting instructions into a helper function, which checks for setting the ip register, and emits a jump instead:
# Same signature as set_reg so we can easily replace the existing code
def set_reg_or_jmp(size, reg, value):
if reg == self.ip_reg_index:
return il.jump(value)
else:
return il.set_reg(size, reg, value)
Then, we need to replace every instruction that uses set_reg with set_reg_or_jmp:
match op:
case QuarkOpcode.ldb:
il.append(set_reg_or_jmp(4, info.a, il.zero_extend(4, il.load(1, il.add(4, rb_expr(), cval())))))
case QuarkOpcode.ldh:
il.append(set_reg_or_jmp(4, info.a, il.zero_extend(4, il.load(2, il.add(4, rb_expr(), cval())))))
case QuarkOpcode.ldw:
il.append(set_reg_or_jmp(4, info.a, il.load(4, il.add(4, rb_expr(), cval()))))
# ...
case QuarkOpcode.mulx:
# The set_reg_split call could have either half output into ip,
# so output to temporary registers and then set those
il.append(il.set_reg_split(4, LLIL_TEMP(1), LLIL_TEMP(2), il.mult_double_prec_unsigned(4, rb_expr(), rc_expr())))
# We need to modify ra first in case ra == rd, but if ra == rd == ip
# then modifying ra first would cause the jump to happen and skip modifying rd.
# Since ra == rd clobbers ra anyway, we can skip that write and solve this while
# keeping the semantics of the instruction correct.
if info.a != info.d:
il.append(set_reg_or_jmp(4, info.a, il.reg(4, LLIL_TEMP(2))))
il.append(set_reg_or_jmp(4, info.d, il.reg(4, LLIL_TEMP(1))))
case QuarkOpcode.imulx:
il.append(il.set_reg_split(4, LLIL_TEMP(1), LLIL_TEMP(2), il.mult_double_prec_signed(4, rb_expr(), rc_expr())))
if info.a != info.d:
il.append(set_reg_or_jmp(4, info.a, il.reg(4, LLIL_TEMP(2))))
il.append(set_reg_or_jmp(4, info.d, il.reg(4, LLIL_TEMP(1))))
By using helper functions, we were largely able to keep all operations able to be lifted on one line, but opted to leave this modification for last, as it adds clutter in the pursuit of completeness.
Addendum
The Quark architecture aligns pretty well with Binary Ninja’s lifting system. Each instruction can be lifted independently of both the other instructions and the binary itself. For other architectures and file formats, this may not be the case. Instead of being able to lift one instruction at a time, you may need to lift the entire function in one go, constructing the IL instructions and control flow based on relationships between the instructions and the data in the file. For those cases, you will want to implement the new API Architecture.lift_function. A more thorough explanation of how to do this is beyond the scope of this post, but a future post will cover this more low-level concept in more detail. Until then, if you find yourself needing this, you can reference our open sourced DefaultLiftFunction implementation in the API repository. The short explanation is, you will have to go through all the basic blocks in the function and emit IL instructions manually for all of them. There is a bunch of miscellaneous bookkeeping structures that need to be constructed as well, so be sure to reference that default implementation for guidance.
Other topics not covered here:
- Floating Point: Quark doesn’t support floating point instructions, so there wasn’t a reasonable example to give here. Largely, floating point operations are similar to integer operations, with various additional conversion operators whose behavior should be documented in the API docs.
- Register Stacks (again): Certain architectures (like x86’s x87 FPU) have a “stack” of registers which can have values pushed and popped, but are still backed by a fixed set of registers. These are moderately well-supported by Binary Ninja but so infrequently used that their documentation is sparse. Look at the x86 architecture plugin as a reference if you need these.
- Flag Conditions (the system): The older system for flags resolution in Binary Ninja, the Flag Conditions System is separate from Semantic Flags and only supports a subset of the behaviors you can model. We opted to not cover it here as a result. The x86 architecture plugin makes use of this system, though, so if you are curious about it and want to try it yourself, you can reference that implementation here.
Conclusion
Lifting gets us support for many of Binary Ninja’s advanced analysis features: stack resolution, variable creation, and high-level control flow structuring, just to name a few. It goes a long way towards producing good decompilation, and you could even use this plugin now for serious reverse engineering, though you would likely still need to do some manual clean up. Let’s look at the results so far:
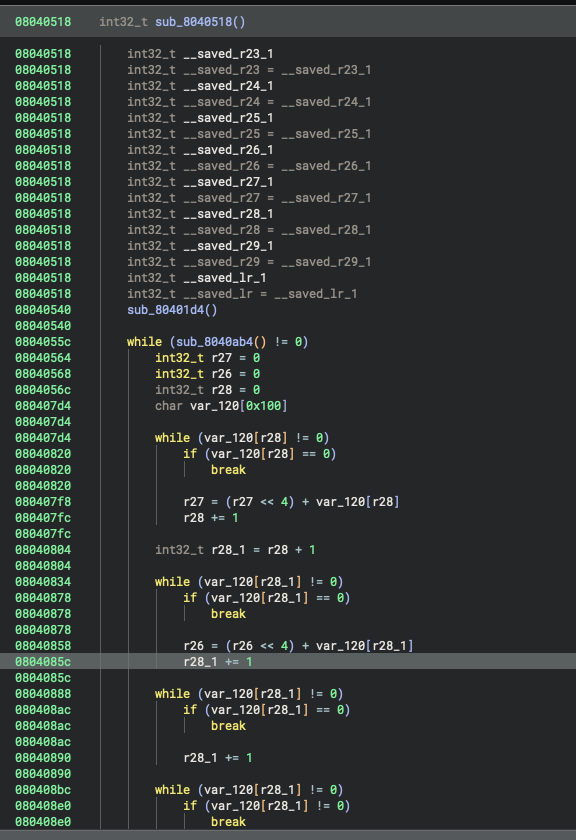
These results are usable already, but we can do better! Function calls still lack parameter information, system calls are unresolved, and statically linked library functions are not identified. Lifting alone cannot solve these issues, so in Part 3, we’ll tackle them by building a custom platform. We’ll define a calling convention so Binary Ninja can properly detect function arguments and return values, set up system call resolution so syscall numbers turn into meaningful names and types, and create Type Libraries and WARP signatures to add rich annotations to decompilation. Together, these additions will take our decompilation from “structurally correct” to a much more useful and readable state. Check out Part 3 where we add platform support!