(No, this is not an April Fools post, but we have one available if you haven’t gotten your fill yet.)
A few weeks ago we kicked off a new tradition for Vector 35, a yearly hackathon. We’ve been wanting to do this for some time now, but over the new-year break we finally got a date on the calendar and spent March 11th-15th working on a variety of fun projects.
The rules were simple: whatever you worked on during the hackathon had to be something that you weren’t doing your daily routine, and it had to sound fun to you. The plan was to explore fresh ideas, try some experiments, or build things you thought were interesting but weren’t otherwise on our immediate to do list.
With only one week of hacking we cranked out a ton of different and useful results. This is also a good chance to introduce different members of the Vector 35 team you might not have been aware of too, so we’ll break down what everyone worked on below.
UI Plugins
The first category of projects are all python example UI plugins. As Rusty had just finished an early implementation of the 1.2 UI plugins several of us were excited to get our hands dirty and create some public examples of neat things that could be done with it.
If you want to try out the following plugins, you can either copy them from your install path inside of the examples/python folder into your user plugin folder or you can also get them from our github and put them in the same destination. We plan to enable some of them by default in an upcoming release as well as provide an interface for enabling/disabling them.
Triage Mode (Rusty)

Rusty chose to focus his hackathon project on a totally new way to use Binary Ninja for triaging malware (or for that matter, to quickly analyze any file). That took the form of several new (very fast) modes of analysis, new UI elements to show a summary view of a binary, and a new “Byte Overview” mode that is reminiscent of old-school DOS hex-editors with a very dense-display of bytes.
The new analysis modes allow you to very quickly (and yet still accurately) analyze a binary by doing the minimal amount of lifting to higher IL forms only when necessary. This mode isn’t good for automated analyses that requires full ILs, but it works very well for quickly getting even large binaries in a useful state for analysis. We’ll post a much more in-depth look at these modes along with performance numbers and comparisons in a future post.

Kaitai Visualizer (Andrew)

Andrew’s idea was in some ways the most ambitious. He wanted to do something totally new and different from what Binary Ninja normally does. Specifically, wire up Kaitai Struct as a parsing library to produce templated dissection of binary files.
Of course, this concept itself isn’t new. Plenty of great tools like 010, Hexinator and Synalyze It! (last two by the same company for different platforms). But could Andrew get something together in a week that would leverage all of the many formats that Kaitai supports using the new Python extensibility Rusty had just added? Thankfully, the answer was yes, and the results are promising both for proving the usability of python UI plugins as well as for a really helpful functionality in Binary Ninja itself.
Thanks to the Kaitai Project not only for the project in general, but also for working with us to resolve some small issues while we were developing the plugin.
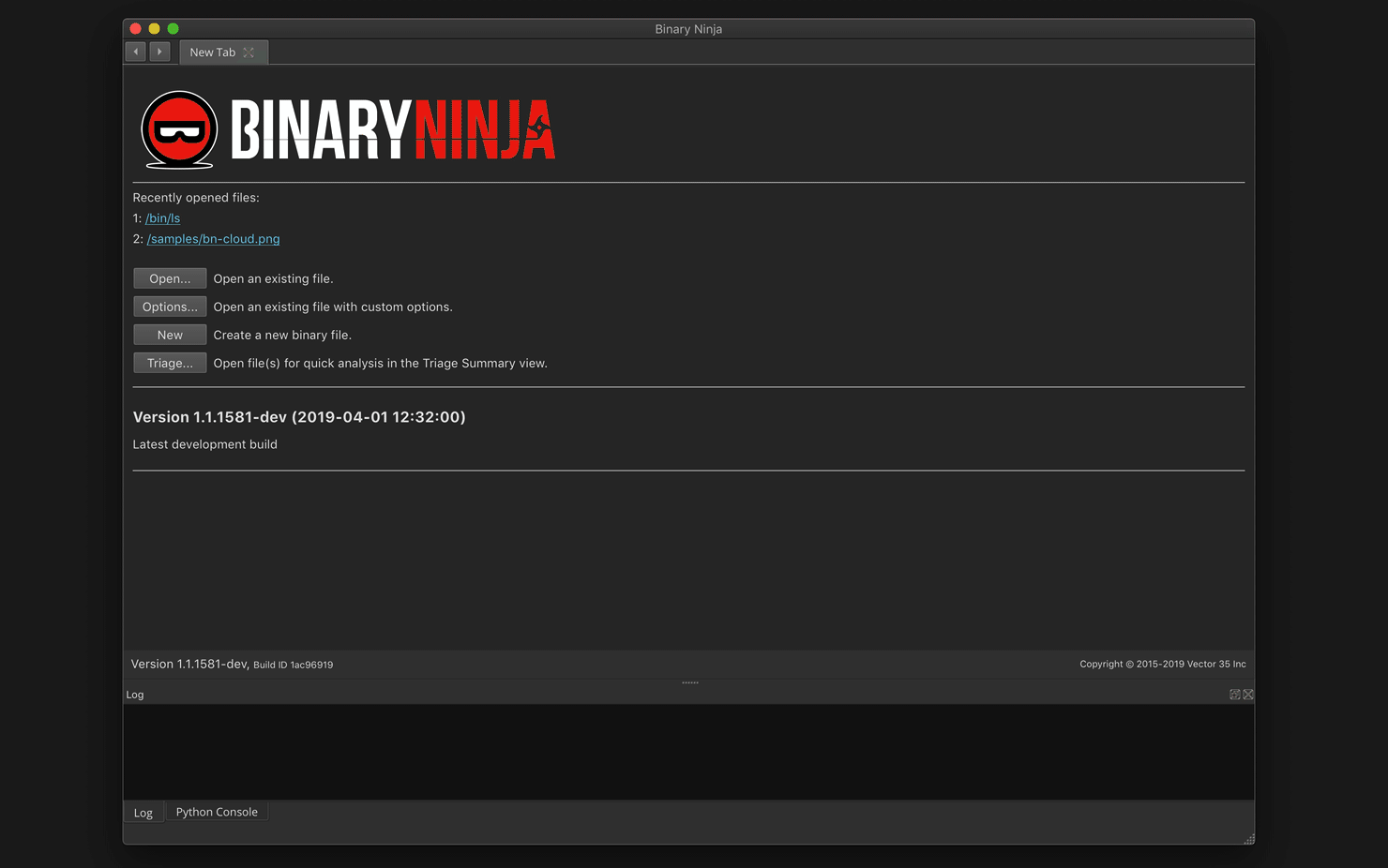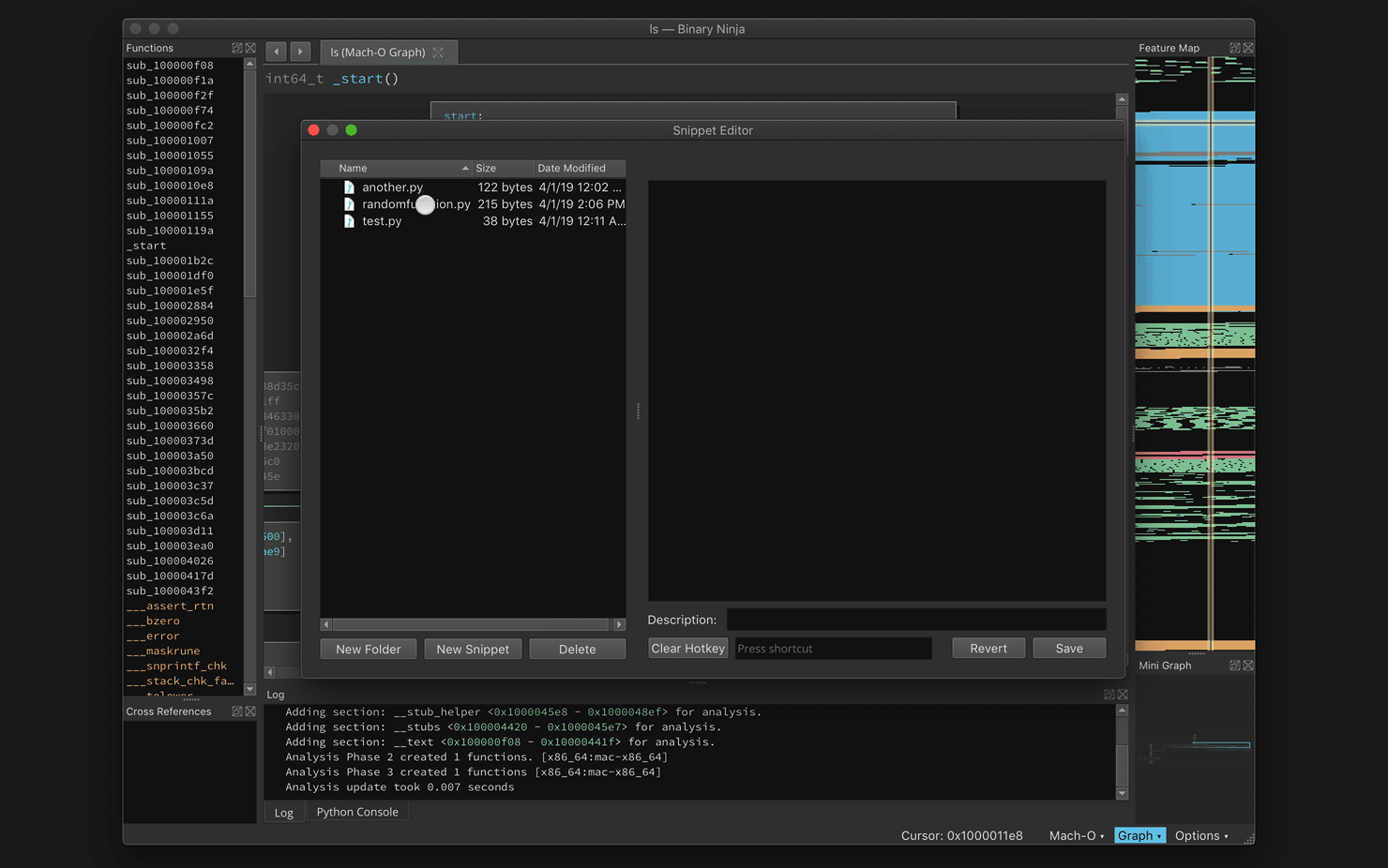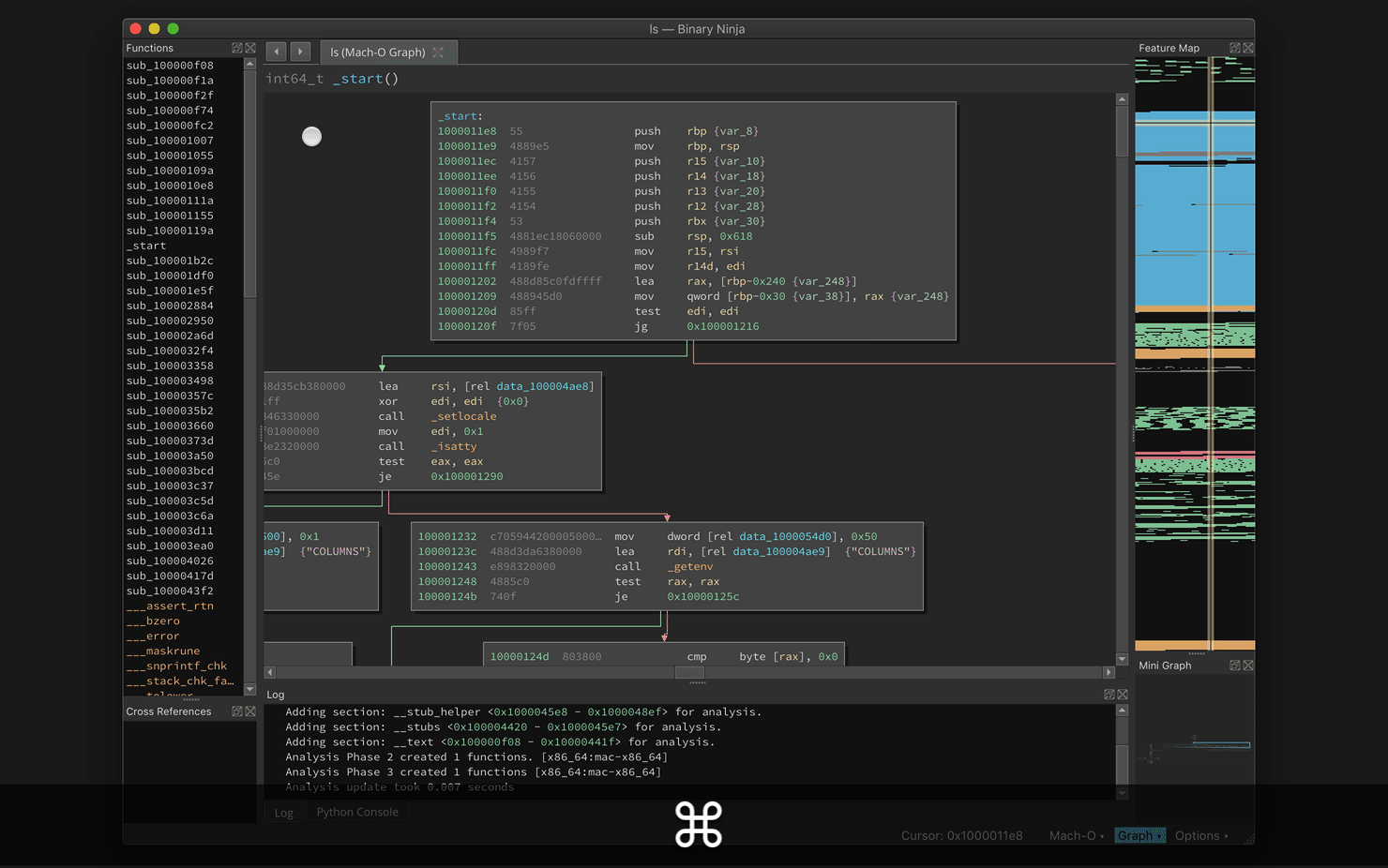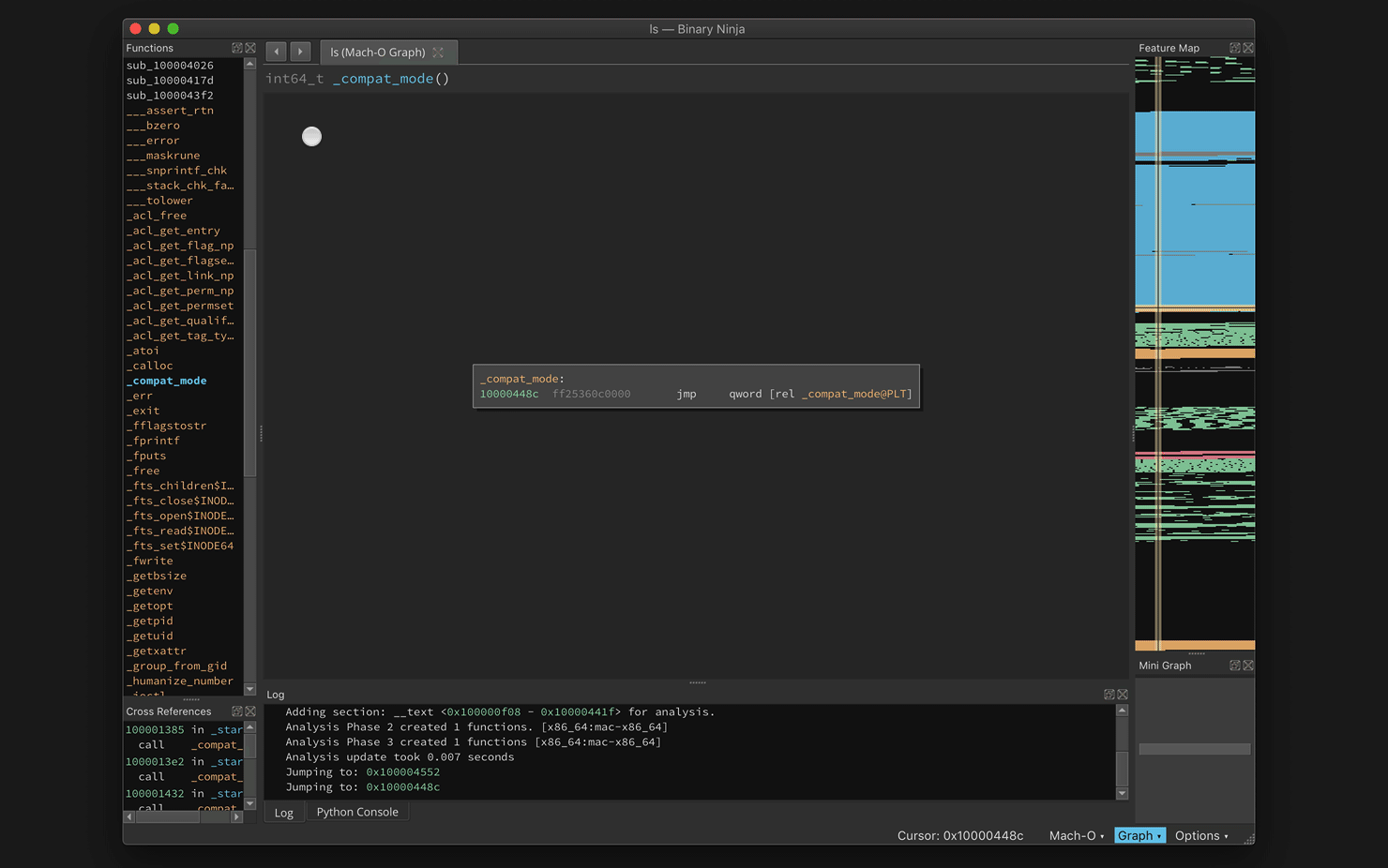
Snippet Editor (Jordan)

One of the most common things we tell Binary Ninja users is that they can do anything in the API. And that’s true! But that’s not always a satisfying answer when someone just wants to run a quick snippet of API code and their options are to either to write a full plugin, restart Binary Ninja to load the plugin, or to use the python console and repeatedly run up-enter.
Those extremes inspired my hackathon project of a snippet editor which lets a user write a small snippet of python and bind it to a hotkey. Of course, individual snippets can also be triggered with the very useful command-palette (Control-P or Command-P depending on your platform – you have been using the command-palette haven’t you?)
Other Plugins
IDB Import (Curtis)

Curtis chose the task of building an IDB Importer for his project. Of course there are (1) several (2) different (3) plugins that will do that already, so why build another mechanism? The short answer is that just because something is doable, doesn’t mean you shouldn’t improve it! In particular, the effort of loading several plugins and using an intermediate file make the process less than the simple experience we’d like it to be for our users.
With that in mind, Curtis worked on adapting Willi Ballenthin’s python-idb library into a tool that could directly open an IDB in Binary Ninja. With very different data models and limitations (two examples among many: BN can’t currently handle comments outside of functions, and IDA can’t currently have overlapping basic blocks in different functions) no conversion script will ever achieve 100% fidelity. That said, whatever we can do to enable users moving between tools ensures that they can use whatever is the best tool for the job.
Unfortunately, Curtis’ plugin is still in development but keep an eye out for an update soon with a link!
Research
Two of our projects ended up more in the “research” category than pure engineering. Our goal wasn’t just to build neat features but also to play with ideas we’d been thinking about but hadn’t yet had time to research.
Function Clustering (Peter)

Peter had been thinking for a while about investigating different clustering algorithms and using them to try to recover object file boundaries from statically linked binaries. This was both an excuse to try different clustering algorithms as well as test them against different parameters in statically compiled binaries.
Of course, while the experiment resulted in no new shipping code, it was still useful none the less. Not only did Peter game more fluency with a number of potentially interesting algorithms, he was also able to produce some useful visualizations to help tune/tweak the various models. You never know when that sort of analysis will have other applications. And finally, if all our experiments were succeeding it would mean we weren’t pushing the boundaries enough!
Improving Function Identification (Brian)

Brian’s baby has long been linear sweep and you can expect a much more fully featured analysis from him in the future updating our results, publishing our test set and including new tools like Ghidra. That said, for the hackathon, Brian focused on two new features to improve function identification.
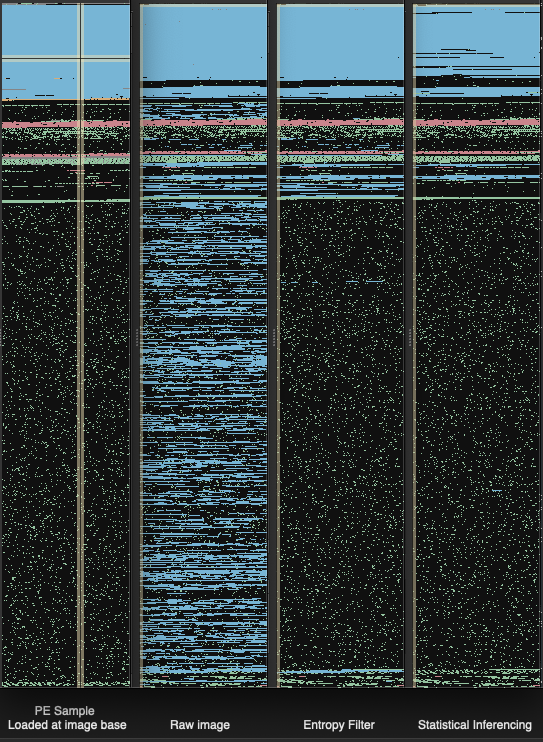
The high level goal is to reduce the false positive function identification rate, especially in the face of packed binaries, malware, or loading raw images and applying relaxed code section semantics. In the image below, we simulate this last scenario visually with our feature map. If you’re not familiar with our feature map, it is a very simple linear representation of the binary which overlays analysis artifacts such as functions, strings, and data.
In the image, moving from left to right, we first have a sample PE image loaded and analyzed with default settings. This first feature map represents what would be considered ideal behavior with an understanding of where code should and shouldn’t be. Scanning the image from top to bottom you see code, structured data, compressed/encrypted data, followed by some more structured data. The second feature map shows the results of loading the PE as a raw image, assigning read only/execute permissions to the entire file, and then running linear sweep. As can be seen, there are an enormous amount of invalid functions being created and we wanted to improve the results.
The first technique investigated was the application of entropy to reduce the scope of the function search space. The idea being that really high or low entropy areas can simply be excluded as potential code regions. This was implemented and the results are shown in the third feature map where we took the same steps to load the PE as a raw image.
The second technique generated a model from a population of functions identified with high confidence and applied the model and a distance function to make a classifier. Then, candidate functions are evaluated using that classifier. The results are shown in the final feature map (which has the entropy technique disabled).
The new linear sweep entropy heuristic is already available on dev and should dramatically improve analysis for larger firmware blogs with intermixed content and code. The statistical inference method is still undergoing some testing but should be available soon.
Bug fixes (Ryan)

Rather than focus on a particular set of features or a new functionality, Ryan had some pet peeve problems in the current API and analysis that he wanted to work on. Accordingly, he took a break from his main task of working on building our our support for type libraries to knock out a number of important bug fixes.
Recap
We’re extremely happy with the results from this hackathon and we look forward to making this a repeating event. We hope you enjoy all the new functionality and improvements as well.