We’re excited to announce Binary Ninja 3.0 is live today! Most of our stable releases have been quarterly, but this 3.0 release took over six months, and this list of improvements really justifies it.
So what has this wait brought you? Here’s our top eight favorite (with many more below).
- Fresh UI
- Pseudo C
- API Improvements
- Stack and Variable Views
- Workflows
- Enterprise: Offline Updates
- Function Parameter Detection
- M1 Native
In fact, this release is so chock full of good stuff that five of the top nine all-time most up-voted features are shipping in this release! (Related: go up-vote your favorites for upcoming releases.)
Major Changes
Fresh UI
The headlining feature of 3.0 is a whole set of UI improvements that not only improve the ways you can customize Binary Ninja, but also make the out of the box experience far cleaner and more efficient.
So what’s that look like?
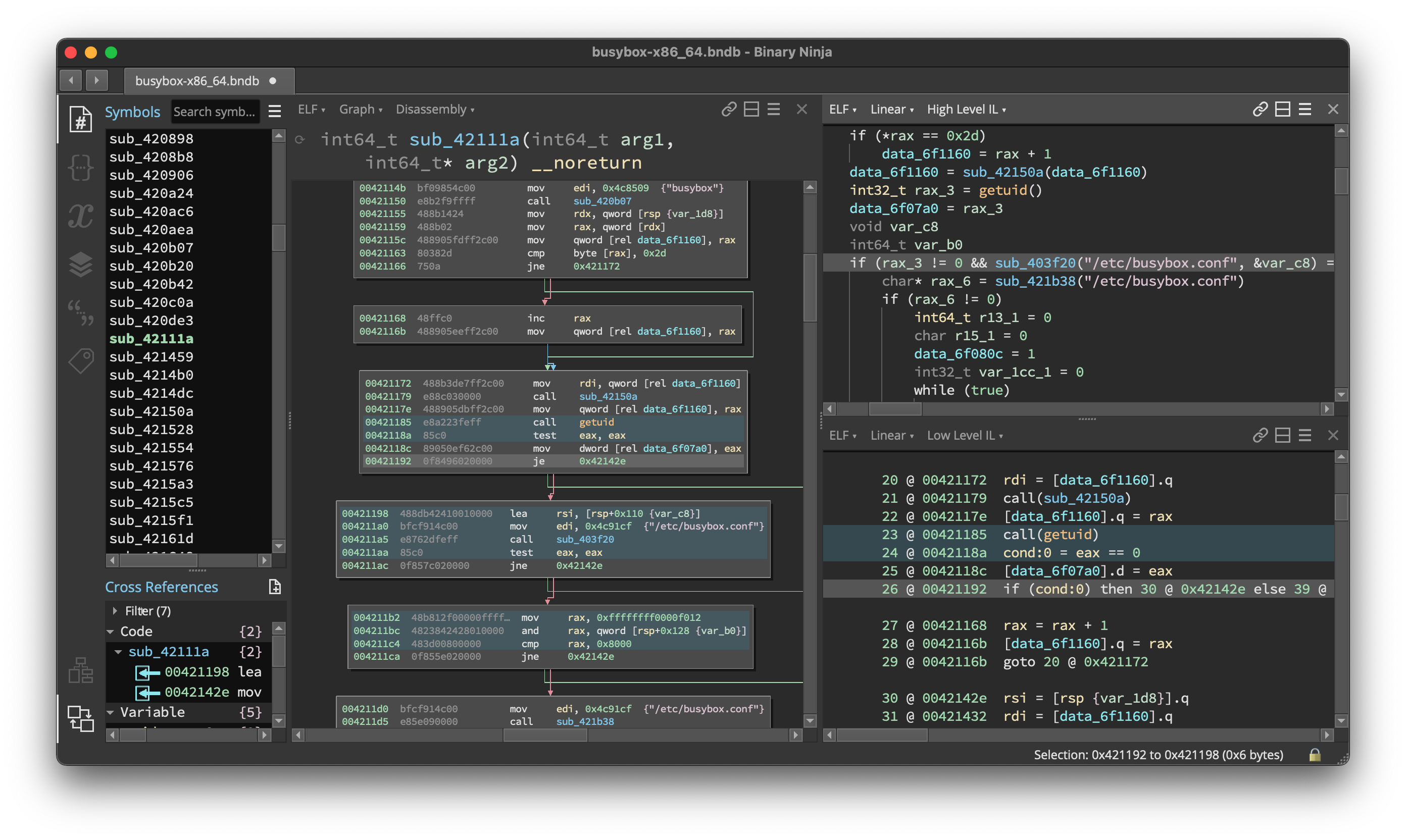
The two most visible changes are the introduction of the sidebar and the ability to split the main view area into panes. The sidebar panels include a number of brand new UIs (we’ll cover the stack and variable views below). The remaining views have been adapted to the new panel UI to make switching between them easy with configurable hotkeys. This keeps important information like what type you’re working with visible, while keeping the binary being analyzed in view.
If you still like the older full-screen strings or type views, don’t worry, they’re still available! In fact, they’re even easier to find now that each pane has a header that lets you switch view types.
Speaking of the pane header, not only can you select the type of view and change common view options, but you can also drag-and-drop this header to re-arrange panes.
Additionally, the header has a few new icons. The chain link icon lets you select which panes are synchronized. Use custom sync groups or disable sync entirely for any panes you want.
The split icon is a bit magic. The first split you make will be vertical, and future splits will be horizontal. You can even see the icon change between the two orientations. If the default behavior isn’t to your liking, you can either tweak the settings (ui.panes.columnCount, ui.panes.headers, ui.panes.newPaneLocation, ui.panes.splitDirection, ui.panes.statusBarOptions) or even more simply, you can override the current split by holding SHIFT to toggle the current direction.
Finally, the ☰ menu contains a number of settings for each pane. Keep an eye out for it in other places, such as some of the new side panels! The x icon, you will surely be shocked to discover, closes the pane.
While you’re experimenting with different views, make sure to check out the newly enhanced synchronization between disassembly and other ILs. No longer are you limited to a single instruction mapping; multi-mappings are explicitly visible in the UI (visible as blue highlights in the above full screen image).
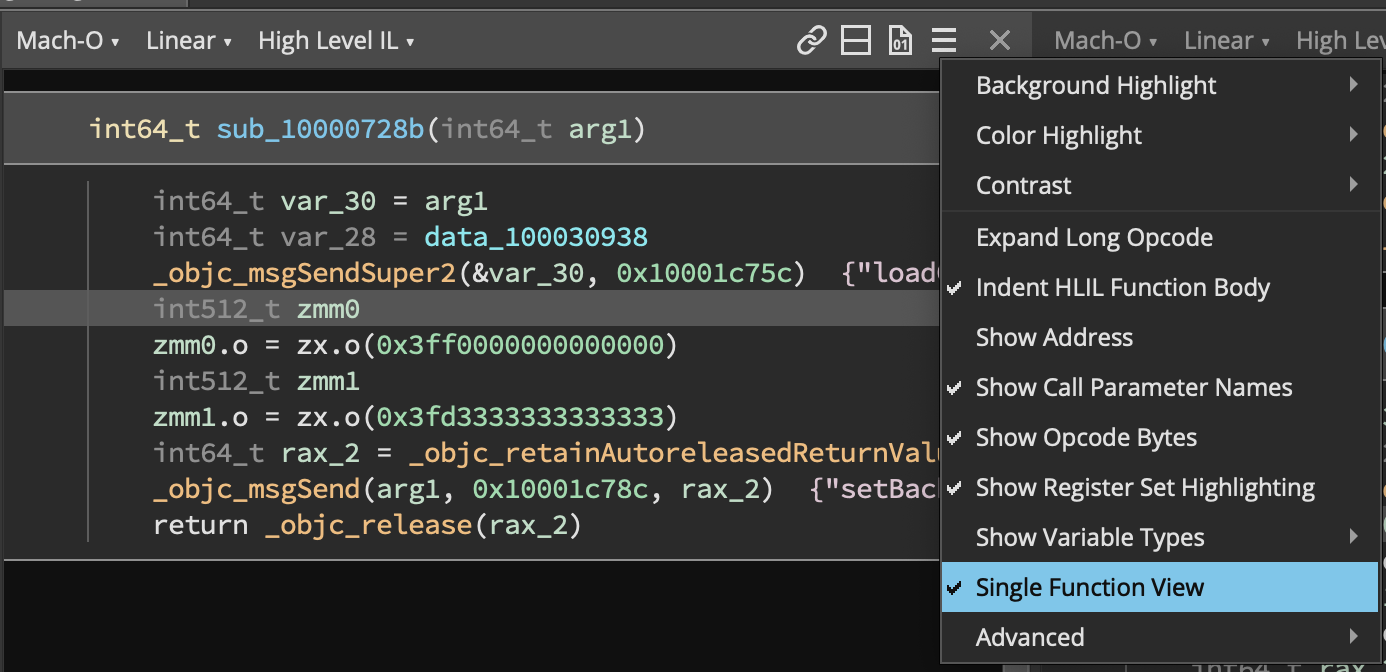
Finally, one other important UI-related feature made it in 3.0—single function linear view. Apparently not every likes the freedom to infinitely scroll between functions. So if you too like artificially limiting your view, check it out in the linear view options menu (☰).
Pseudo C
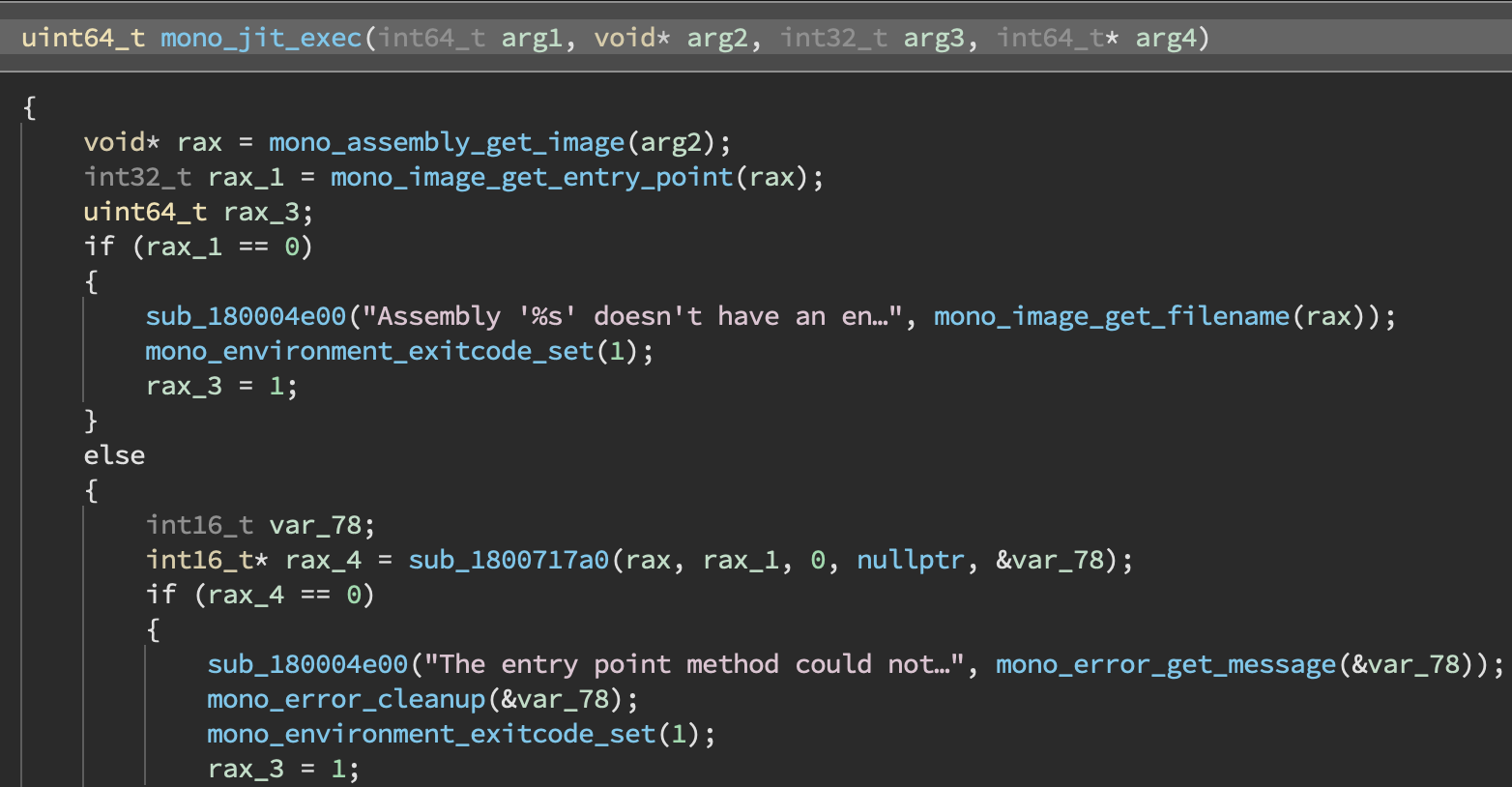
Since the release of our decompiler a year and a half ago, one of the most common questions we received was “when will you have C output and not just HLIL?”. The answer is now! Available from the view selection menu or the command palette, Pseudo C is a new type of both linear and graph view. Since it’s based on the same rendering as all other views, it has all the important features you’d expect—ability to name, comment, change types, change display types, sync with other views, etc.
While we still think HLIL has a place (being more accurate and concise than C output in many situations), we realize there’s a time and a place for C. You can even set this view to be your default for graph, linear, or both using the ui.view.graph.il and ui.view.linear.il settings.
And of course, changes made in other views are updated live and automatically in the Pseudo C view. For example, using the magic s hotkey (“make me a structure and guess the size at this location”, or “make members here”) creates structs in Pseudo C, not just HLIL.
The current goal of Pseudo C is to translate the existing HLIL semantics into syntactically correct C while still maintaining as much context as possible. This is not a totally new mode of decompilation, but leverages the existing information in HLIL and presents it in a way that some users may be more comfortable with.
This is just the start of our language-specific decompilation plans though, so keep an eye out.
API Improvements
The Python API had a substantial refactor, with far too many changes to list in this blog post. The biggest change is that the API now has type hints almost everywhere. This makes writing against it far easier with the help of code completion, and allows you to write more robust code with the help of type checkers. Here is a selection of some of the more substantial changes:
- Adding Python 3.7 compatible type annotations
- Refactoring many iterators into generators for significant performance improvements
- Massive number of cleanups and fixes
- Standardizing naming conventions
IL Object Overhaul
IL instructions have been substantially refactored. In Binary Ninja 2.4 an instruction was defined by an operation and a dictionary entry. Although this was easy to implement there were some downsides to this implementation. The new implementation creates a class for each instruction that improves speed, adds type hinting, and supports instruction hierarchies.
Binary Ninja 2.4:
for i in il:
if i.operation in [LLIL_CONST, LLIL_CONST_PTR, LLIL_EXTERN_PTR, MLIL_CONST, MLIL_CONST_PTR, MLIL_EXTERN_PTR, HLIL_CONST, HLIL_CONST_PTR, HLIL_EXTERN_PTR]:
print(i.value)
Binary Ninja 3.0:
for i in il:
if isinstance(i, Constant):
print(i.value)
The only drawbacks to this approach are that the instruction hierarchies are rather complicated, and that there are a lot of abstract base classes. To help with this, we’ve implemented a few APIs to visualize these relationships.
show_hlil_hierarchy(),show_mlil_hierarchy(),show_llil_hierarchy()- show the entire graph hierarchy for a given ILshow_hierarchy_graph()- displays the graph for the current instruction
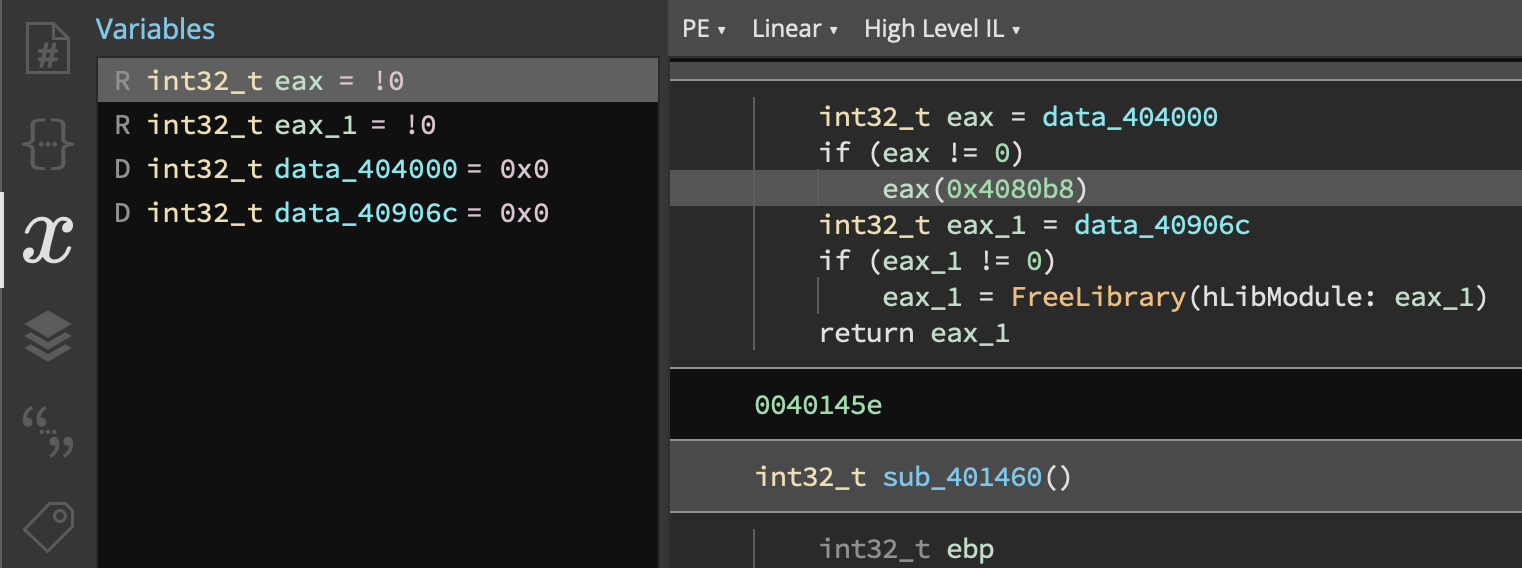
Variable Objects
In Binary Ninja 2.4 it was rather unintuitive to set the name or type of a variable.
Binary Ninja 2.4:
f = current_function
v = f.vars[0]
f.create_user_var(v, v.type, "new_name")
f.create_user_var(v, Type.char(), "")
Additionally, it was only possible to get the name of a variable when accessed through some, but not all, APIs. This was a common problem that led to a lot of confusion. In 3.0, Variable objects must always contain the function in which they’re defined and thus the Variable object always has consistent behavior regardless of which API generated the object.
Binary Ninja 3.0:
f = current_function
v = f.vars[0]
v.name = "new_name"
v.type = Type.char()
DataVariable Objects
DataVariable objects have been greatly enhanced. In the core, a DataVariable is simply a Type and an int address. The 2.4 API roughly replicated that abstraction. In Binary Ninja 3.0 the object has a lot more utility.
Prior to 3.0 a frequent question was: “How do you set the name of a DataVariable through the API?” The answer was “You don’t, instead create a symbol at that location.” This is the same way function names are handled. Although this abstraction serves us well internally, it doesn’t make for an intuitive API. Thus DataVariable now has convenient methods for setting name and type.
Binary Ninja 3.0:
data_var = bv.get_data_var_at(addr)
data_var.name = 'foobar'
Or if you prefer to give the DataVariable a more complete symbol:
Binary Ninja 3.0:
data_var = bv.get_data_var_at(addr)
data_var.symbol = Symbol(DataSymbol, addr, short_name, full_name, raw_name)
Setting the type in 3.0:
data_var = bv.get_data_var_at(addr)
data_var.type = Type.int(4)
Performance Improvements
The API has some substantial under the hood changes that allow for increased speed and utility. Binary Ninja’s APIs frequently need to return lists of objects that have been constructed natively, then reconstructed in Python. This Python type creation can take a significant amount of time. In 3.0, we try to delay or eliminate creation of these types where possible in many common cases.
- 100 iterations of the following “code chunks” were run
- 2911 functions were present in the test binary
- 6363 symbols were present in the test binary
- 4096 types were present in the test binary
bvis aBinaryViewobjecthlil_funcis aHighLevelILFunction
| Code (100 Iterations) | Time (Binary Ninja 2.4) | Time (Binary Ninja 3.0) | Factor |
|---|---|---|---|
bv.functions[0] |
0.98s | 0.035s | 28x |
bv.types['_GUID'] |
5.90s | 0.0035s | 1688x |
bv.symbols['shutdown'] |
4.62s | 0.00068s | 6814x |
[i for i in hlil_func] |
0.0098s | 0.0026s | 3.7x |
These performance improvements were made by creating new objects that serve as wrappers around Lists and Maps which then incrementally construct the contained objects on demand. Although you’d usually use a generator for this, it’s not possible to do for maps, and there is a lot of existing code that does things like function.basic_blocks[0]; this solution gives performance improvements while making the transition to 3.0 as painless as possible.
bv.symbolsreturns aSymbolMappingobjectbv.typesreturns aTypeMappingobjectbv.functionsreturns aFunctionListobjectcurrent_function.basic_blocksreturns aBasicBlockListobject
AdvancedILFunctionList
Additionally, we’ve provided some new, speedy ways of getting the “Advanced Analysis Functions” i.e. HighLevelILFunction and MediumLevelILFunction. Prior to Binary Ninja 3.0 the de facto way of iterating over HLIL functions was something like this:
for f in bv.functions:
do_stuff(f.hlil)
Although that works, it is not as fast as it could be. In fact, it isn’t even how the core would iterate over HLIL functions. What the above code basically says is:
“For each function in the BinaryView, generate the HLIL, wait until the IL is fully generated, then do_stuff with that IL.”
Modern machines have lots of cores that can be put to work, and the previous code really makes poor use of them. Here’s where the AdvancedILFunctionList object comes in. This object allows users to request that many IL functions be generated at once and then doles them out as needed. This dramatically reduces latency, allowing your Python script to do much less waiting. Using the API is straightforward, as it’s a generator that can be directly iterated.
for f in AdvancedILFunctionList(bv):
do_stuff(f.hlil)
Using the AdvancedILFunctionList as above should result in at least a 50% reduction in time spent waiting for IL generation. There are, however, some tweaks you can use to make it go even faster. The second parameter is the preload_limit which defaults to 5—a very low, but reasonable, number which should be safe for pretty much any computer Binary Ninja is running on. It is possible in situations where you’re not severely constrained on RAM to bump this number up significantly and achieve time reductions up to 75%. In our testing we’ve found values of 400 and greater to produce even better results at the cost of additional RAM. Use the parameter with caution!
>>> timeit.timeit(lambda: [f.hlil for f in bv.functions], number=10)
30.704694400999983
>>> timeit.timeit(lambda: [f.hlil for f in AdvancedILFunctionList(bv)], number=10)
15.333463996999967
>>> timeit.timeit(lambda: [f.hlil for f in AdvancedILFunctionList(bv, preload_limit=400)], number=10)
7.710202791000029
>>> timeit.timeit(lambda: [f.hlil for f in AdvancedILFunctionList(bv, preload_limit=1000)], number=10)
7.229033582
Finally, the 3rd parameter is functions. This is convenient for situations where you’re interested in going through your own collection of functions. For instance, if you’d like to iterate all the callees of the current function you could do the following:
>>> len(current_function.callees)
5
>>> timeit.timeit(lambda: [f.hlil for f in current_function.callees], number=10000)
2.969805995999991
>>> timeit.timeit(lambda: [f.hlil for f in AdvancedILFunctionList(bv, preload_limit=10, functions=current_function.callees)], number=10000)
2.4418122349999294
As you can see, there is a small performance gain, but not as much due to the small list of functions.
All of this in addition to the migration from Qt 5 to Qt 6 (and PySide2 -> PySide6) and we’ll be working hard with plugin authors to make sure as many as possible are updated.
Stack and Variable Views
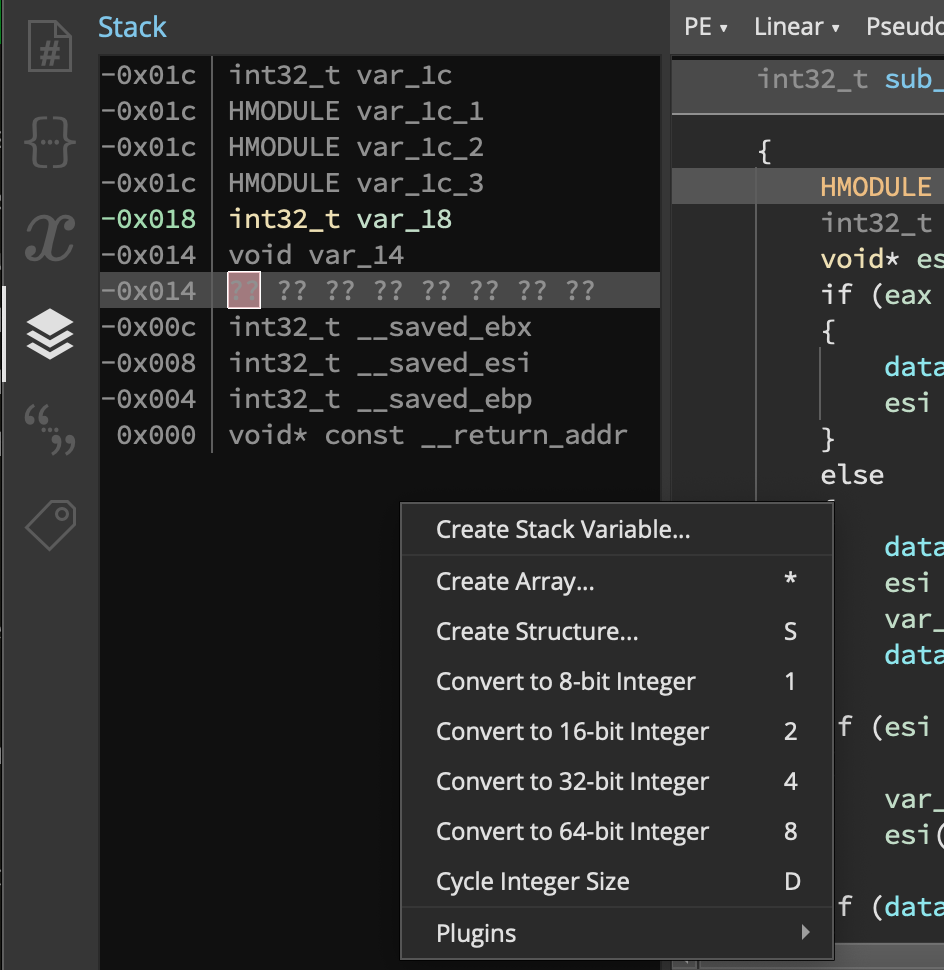
The new UI not only brings updated versions of existing views, but also introduces completely new features that have been some of our most requested: stack view and variable view.
The stack view lets you quickly see the current stack layout, but can also be used to create and modify structures or variables on the stack.
Likewise, the variable view lets you see an overview of the variables in the current function, navigate to their definition via double-click, and change their name and type just like the stack-view.
The difference between them is that while the stack view represents the overall state of the function’s stack, the variable view is context sensitive. This means that it can show you all sorts of information about the state of variables from the binary. Consider the following example, where selecting the inside of a condition shows that the value-set analysis knows the state of the variable at that location. This combination of the power of Binary Ninja’s program analysis engine under the hood with an easy to access UI is unique in the reverse engineering landscape.
Workflows
Analysis Passes are dead, long live Workflows! While the name was a matter of some debate internally, the value of the feature was not. One of our top voted feature requests, Workflows represent a game-changing ability in the space of reverse engineering. Easily worthy of an entire major version bump all on its own, the new Workflow system lets third-party plugins completely change how analysis occurs in Binary Ninja. Workflows are designed to make it not only possible, but easy, to make such major changes as rewriting IL, changing the order of analysis, enable or disabling certain features, or even completely customizing how analysis occurs on specific files.
While there are many more uses in the works from both Vector 35 and others, current examples include the ability to inline functions to improve data flow analysis (the default value set and constant value propagation are not context-aware nor inter-procedural to avoid state-space explosion), custom fixups for Objective-C files, and an example that entirely replaces the core tail call detection with an external plugin.
To use Workflows, first enable the settings:
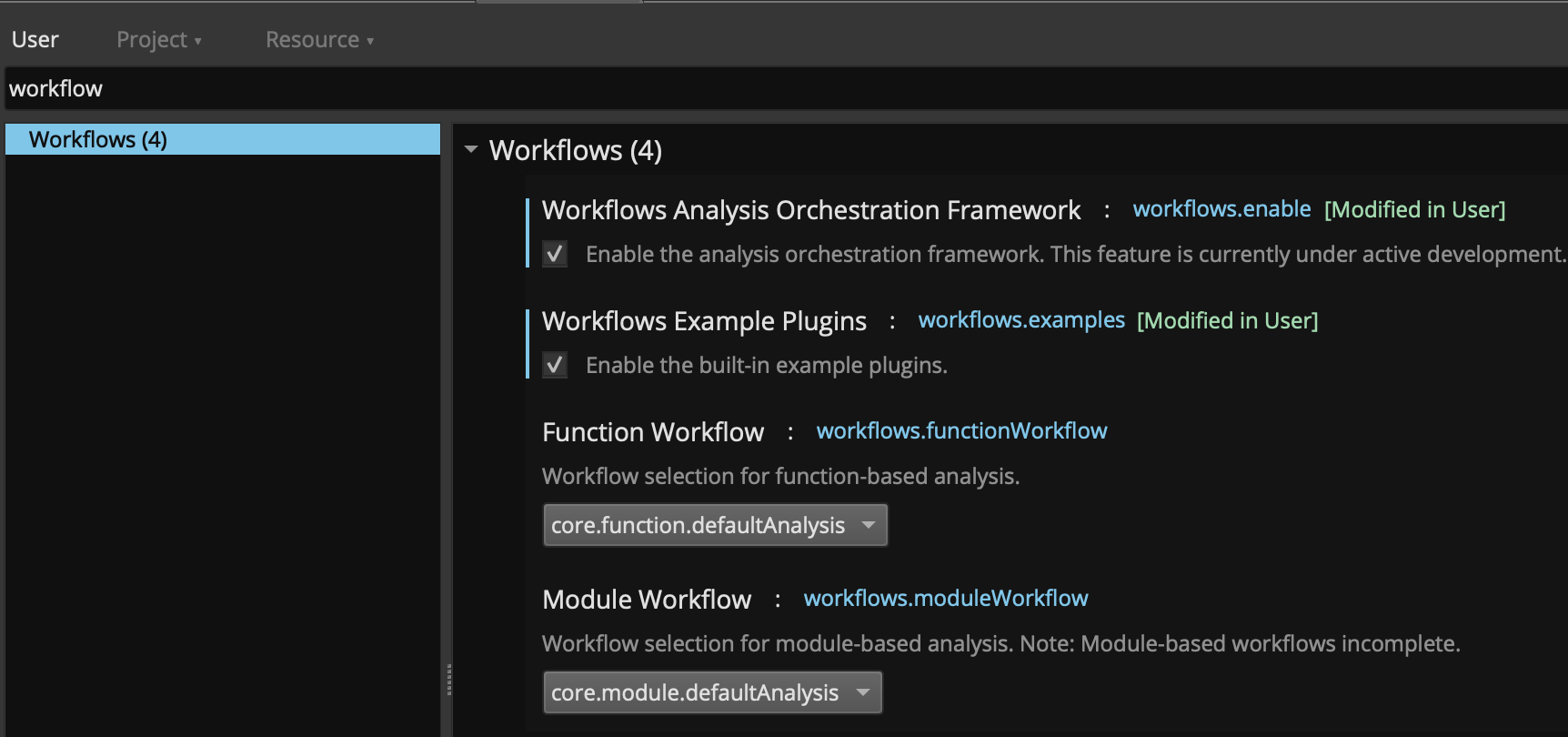
Next, if using a community plugin such as Objective Ninja, follow the build instructions and copy the plugin to your user plugin folder. Once you restart Binary Ninja, you can select that plugin from either the Function Workflow setting or the Module Workflow setting.
Here’s a before and after preview of the improvements the Objective Ninja plugin brings:
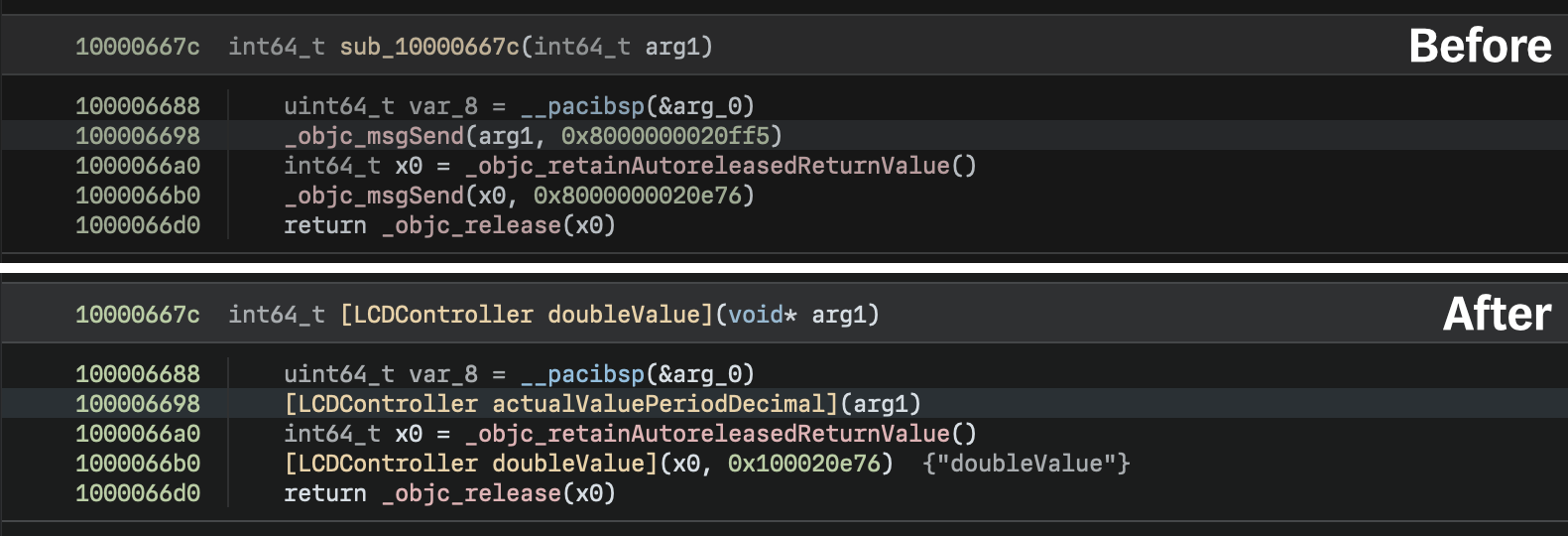
Once you enable the Objective-C Workflow, you’ll notice a dramatic improvement in analysis of Objective-C files. One of the ways this is accomplished is by rewriting calls to the msgSend dispatch function, replacing them with IL calls to the actual virtual methods. This improves not only the readability of the code, but produces code cross-references which make the overall analysis process much easier.
As of the 3.0 launch, all Workflows must be written in C++, but exposing the rest of the required APIs to Python is planned for a future update. Currently, Workflow documentation is available via the built-in console using Workflow().show_documentation()
We’re looking forward to seeing what other interesting ideas the community comes up with to take advantage of Workflows!
One of the neat side effects of this Workflow design was the ability to have introspection into the internal analysis processes of Binary Ninja. Ever wanted to see what a flow graph of all parts of the Binary Ninja analysis would look like?! Well, now you can (easier to see version available via Workflow().show_topology() in an updated scripting console near you):
Enterprise: Offline Updates
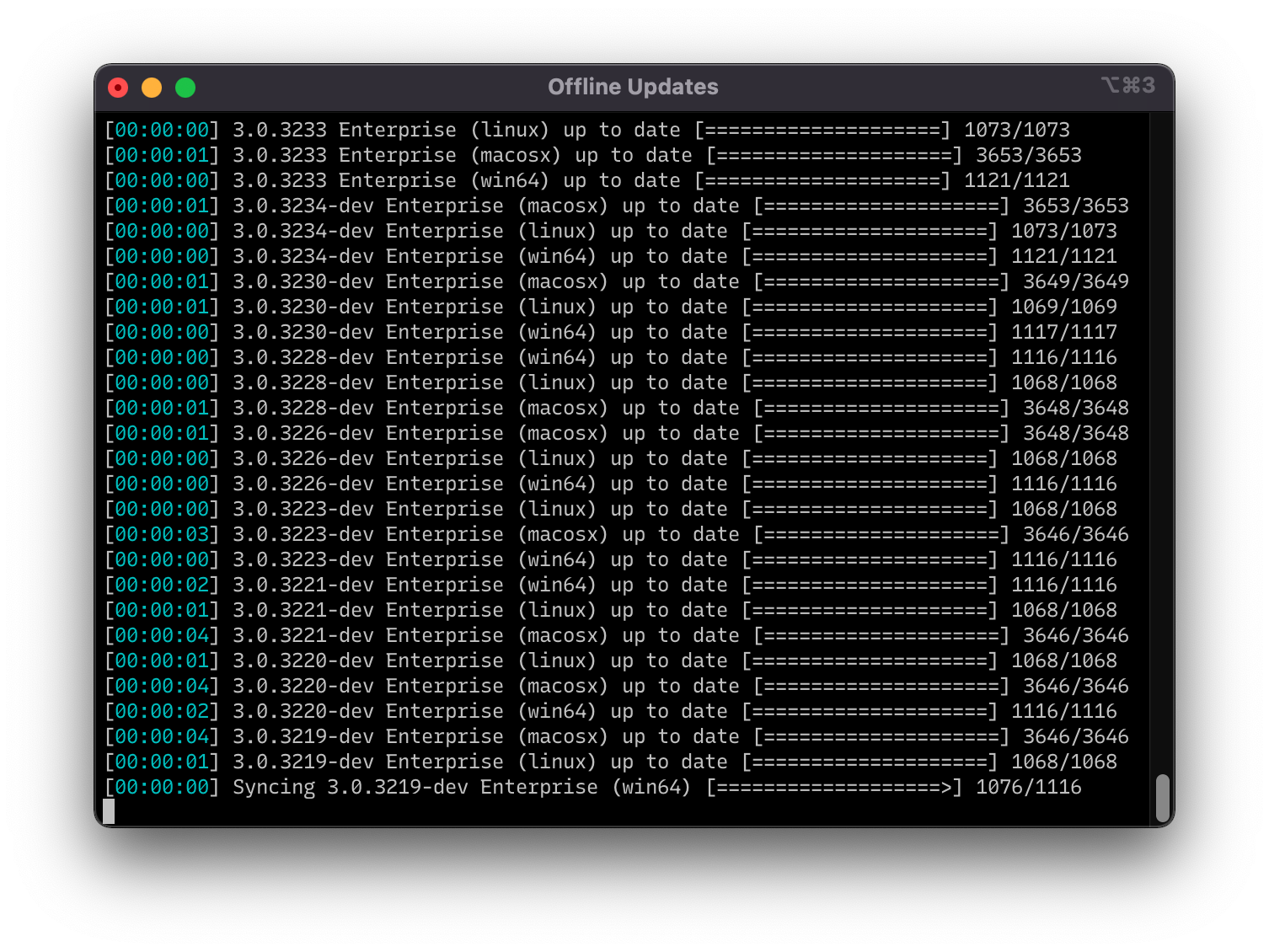
While we only launched Enterprise with collaboration features two months ago, the Enterprise development team has been hard at work with a steady stream of improvements. Among many improvements based on customer feedback, one that stands out is the new offline updates capability.
The main goal of Enterprise is to enable teams to reverse better together. Since many reverse engineering teams are on air-gapped networks that make online updates painful, we knew offline updates were a necessity. With 3.0, an Enterprise server can act as the update server for all local clients, even letting them switch back and forth between versions—all without access to the internet!
Function Parameter Detection
Function parameter detection has been vastly improved. Prior to 3.0, if a function had some context saving routine which stored all the registers, our analysis would assume those were all parameters to the function. While this is a technically correct definition, it severely impeded readability as these parameters would propagate to all callers of the function and to all callers of that function … and so on. We solved this issue (2661, 2307) by recognizing when excessive numbers of non-standard registers are being used for parameter passing and then preventing those from being used to determine parameters. The results speak for themselves:
Before

After

M1 Native
While we technically have had M1 macOS support for over a year, it was previously only available in the core due to lack of Qt and PySide support. Additionally, while the Qt 6 preview branch was available in march of last year, 3.0 marks the first stable release that ships with Qt 6 and native M1 macOS support! As great as Rosetta 2 is, being able to get the absolute most performance per watt for your RE needs sure is better.
Other Updates
Architectures
Thanks to our open source architectures, you can check out any of the improvements to each architecture during the last release in their respective repositories:
Note that other architectures are included with Binary Ninja that had no changes during this release and are not listed above.
UI Updates
- Feature: A welcome / onboarding currently serves as a simply way to show new features, but will in the future allow easy selection of familiar defaults for users of other tools (and can be disabled entirely via the
ui.allowWelcomesettings) - Feature: File/export menu allows exporting a file in all possible linear flavors
- Feature: Triage View: Ability to copy addresses via one click from triage as well as new items showing endianness, file path, size, and hash info, and library names
- Feature: Many new flavors (1, 2) of offsets are available from the “copy address” menu
- Feature: If you’ve needed to convert something to a struct but couldn’t, now you can, some of the time
- Feature: Python scripting console (UI only) now offers a default startup file (2579)
- Feature: New Global Area that supports displaying Log/Python with multiple layouts, combining, splitting and drag-and-drop
- Feature: Migration to Qt 6 complete
- Feature: Many views that previously had filter boxes that weren’t discoverable (mainly strings and types) are now enabled by default, and the filter boxes are focusable with CMD/CTL-f
- Feature: Recent list right-click menu supports open with options
- Feature: Can now collapse-all/expand-all in type views
- Feature: Tabs show an icon when unsaved changes exist
- Feature: UI Annotations can be disabled using the
rendering.annotationssetting - Feature: Warn when editing bytes covered by a relocation
- Feature: Report Tabs can be split to a new destination
- Improvement: On MacOS Binary Ninja now treats .app bundles as folders
- Improvement: Linear view now has full feature parity with graph view for hovers, clicks, keys, etc
- Improvement: Changing the type of the first member of a struct behaves as expected as long as your expectations are reasonable
- Improvement: Settings UI now more clearly delineates sections
- Improvement: More consistent
notifyViewChangedcallbacks - Improvement: Different files can have different layouts
- Improvement: create_user_function is now more intelligent about selecting the appropriate architecture if none is specified
- Improvement: Navigation no longer selects a line
- Improvement: Multiple Tag UI improvements (including 2624, sidebar refactor, 2620, 2537, 2204, 1935)
- Improvement: “Theme” setting relocated
- Improvement: The “save”, “cancel”, “don’t save” buttons on closing an unsaved file were re-arranged to match system defaults and CTRL-D or CMD-D will now cancel
- Improvement: When changing type of an extern, the default is now the existing type, and they also use the right dialog
- Improvement: Discrete GPU no longer activated when not needed
- Improvement: Analysis hold icon no longer blocked when additional background tasks are running
- Improvement: MacOS icon updated Apple’s latest guidelines
- Improvement: Where comments are shown, most of the time
- Improvement: Multiple performance improvements (including 2721, 2720)
- Fix: Menu items that should be disabled, no stay disabled
- Fix: Function comments are now correctly homed
- Fix: A number of… special letters were previously not able to start the filter/searching
- Fix: Graph view tooltips no longer hide
- Fix: Copying more bytes of an opcode than are visible for now works as you’d want, even if you didn’t expect it
- Fix: Cancelling “would you like to save” no longer opens an extra window
- Fix: Navigation when clicking a type from a filtered list
- Fix: Copy/Paste when first byte was a null
- Fix: Some shenanigans with multi-line clicking and dragging
- Fix: Pointer offsets were sometimes displayed incorrectly in LLIL and MLIL
Binary Views
- Feature: COFF .obj support
- Improvement: Handling of overlapping sections in Mach-O files
- Improvement: PDB Symbol Support
- Improvement: Linux kernel module imports show on the symbol list
- Improvement:
__android_log_asertis now a noreturn function - Fix: Custom Binary Views using only user segments now work
- Fix: Rebasing is possible without an associated platform
- Fix: Re-opening an existing view could lose architecture association
Analysis
- Feature: When lifting nonsensical pointer values, two new features are there to help you figure it out: Tags are created for specific problem cases, and a new “Show Stack Pointer Usage” option is available from LLIL views
- Feature: Several other tags and log messages are now created similar to the previous feature to help improve the process of developing architecture plugins
- Feature: Now uses the segment heap on windows for ~20% performance increase (note you must re-install using the re-installer or manually set the appropriate registry keys)
- Feature: New onboarding dialog – purely informational for now, but future updates will add customization as a part of the onboarding workflow
- Feature: When making annotation changes to a function, the function is automatically converted to a “user function”
- Improvement: Cross-references are also collected from HLIL
- Improvement: Callees are now properly serialized when saving BNDB to disk
- Improvement: Can now set stack adjustment on imported win32 APIs
- Improvement: Now with 44% less calling convention confusion
- Fix: ConstPointerLoad MLIL translation
- Fix: Bug where the first function analyzed could sometimes use different analysis settings than specified
- Fix: Direct jumps into externs are analyzed properly
- Fix: Some missing strings
API
- Feature: DebugInfo API – a new set of APIs designed specifically to allow for third-party plugins to provide accurate debug information such as symbols and types before traditional analysis kicks off
- Feature: StructuredDataView is dead, long live TypedDataAccessor
- Feature:
SHIFT-awill now make wide/UTF strings - Feature: Variables are separated off of functions into
.varsand.aliased_vars - Feature: New liveness API
- Feature: Development API documentation and user documentation are now online and track the latest development release
- Feature: Implement PEP-0561
- Feature: IL functions can now be distinguished via new APIs
- Feature: a new UIContext method lets you check if a BNDB is already open
- Feature: New
get_data_offset_for_addressAPI added - Feature: New APIs to enable accessing IL vars from their python functions
- Feature: HLIL Plugins are now possible without requiring UI plugins
- Feature:
$ADDR in current_functionis now a thing - Improvement: Setting MetaData now properly dirties a view (if properly dirties is actually a thing)
- Improvement:
DeleteAutoVariablefamily of APIs removed - Improvement: Any API that takes a type argument can optionally take a string and treat it as a type declaration instead
- Improvement: Potentially confusing repr on Types
- Improvement: Multiple 🦀 API improvements (2864, 2521)
- Improvement: Multiple improvements to the build process (including 2839, 2665)
- Fix: MediumLevelILCallParamSsa object is not iterable
- Fix:
get_install_directoryfixed for headless uses - Fix: Some better support for Really Big (But Fake) Views
Types
- Feature: Large list of new libraries and improvements to existing type libraries across a number of architectures and platforms
- Improvement: Arrays now honor struct alignment
- Improvement: Proper simplification of mangled type libraries
- Improvement: Added method for
.syscallfield in function types - Improvement: Type parser improvement
- Fix: Errors about type libraries not loading
- Fix: .altname fails type library round trip
Plugins/Plugin Manager
- Feature: A huge number of updates have happened to both official and community plugins. Make sure to check out both repositories and see if there’s new ones you’ve missed!
- Improvement: PluginManager downloads now obey network proxy settings
- Improvement: PluginManager font sizes now scale with the application font
- Fix: ALREADY CLAIMED! Thanks for reading this far!
Look, there’s already about a half a bazillion lines in this post, is anyone actually going to read this far? The first person that does, email IFoundIt at Vector 35 dot com and we’ll send you something nice for your diligence.
Enterprise
- Feature: Client updates can be downloaded and hosted offline from the Enterprise server
- Feature: Groups are now supported by the Enterprise server and client
- Feature: Uploaded project files now support Open with Options
- Improvement: Analysis caches are now synced to the server in addition to databases (major improvement for large files)
- Improvement: Single Sign-On (SSO) with OAuth2/OIDC has been re-written and now properly supports more endpoints
- Improvement: Storage of credentials and licenses has been re-written to improve support on Linux
- Improvement: Chat has moved to the new Global Area and handles disconnection and reconnection more gracefully
- Note: Enterprise 3.0 servers and clients are incompatible with earlier 2.5 servers/clients due to a protocol version change
Misc
- Feature: The
BN_USER_DIRECTORYenvironment variable can now be used to quickly switch between sets of plugins, settings, themes, etc - Feature: Development user documentation is now online and tracks the latest development release
- Improvement: User documentation on ILs was missing some of the more [esoteric instructions]—they’re still esoteric, but they’re now properly listed at least
- Improvement: Minimized the total number of python API documentation files. This can dramatically improve the update time as the update infrastructure scales poorly with a large number of small files.
- Improvement: Documentation [2687]
- Fix: A number of memory leaks identified and resolved (not all had issues created)
- Fix: A large number of stability fixes
And of course you can view all the other issues, fixes, and features that didn’t make this list at: https://github.com/Vector35/binaryninja-api/milestone/10?closed=1.