Are you ready for the next stable Binary Ninja release? 3.1 is live today and contains many major improvements:
- Better Performance
- Non-Commercial Multithreading
- Clang Type Parser
- New Windows Types
- Native Debugger
- Logging System
- Enterprise API
If you were expecting 3.1 to be the “Windows” update, we were too as that was the original plan! However, given the scope of major new features, we split the original release plan into two halves. While many Windows improvements are indeed coming in 3.1, others are now planned for 3.2, the new “Windows” release.
Major Changes
Performance
The headlining feature of 3.1 (and the name of the release) is “Performance”. Of course, there’s a lot of ways you can measure performance and we’ve improved most of them in this release! Let’s break down the improvements into the following categories:
- Memory usage
- Analysis times
- Database save/load speed
Memory Usage
Memory usage has been significantly improved in 3.1, especially with large binaries containing symbols. Our test binary is a build of Linux Chrome with full symbols. This binary is a gigantic 1.37GB in size. In previous versions of Binary Ninja, this would be nearly impossible to analyze on any normal development workstation and would likely require server-class hardware to analyze. In 3.1, a typical high-end development workstation can now analyze this binary with relative ease across all the platforms we support.
Below is the maximum memory usage after initial analysis of Chrome (all memory usage data was generated on Linux):
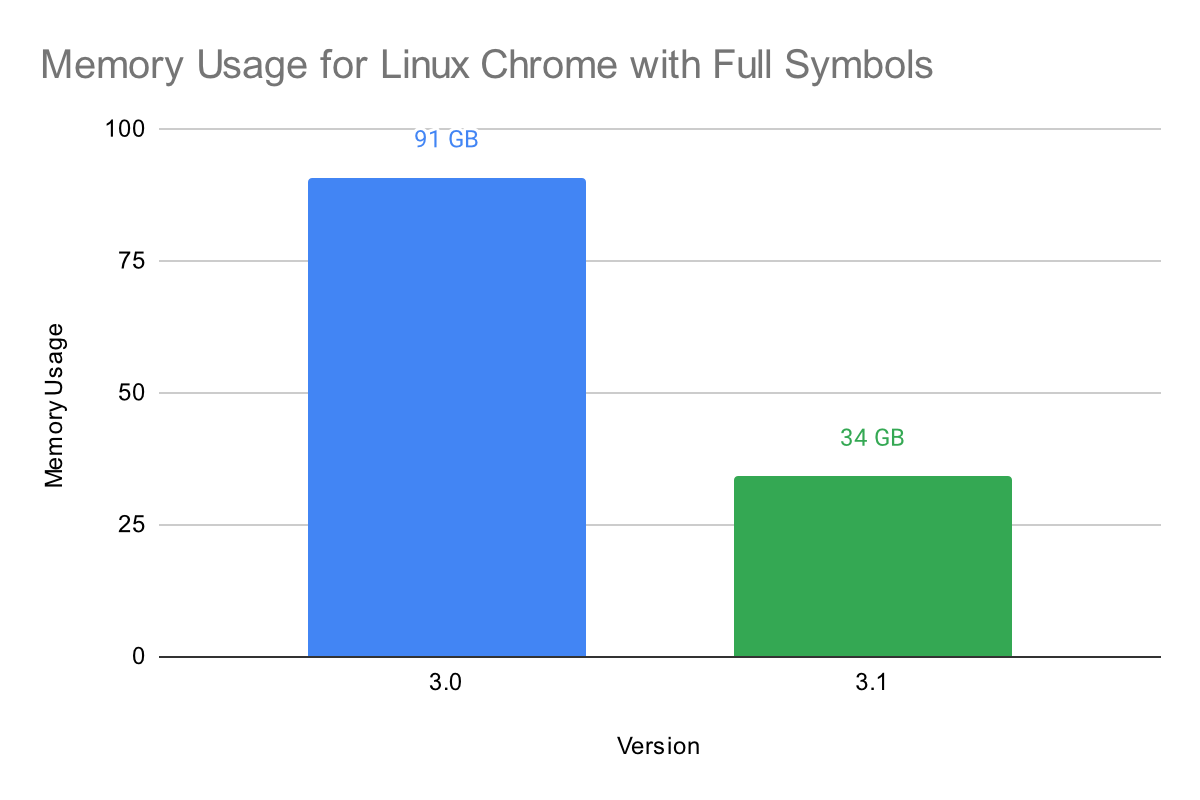
Improvements to memory usage are still significant in large binaries that do not have symbols. We used the x86-64 macOS version of XUL, the core library of Mozilla Firefox, to test this. It weighs in at a large 129.9MB and would also cause a very large amount of memory usage in previous versions of Binary Ninja. In 3.1, memory usage is much less, as shown in the chart below:
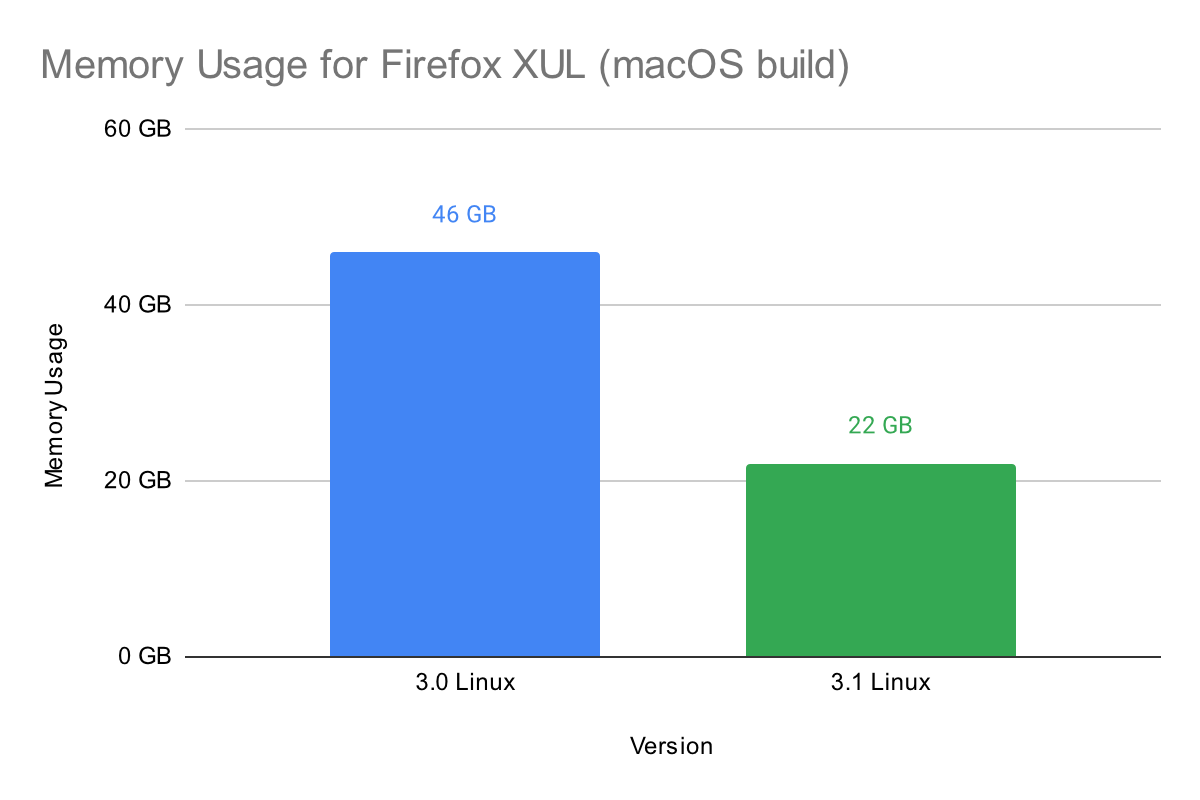
Analysis Times
Analysis performance has also been improved significantly in 3.1, especially on systems with a large number of cores. As an example, we’ll look at performance on a 128-core AMD EPYC 7H12 system running Ubuntu 20.04. Below is a chart showing the initial analysis time for a Linux build of Chrome:
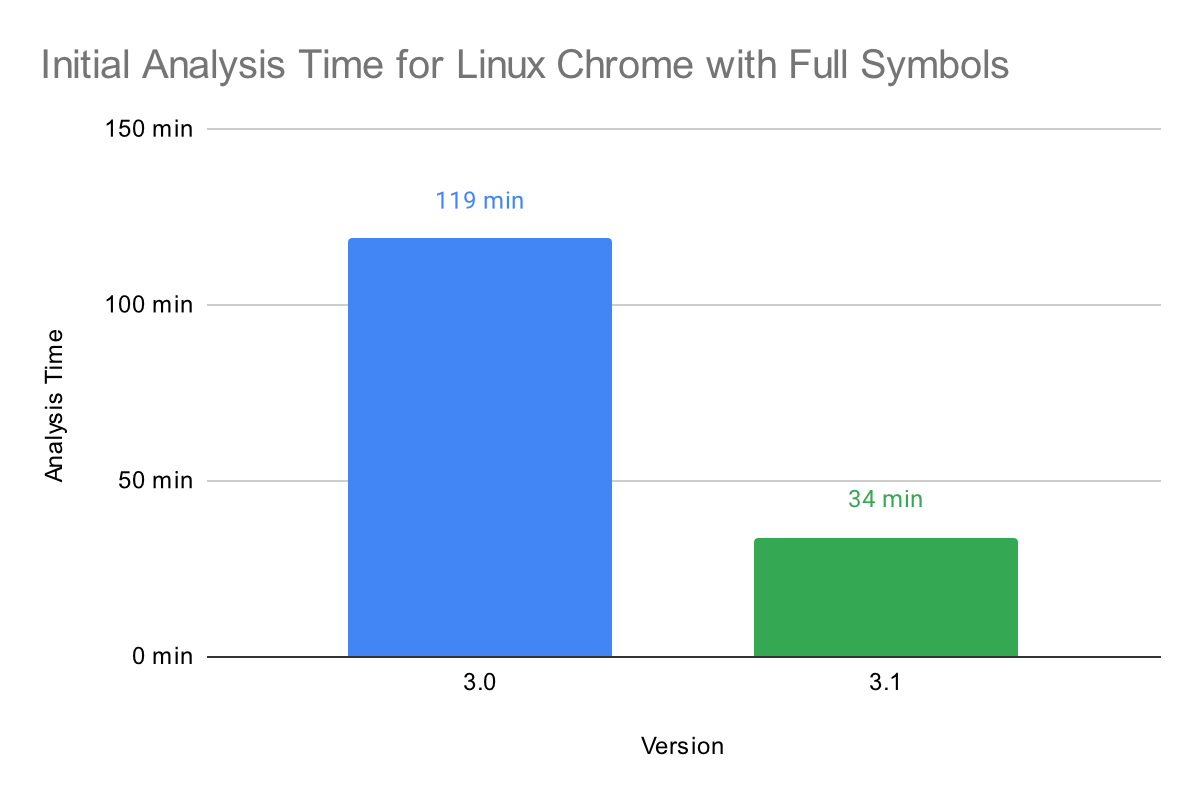
Performance has been improved on all platforms that we support. Cross platform performance was measured by analyzing the x86-64 macOS version of XUL. Tests for Linux and Windows were performed on an AMD Ryzen Threadripper 3970x with 64GB of RAM. Tests for macOS were performed on an Apple M1 Max with 64GB of RAM. Below is a chart showing the performance improvements for each platform:
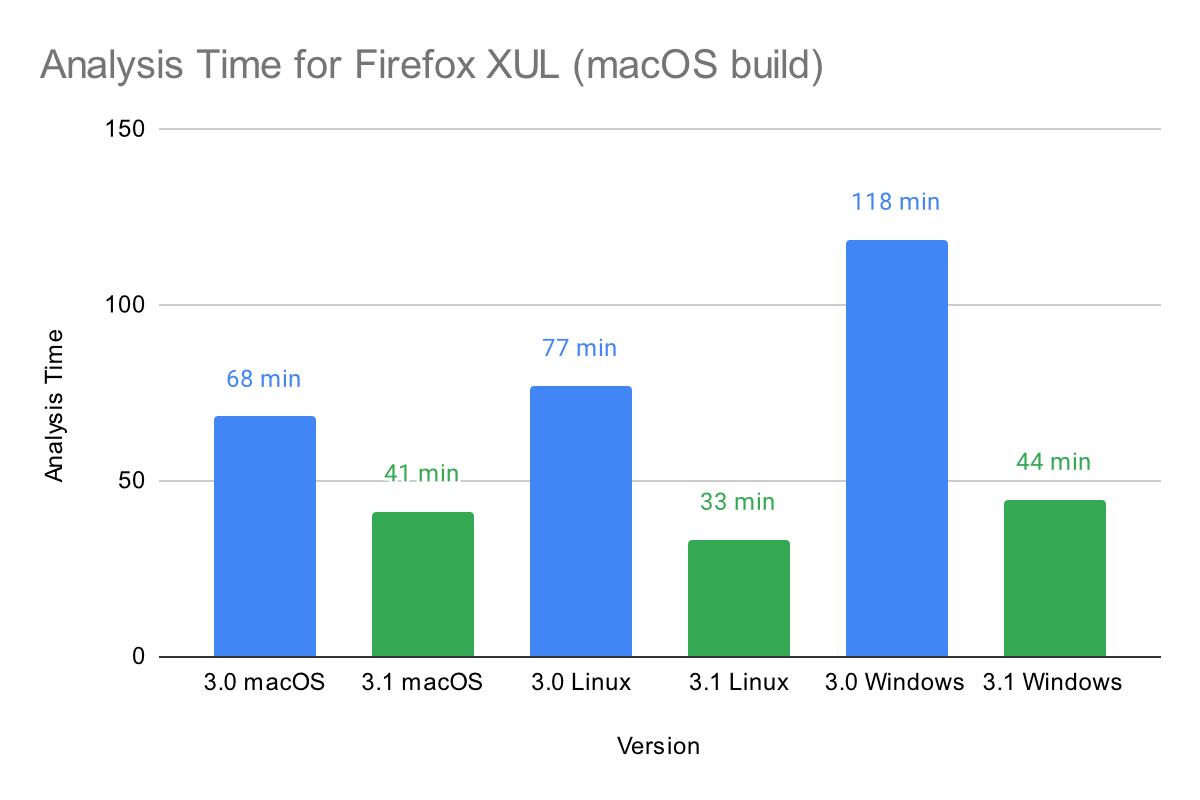
Windows performance is especially improved and is now much closer to parity with the other platforms.
Database Save/Load Speed
Loading an existing analysis database has been optimized in 3.1, including support for multithreaded loading. Below is a chart of the time to load a database for the x86-64 macOS version of XUL:
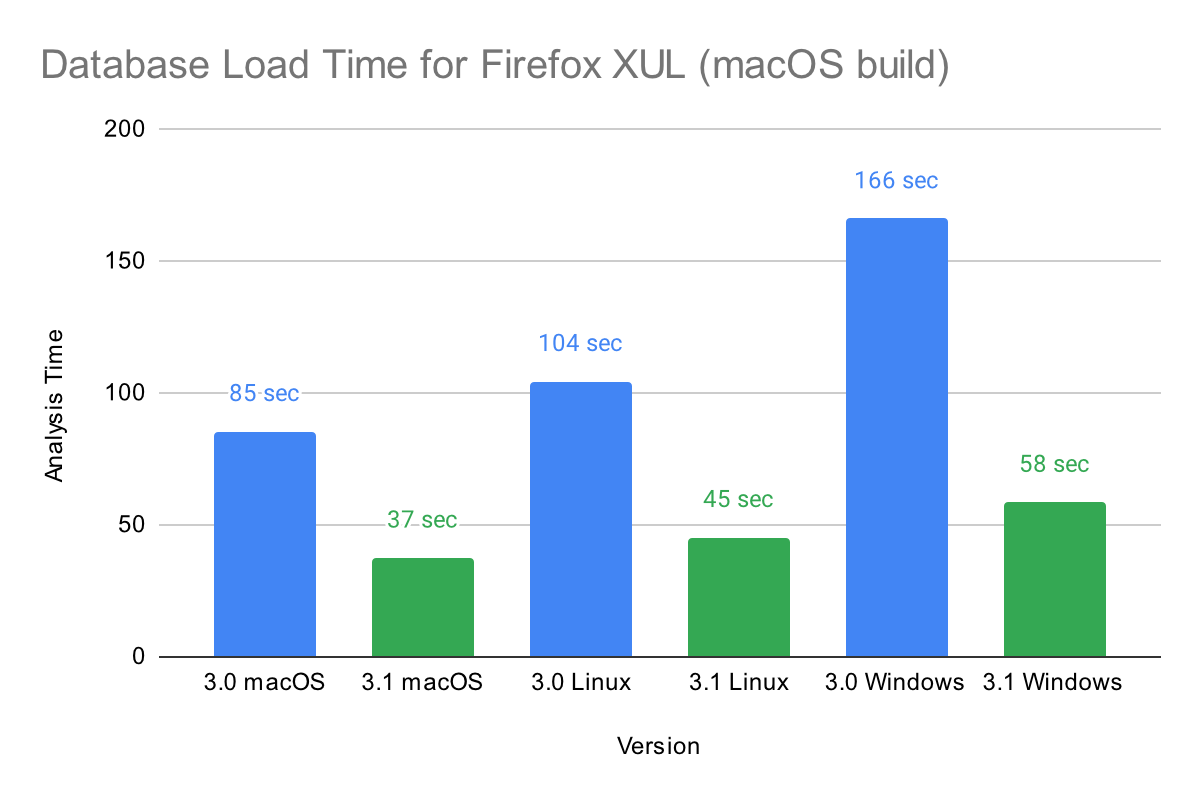
Database saving is also multithreaded in 3.1. The improvements are shown in the chart below:

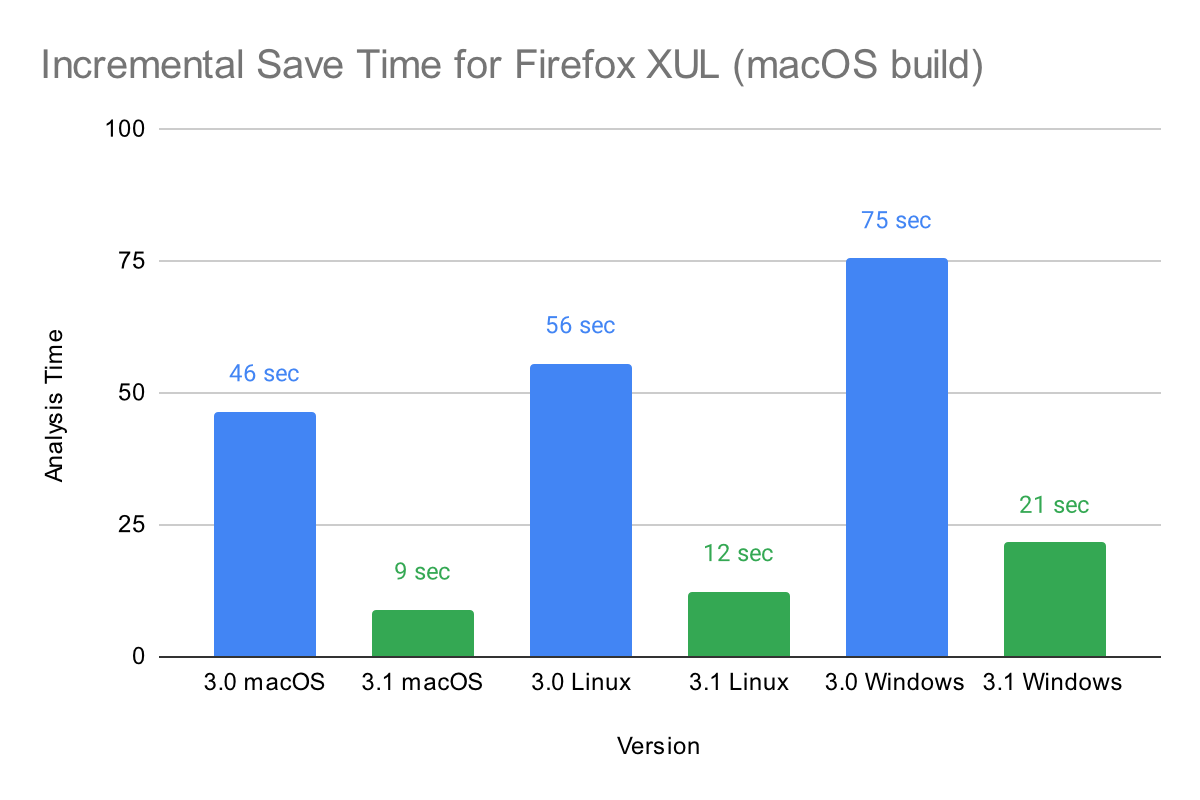
New in 3.1 is support for incremental saves. If you save a database after a small number of changes, it will reuse data that is already present in the database, dramatically improving performance. Below is a chart showing the performance of incremental saves:
Non-Commercial Multithreading
Some of the save and load speedups described in the previous section were achieved by increasing the parallelization of those processes. Of course, our non-commercial licenses were not multi-threaded before this release and wouldn’t have been able to benefit from these changes. So, we thought it was only fitting that we also release multi-threading for non-commercial licenses!

Thus, we continue our trend of adding features originally only in the commercial edition to the non-commercial edition. The two remaining distinctions are that only the commercial license allows use for commercial purposes, and of course a true “headless” feature. Headless is what allows you to, for example, write batch-processing scripts that run entirely independently of the UI:
>>> import glob
>>> import binaryninja
>>> for file in glob.glob("*.exe"):
... with binaryninja.load(file) as bv:
... for sym in bv.symbols:
... if "kernel" in sym.lower():
... print(bv.file.filename, sym)
...
You can still run the same APIs from the UI! So it is possible to run the same code on a non-commercial license, it just has to be run from a UI plugin or from the interactive scripting console.
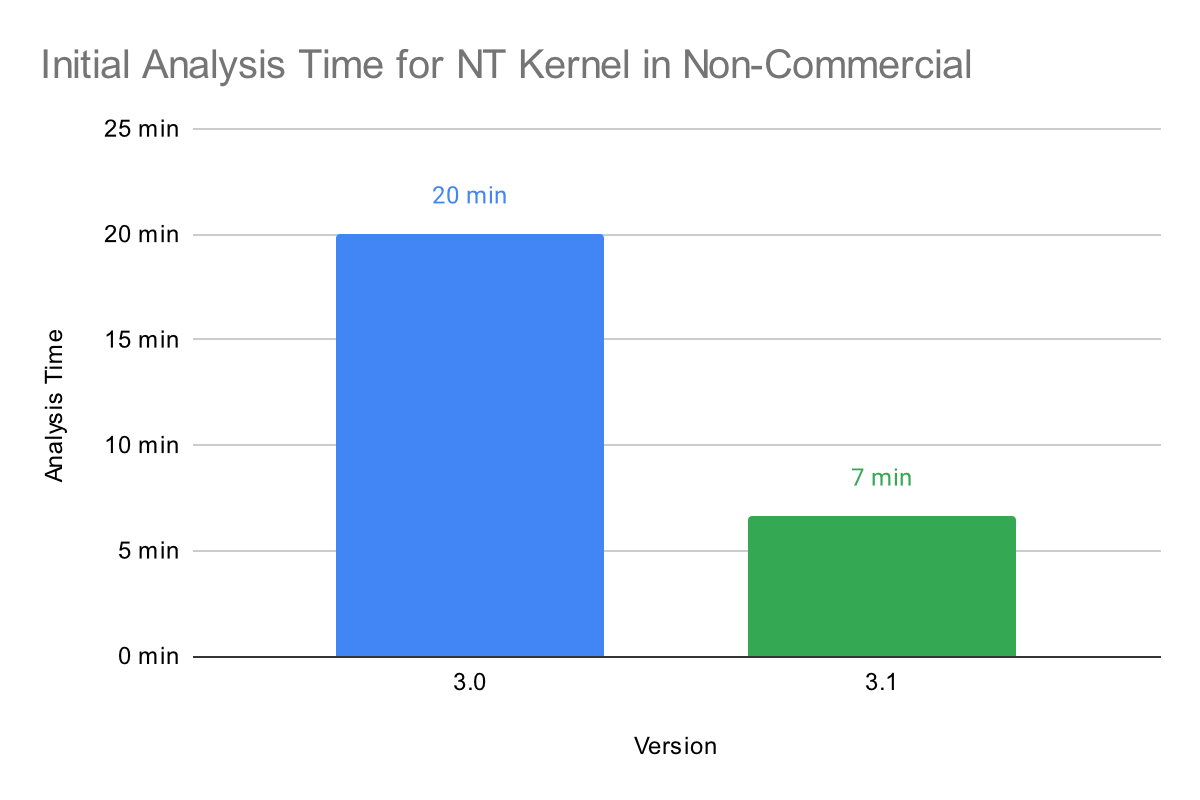
The increased performance from multithreading is significant even on hardware that does not have a large number of cores. As an example, the chart below shows the increase in performance on an M1 MacBook Air, an entry-level Apple laptop that is a popular choice among college students:
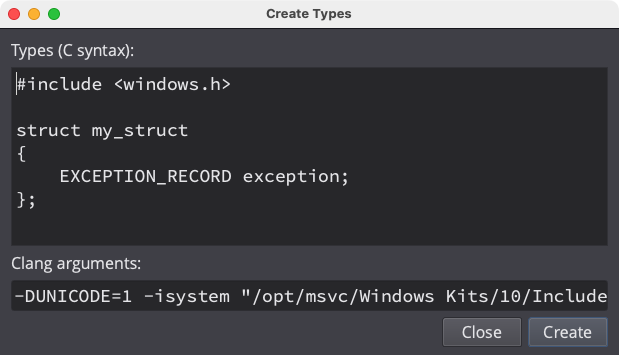
Clang Type Parser
In what is almost certainly one of our highest issues-closed-per-commit ratios in quite some time, the addition of the Clang type parser opens up many new possibilities for Binary Ninja. Instead of using the prior core parser based on scc, the new clang system is able to handle far more files and of course benefits from an extremely healthy upstream ecosystem.
First, a quick rundown of closed issues:
- Parent issue describing features (#3007)
- Better support for C++ symbols (#1632)
- Support for empty structs (#1633)
- Preprocessor support (#1655)
- Support syntax for typedefs and pointer typedefs in one line (#2088)
- Functions returning function pointers (#2294)
- Fix forward declaration structs (#2431)
- Support for
__convention("name")in a function type (#2518) - Support register specifiers when defining structure types (#2994)
There are likely many more fixes and improvements introduced by Clang as well, but integrating such a massive change isn’t without potential risks, too. Given that, the new type parser is disabled by default on the 3.1 stable. If you wish to try it out, head to settings and switch “Type Parser” to ClangTypeParser. Alternatively, we will immediately be re-enabling it for dev branch customers as soon as the 3.1 stable ships, so you can also just switch branches.
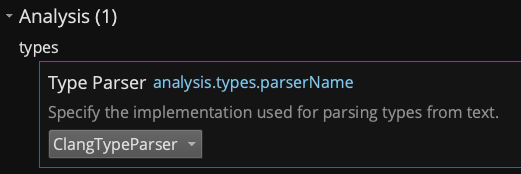
Added Types
Even though 3.2 is now officially the “Windows” release, one of the most important improvements for better support of Windows binaries has landed on 3.1 in the form of vastly improved Windows type libraries. We added type information for over 58k functions and 26k types across 3 Windows architectures! This results in dramatically better analysis for almost all Windows PE files. Check out some of the results below:
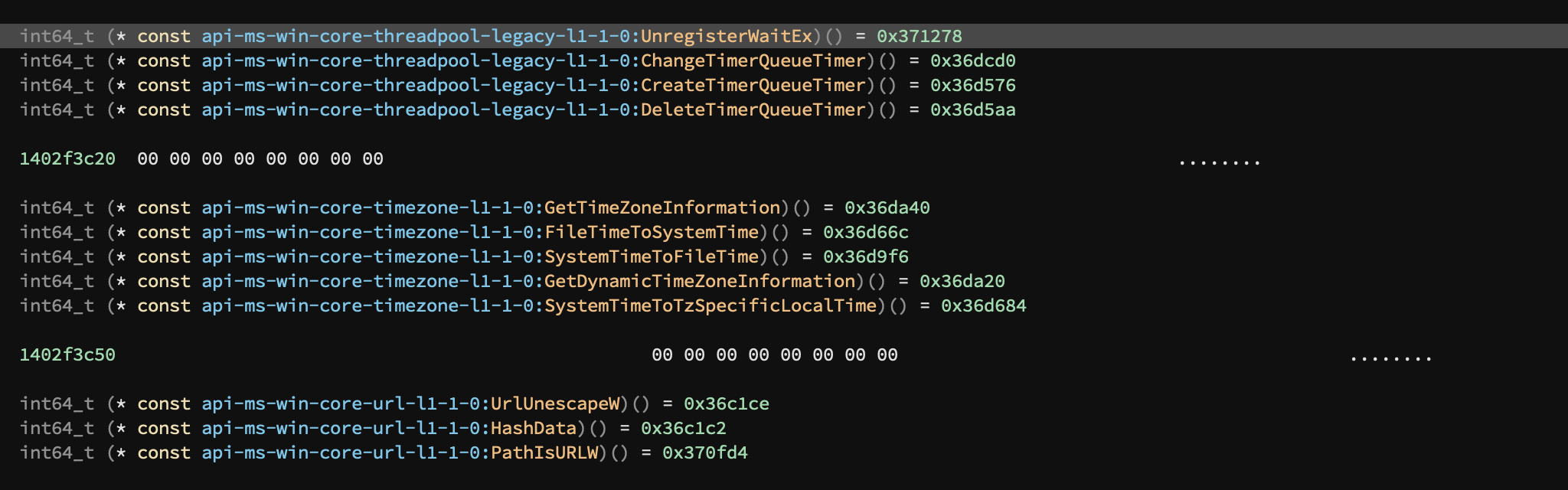
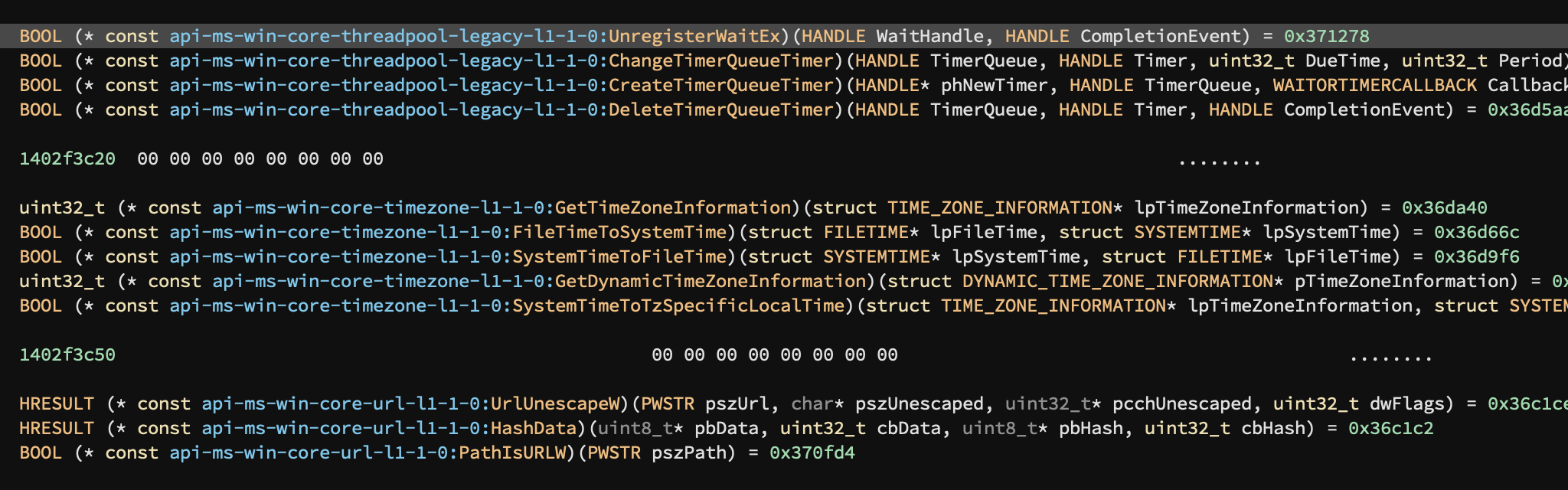
In addition to those those auto-generated type libraries (thanks to dfraze and several others [1, 2, 3] for inspiration that led to our solution), a new msvcrt was also added.
There’s still more types planned for 3.2 but this definitely represents a huge increase in the total coverage of windows types from 3.0!
Native Debugger
The new native debugger is live in 3.1! It has not reached its final form though so we’re still calling it a beta and is it not enabled by default. In particular, we plan to make some UI changes still and there are a number of issues slated for the next stable. That said, to check it out, just searching settings for “debugger” and enable the plugin to give it a try.
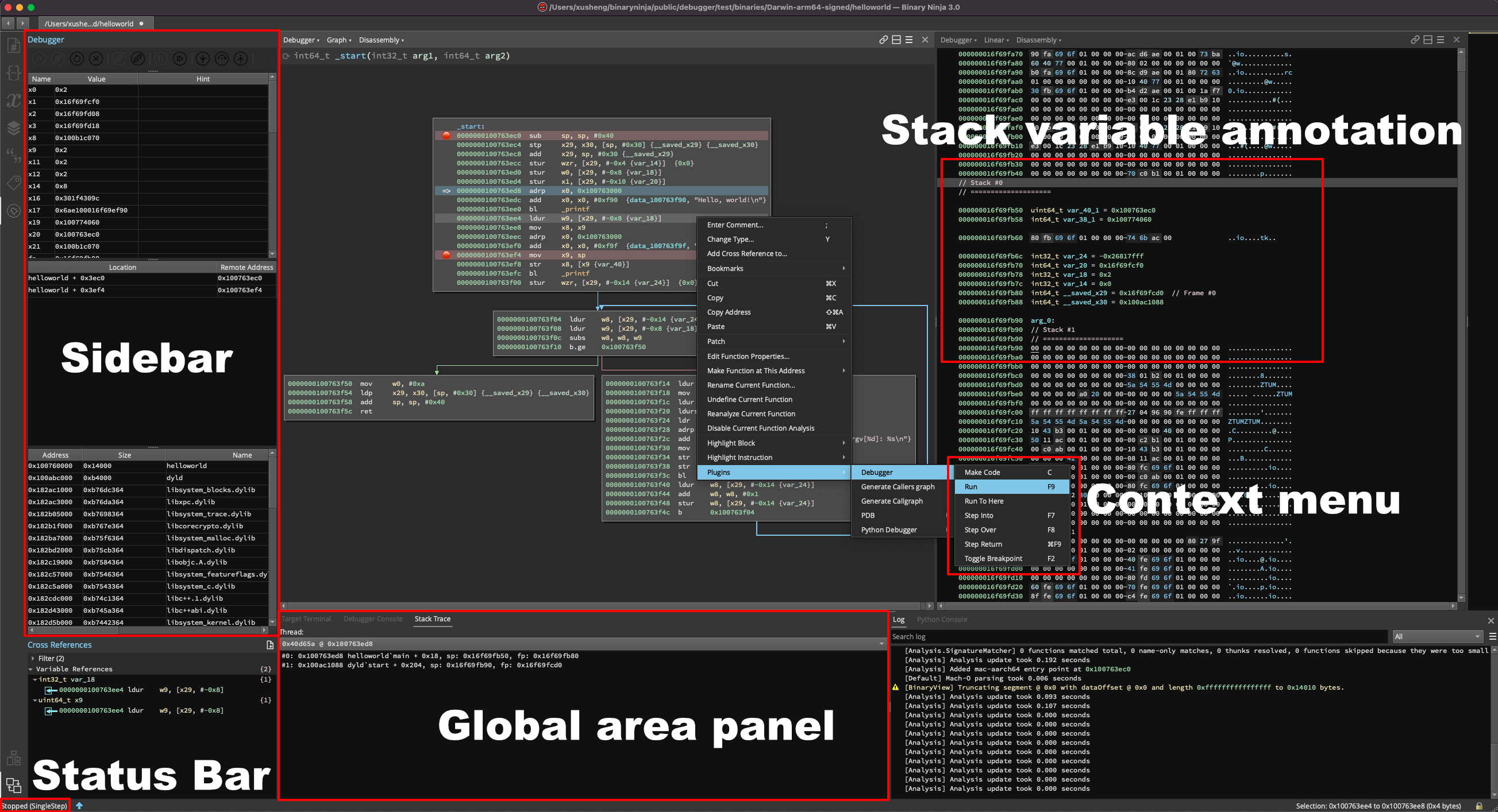
Go check out the full documentation for much more detail about the debugger, but here’s a quick overview of some of the highlights:
- All the typical execution control UI elements
- Register window showing hints of strings or pointers when they’re stored in registers (support for variables forthcoming!)
- Breakpoint view for managing existing breakpoints or adding new ones
- Modules view showing the address, size, name, and path information of the target’s modules
- Integrated target terminal for interacting with the application being debugged
- Integrated debugging console that supports native backend commands (LLDB or WinDbg syntax depending on the OS)
- Stack trace view that can also switch between threads
And of course the debugger (like most of our official plugins–even ones shipped and enabled by default) is open source, available under an Apache 2.0 license.
New Logging System
The Log area got a big visual overhaul:
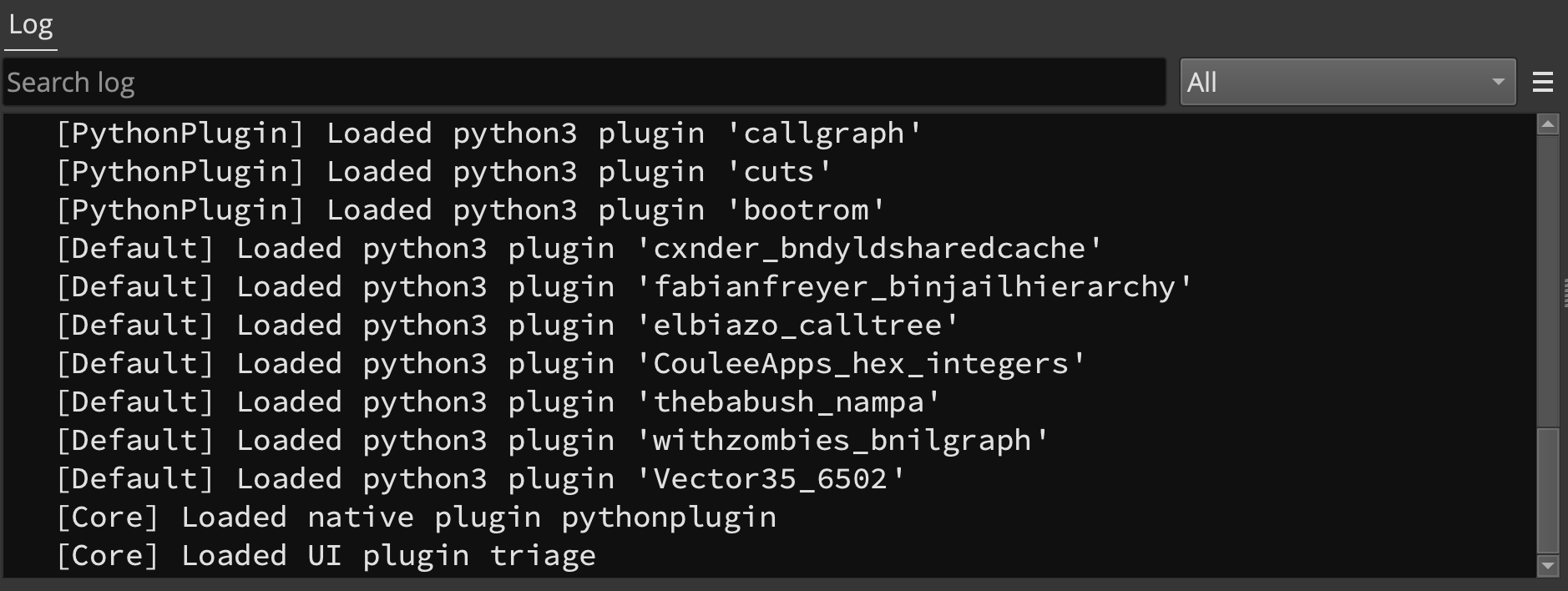
There’s a number of obvious UI improvements:
- Search log messages
- Select a logger to filter messages from different sources
- Change the log level from the UI
- Select log scope (all tabs, current tab, current tab and global, global only)
It might not be immediately obvious but the backend logging system also got an upgrade. This not only makes the log area more performant but allows for plugins to take advantage of those above new UI features (1, 2, 3).
Enterprise API
The initial release of Binary Ninja Enterprise included the use of all our existing APIs, plus an extra Enterprise C++ API. What was missing was an Enterprise Python API; unfortunate, because that’s how most of our users prefer to interact with Binary Ninja. So, in 3.1, we’ve added a Python API to Enterprise to fill the void.
This new API lets you perform a number of Enterprise-specific actions straight from Python, including:
- Connecting to the server
- Managing license checkouts
- Managing users, groups, projects, project files and permissions
- Uploading, downloading, syncing, and merging databases and snapshots
We’ve been using this internally to have a headless Enterprise client perform scripted actions like batch-uploading files or running analysis across all files in a project and it’s been working great! (It’s also uncovered a few bugs we’ve fixed in this release, too.) It’s our first (small) step toward making Enterprise a fantastic choice for deploying automated analysis with Binary Ninja. We hope to follow this up with even more improvements for automated workflows in 3.2.
Here’s a small example demonstrating connecting, checking out a license, and downloading all files from an Enterprise server:
from binaryninja import enterprise, collaboration
with enterprise.LicenseCheckout():
remote = collaboration.enterprise_remote()
if not remote.is_connected:
remote.connect()
# Pull every file from every project
for project in remote.projects:
for file in project.files:
bndb_path = file.default_bndb_path
print(f"{project.name}/{file.name} BNDB at {bndb_path}")
metadata = file.download_to_bndb(bndb_path)
for v in metadata.existing_views:
if v != 'Raw':
bv = metadata.get_view_of_type(v)
print(f"{project.name}/{file.name} {v} Entrypoint @ 0x{bv.entry_point:08x}")
Other Updates
Platform Support
- Added: Ubuntu 22.04 x64 is now officially supported
- Dropped: Ubuntu 18.04 x64 is no longer officially supported
Please note that, since Ubuntu 18.04 has been dropped, we have also increased the minimum required version of Python for the API to Python 3.8.
UI Updates
- Feature: Middle-click and shift-middle-click will open new panes and new tabs (respectively) and can be configured
- Feature: “Address Indicator” has been simplified and also now supports changing the default display format
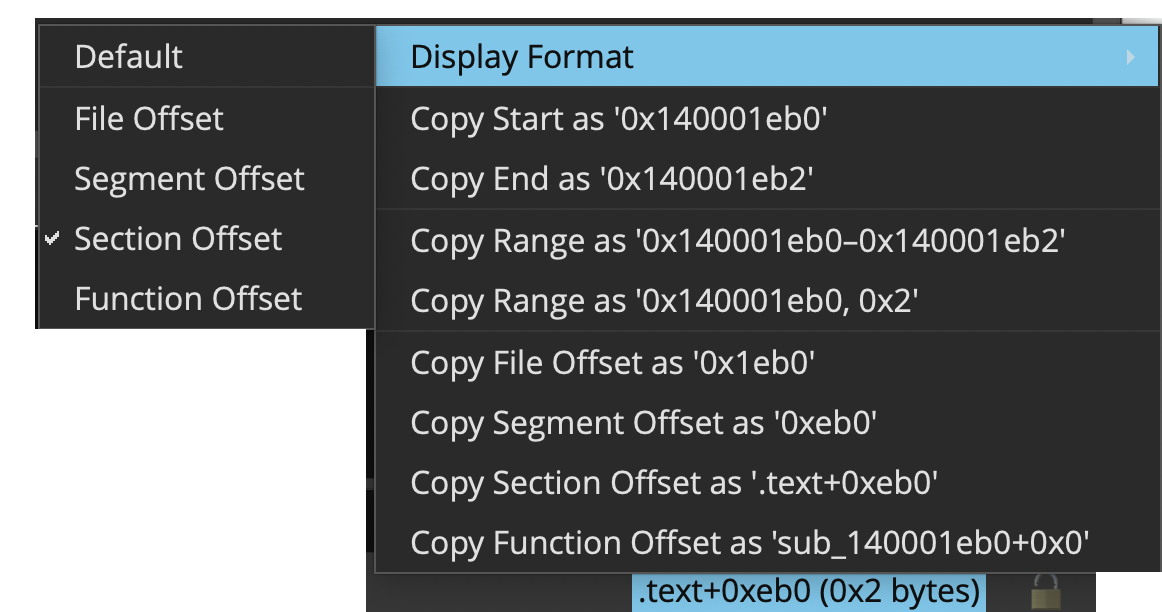
- Feature: If attempting to name a duplicate symbol (which is allowed!), the UI will warn against doing so
- Feature: Panes can be dragged into new windows
- Feature: If a
mainfunction exists, automatically navigate there (can be configured viaui.firstNavigatesettings) - Improvement:
<tab>hotkey now alternates between disassembly and the current view - Improvement: Tags/Bookmarks context menu cleanup
- Improvement: More consistent values in the variables view
- Improvement: Better naming of graph and linear views
- Fix: Changing a type with the
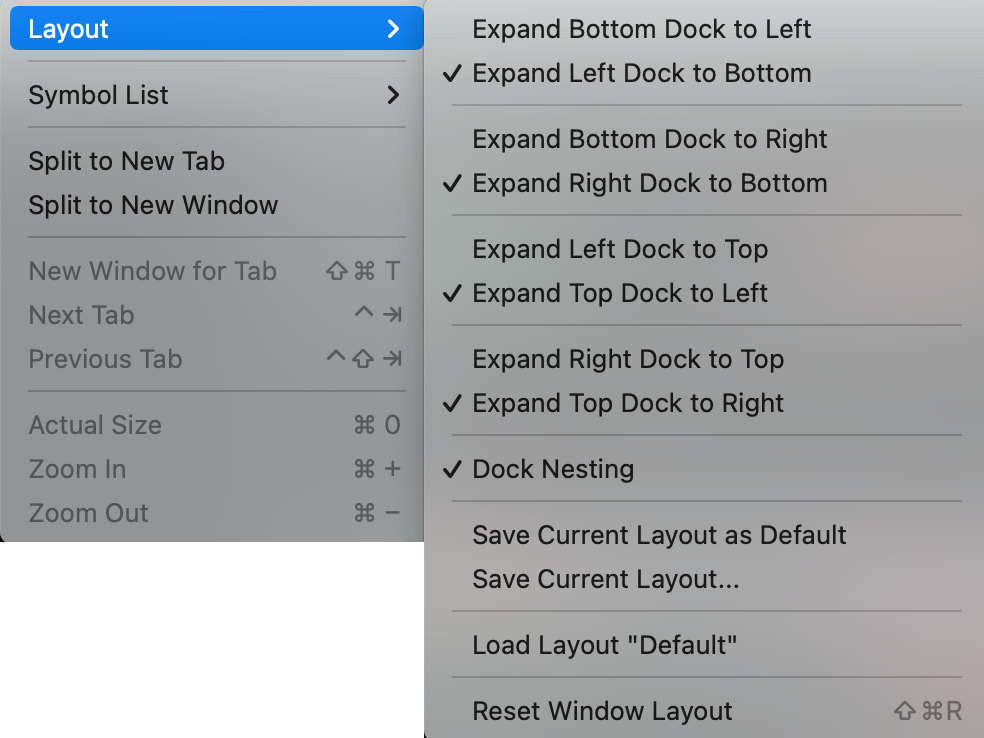
yhotkey will default to an existing type if one exists in linear view - Fix: Save/Restore window layout functionality has been restored (pun actually not intended) and can also save a default layout
- Fix:
Find (Text)could reset LinearView settings - Fix:
Find Allcould previously fail to in fact, “Find All” - Fix: Remove a partially obscured UI artifact
- Fix: Main window no longer closes when canceling an external link warning dialog
- Fix: Eliminated several bugs regarding view changing and syncing (1, 2, 3, 4)
- Fix: Work-around a QT crash
Binary Views
- Improvement: Better validation of Mach-O LC_FUNCTION_START records
Analysis
- Feature: Several constants such as
maxSymbolWidthanddisassemblyWidthare now settings - Improvement: Improved jump table decompilation
- Improvement: Better limits on invalid jump table creation
- Fix: Improved SBB flag tracking
- Fix: BNDBs no longer grow in size when saving if nothing has changed
- Fix:
ROLcorrectly handled in internal constant data flow analysis - Fix: Some shift instructions were lifted improperly
API
- Feature: Python 3.10 support
- Feature: HighLevelILFunction::GenerateSSAForm now exposed in the API
- Improvement: Many improvements to type annotations (1, 2)
- Improvement: Automatically locate MacPorts installed python versions
- Improvement: Plugins can now throw exceptions during callbacks
- Fix:
MediumLevelILVarPhi.vars_writtenproperty now works - Fix:
open_viewAPI properly sets FileMetadata.filename - Fix:
DebugInfo.add_functionno longer errors
Types
- Feature: Type names can now be escaped with backticks, allowing for many previously invalid symbols and better round-tripping support
- Fix: Some structures were packed incorrectly
- Fix: WCHAR was too pointy
Plugins/Plugin Manager
- Improvement: The plugin list sort method is now case insensitive
- Note: Sorry if you were expecting another prize, if we decide to hide another easter egg in a changelog we’ll want you to work for it a bit more.
Enterprise
- Feature: LDAP now a source of Single Sign-On (SSO) user authentication
- Feature: Support for Webhooks to provide easy integration with other services such as chat environments
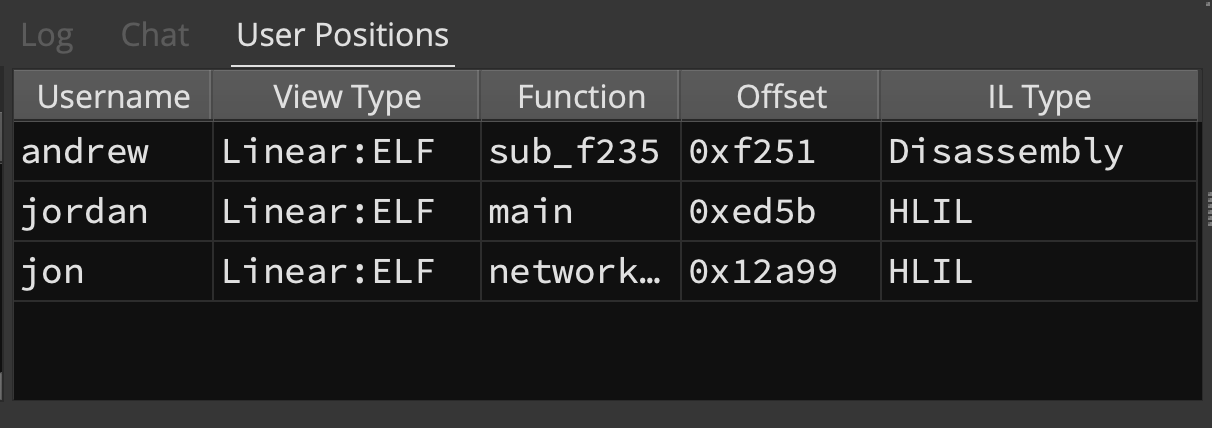
- Feature: New user position tracking window
- Feature: License reservation metrics display in admin interface
- Feature: Enterprise Server now runs on Windows
- Feature: Multiple new CLI switches for the server management binary supporting additional deployment variations
- Feature: “Getting Started” documentation pages for setting up Single Sign-On (SSO) and local client updates
- Improvement: Active license reservation display is easier to understand
- Improvement: Network performance when pushing a new database and when synchronizing new snapshots
- Improvement: Network performance for projects with large numbers of files (>2000)
- Fix: Fixed multiple client crashes related to UI and networking
- Fix: Added a missing error message when trying to delete a project with files
- Fix: Fixed an issue where short-duration licenses were not cached on disk
- Fix: Fixed a timestamp issue preventing forced license expiration from working properly
- Fix: Fixed an issue where Azure Active Directory would not show up as a valid login option despite it being enabled
- Fix: Fixed an issue with user and group filtering that prevented managing permissions with very short or long usernames
- Fix: Server management binary on macOS now includes working x64 support
Architectures
Thanks to our open source architectures, you can check out any of the improvements to each architecture during the last release in their respective repositories:
- arm64
- armv7
- mips
- Improvement: Ability to assemble PAC instructions
Note that other architectures are included with Binary Ninja but had no changes during this release and are not listed above.
Misc
- Feature: A new setting,
analysis.database.purgeSnapshotscan be enabled to automatically purge snapshot information when saving a database - Improvement: The
binaryninja:URL handler can now open BNDBs - Improvement: Several improvements and fixes to PDB loading (1, 2, 3)
- Improvement: Now gracefully handles multiple attempts to access the same database
- Fix:
BN_USER_DIRECTORYis now a complete override for locating the user folder - Fix: The logic for the silent option on the headless install script was backward
And of course all the usual “many miscellaneous crashes and fixes” not explicitly listed here. Check them out in our full milestone list: https://github.com/Vector35/binaryninja-api/milestone/11?closed=1.